Wan2.2 ComfyUI Workflow Guide - Official, Kijai & GGUF
Complete Wan2.2 video generation tutorial for ComfyUI: official native workflow, Kijai WanVideoWrapper, GGUF quantized version, and Lightx2v fast generation. Step-by-step setup and usage guide.
Tutorial Overview
This tutorial will comprehensively introduce various implementation methods and usage of the Wan2.2 video generation model in ComfyUI. Wan2.2 is a new generation of multimodal generation model launched by Alibaba Cloud, adopting an innovative MoE (Mixture of Experts) architecture with core features such as film-level aesthetic control, large-scale complex motion generation, and precise semantic compliance.
Versions and Content Covered in This Tutorial
Completed Versions:
- ✅ ComfyUI Official Native Version - Complete workflow provided by ComfyOrg official
- ✅ Wan2.2 5B Hybrid Version - Lightweight model supporting text-to-video and image-to-video
- ✅ Wan2.2 14B Text-to-Video Version - High-quality text-to-video generation
- ✅ Wan2.2 14B Image-to-Video Version - Static image to dynamic video
- ✅ Wan2.2 14B First-Last Frame Video Generation - Video generation based on start and end frames
Versions in Preparation:
- 🔄 Kijai WanVideoWrapper Version
- 🔄 GGUF Quantized Version - Optimized version for low-configuration devices
- 🔄 Lightx2v 4steps LoRA - Fast generation optimization solution
About Wan2.2 Video Generation Model
Wan2.2 adopts an innovative MoE (Mixture of Experts) architecture, composed of high-noise expert models and low-noise expert models, which can divide expert models according to denoising time steps to generate higher quality video content.
Core Advantages:
- Film-Level Aesthetic Control: Professional lens language, supporting multi-dimensional visual control of lighting, color, composition, etc.
- Large-Scale Complex Motion: Smoothly reproduces various complex motions, strengthening motion controllability and naturalness
- Precise Semantic Compliance: Complex scene understanding, multi-object generation, better restoration of creative intent
- Efficient Compression Technology: 5B version high compression ratio VAE, memory optimization, supporting hybrid training
The Wan2.2 series models are based on the Apache2.0 open source license, supporting commercial use. The Apache2.0 license allows you to freely use, modify and distribute these models, including commercial purposes, as long as you retain the original copyright notice and license text.
Wan2.2 Open Source Model Version Overview
| Model Type | Model Name | Parameters | Main Function | Model Repository |
|---|---|---|---|---|
| Hybrid Model | Wan2.2-TI2V-5B | 5B | Supports text-to-video and image-to-video hybrid version, a single model meets two core task requirements | 🤗 Wan2.2-TI2V-5B |
| Image-to-Video | Wan2.2-I2V-A14B | 14B | Converts static images to dynamic videos, maintaining content consistency and smooth dynamic processes | 🤗 Wan2.2-I2V-A14B |
| Text-to-Video | Wan2.2-T2V-A14B | 14B | Generates high-quality videos from text descriptions, with film-level aesthetic control and precise semantic compliance | 🤗 Wan2.2-T2V-A14B |
Wan2.2 Prompt Guide - Detailed prompt writing guide provided by Wan
ComfyUI Official Resources
ComfyOrg Official Live Broadcast Replay
ComfyOrg's YouTube has detailed explanations of using Wan2.2 in ComfyUI:
Wan2.2 ComfyUI Official Native Version Workflow Usage Guide
Version Description
The ComfyUI official native version is provided by the ComfyOrg team, using 🤗 Comfy-Org/Wan_2.2_ComfyUI_Repackaged repackaged model files to ensure optimal compatibility with ComfyUI.
1. Wan2.2 TI2V 5B Hybrid Version Workflow
Workflow Acquisition Method
Please update your ComfyUI to the latest version, and find "Wan2.2 5B video generation" through the menu Workflow -> Browse Templates -> Video to load the workflow
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_5B_t2v.mp4"
<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/video_wan2_2_5B_ti2v.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>Download JSON Format Workflow
Model File Download
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ └───wan2.2_ti2v_5B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan2.2_vae.safetensorsDetailed Operation Steps
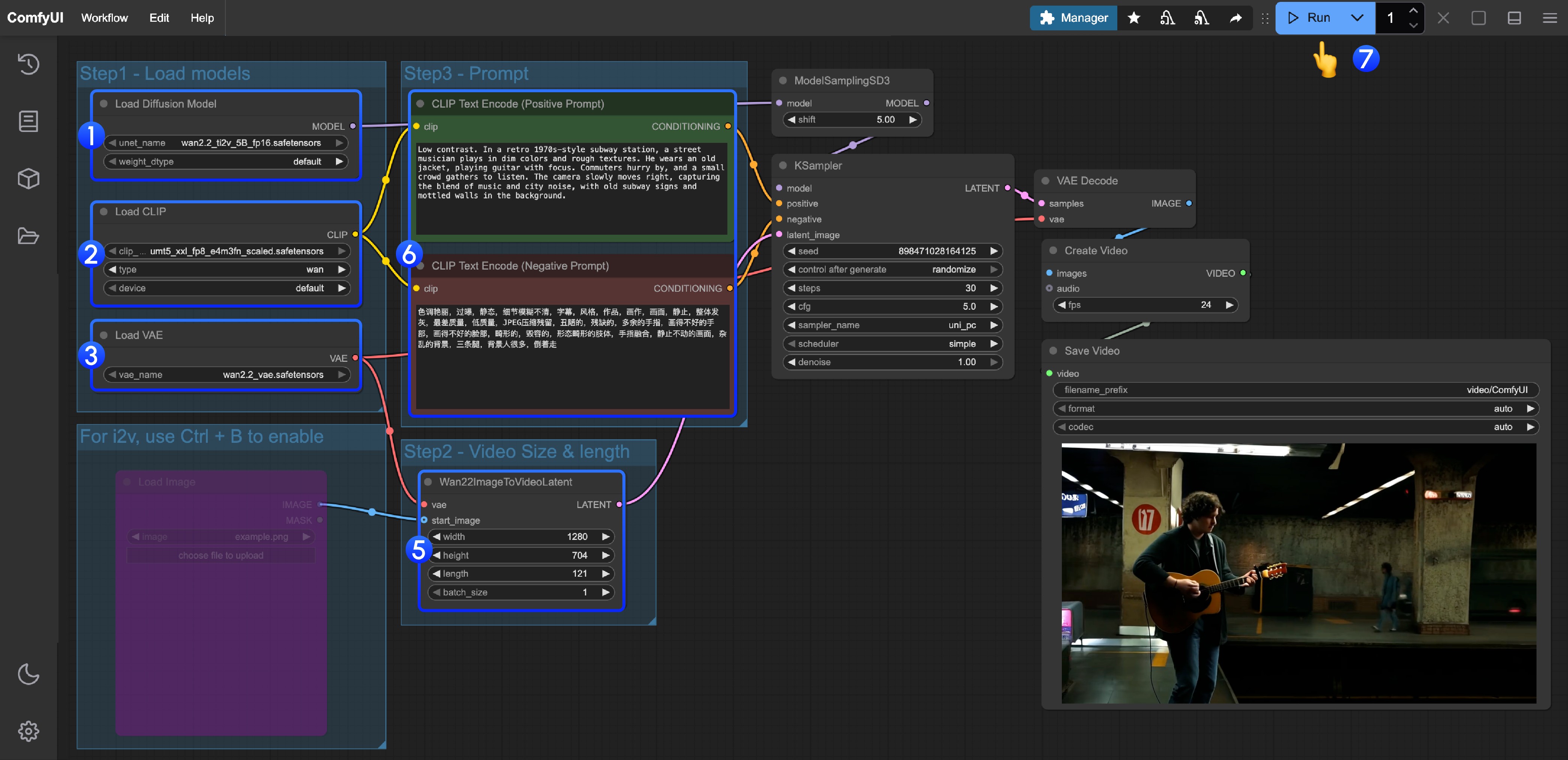
- Ensure the
Load Diffusion Modelnode loads thewan2.2_ti2v_5B_fp16.safetensorsmodel - Ensure the
Load CLIPnode loads theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure the
Load VAEnode loads thewan2.2_vae.safetensorsmodel - (Optional) If you need to perform image-to-video, you can use the shortcut Ctrl+B to enable the
Load imagenode to upload images - (Optional) In
Wan22ImageToVideoLatentyou can adjust the size settings and video total frame countlengthadjustment - (Optional) If you need to modify prompts (positive and negative), please modify them in the
CLIP Text Encodernode numbered5 - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute video generation
2. Wan2.2 14B T2V Text-to-Video Workflow
Workflow Acquisition Method
Please update your ComfyUI to the latest version, and find "Wan2.2 14B T2V" through the menu Workflow -> Browse Templates -> Video
Or update your ComfyUI to the latest version, then download the workflow below and drag it into ComfyUI to load the workflow
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_14B_t2v.mp4"
Model File Download
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensorsDetailed Operation Steps
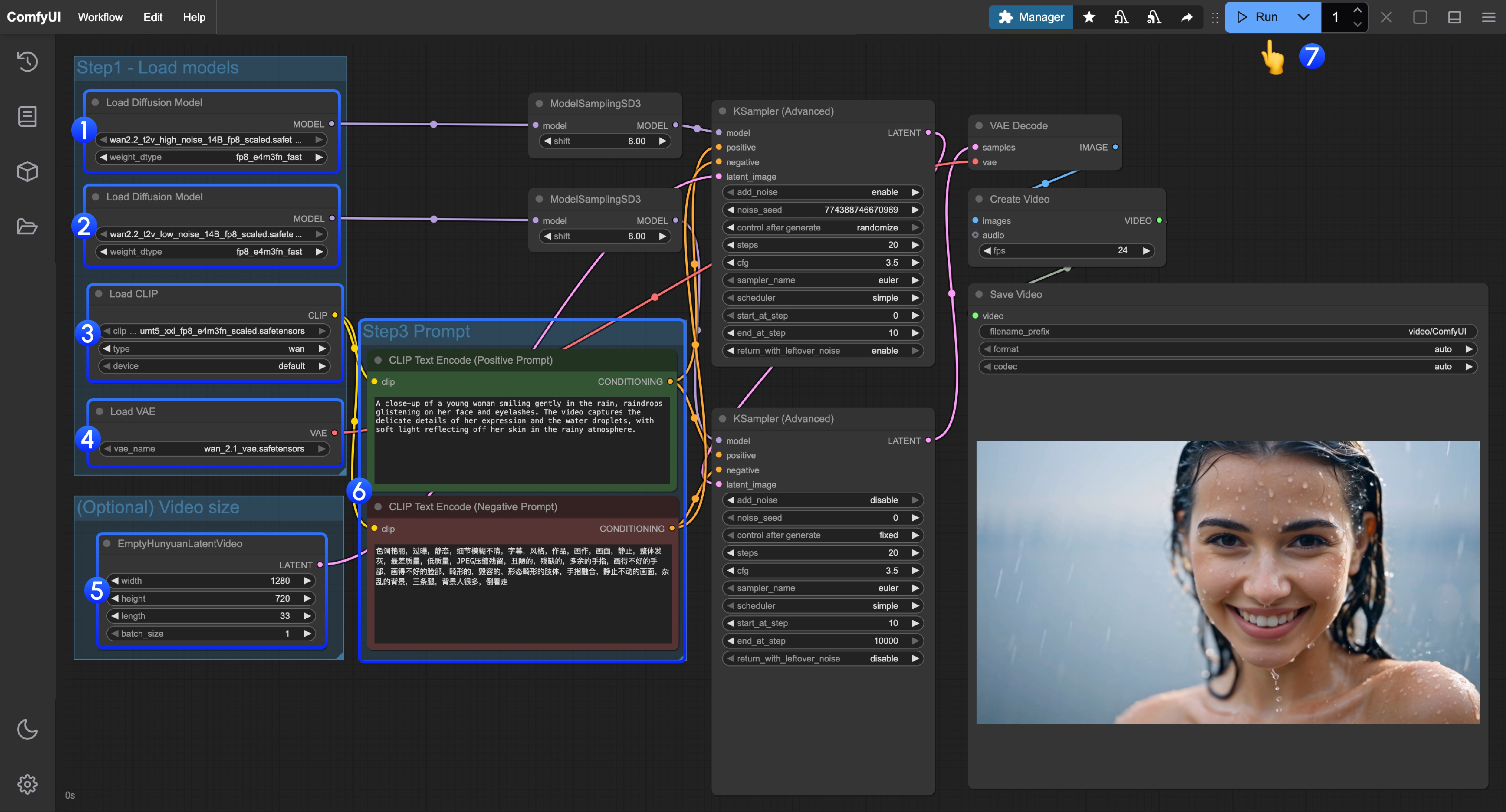
- Ensure the first
Load Diffusion Modelnode loads thewan2.2_t2v_high_noise_14B_fp8_scaled.safetensorsmodel - Ensure the second
Load Diffusion Modelnode loads thewan2.2_t2v_low_noise_14B_fp8_scaled.safetensorsmodel - Ensure the
Load CLIPnode loads theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure the
Load VAEnode loads thewan_2.1_vae.safetensorsmodel - (Optional) In
EmptyHunyuanLatentVideoyou can adjust the size settings and video total frame countlengthadjustment - If you need to modify prompts (positive and negative), please modify them in the
CLIP Text Encodernode numbered6 - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute video generation
3. Wan2.2 14B I2V Image-to-Video Workflow
Workflow Acquisition Method
Please update your ComfyUI to the latest version, and find "Wan2.2 14B I2V" through the menu Workflow -> Browse Templates -> Video to load the workflow
Or update your ComfyUI to the latest version, then download the workflow below and drag it into ComfyUI to load the workflow
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_14B_i2v.mp4"
You can use the following image as input

Model File Download
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_i2v_low_noise_14B_fp16.safetensors
│ │ └─── wan2.2_i2v_high_noise_14B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensorsDetailed Operation Steps
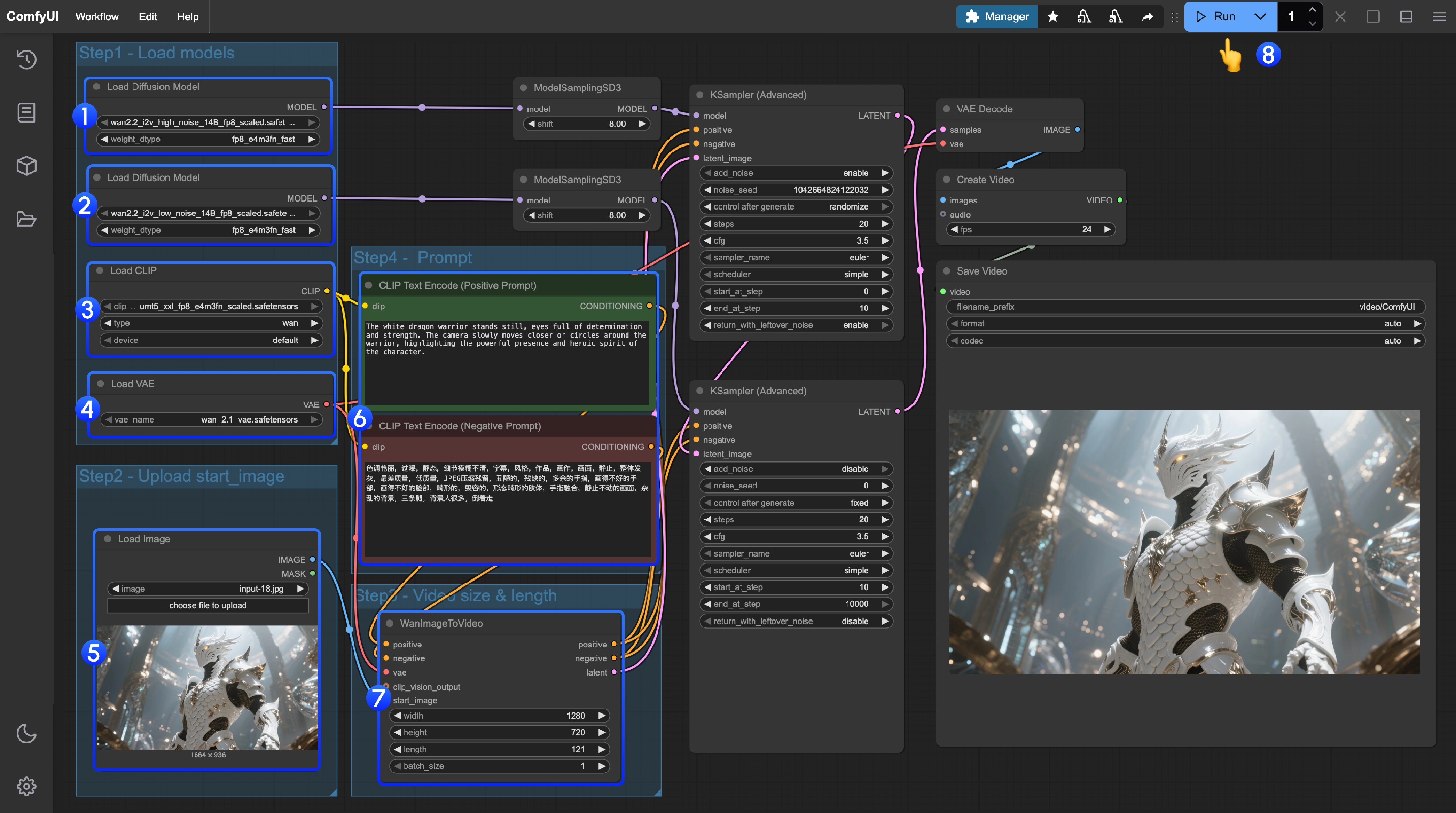
- Ensure the first
Load Diffusion Modelnode loads thewan2.2_t2v_high_noise_14B_fp8_scaled.safetensorsmodel - Ensure the second
Load Diffusion Modelnode loads thewan2.2_t2v_low_noise_14B_fp8_scaled.safetensorsmodel - Ensure the
Load CLIPnode loads theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure the
Load VAEnode loads thewan_2.1_vae.safetensorsmodel - Upload the image as the starting frame in the
Load Imagenode - If you need to modify prompts (positive and negative), please modify them in the
CLIP Text Encodernode numbered6 - (Optional) In
EmptyHunyuanLatentVideoyou can adjust the size settings and video total frame countlengthadjustment - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute video generation
4. Wan2.2 14B FLF2V First-Last Frame Video Generation Workflow
The first-last frame workflow uses exactly the same model location as the I2V section
Workflow and Material Acquisition
Download the video or JSON format workflow below and open it in ComfyUI <video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan22_14B_flf2v.mp4"
Download the materials below as input


Detailed Operation Steps
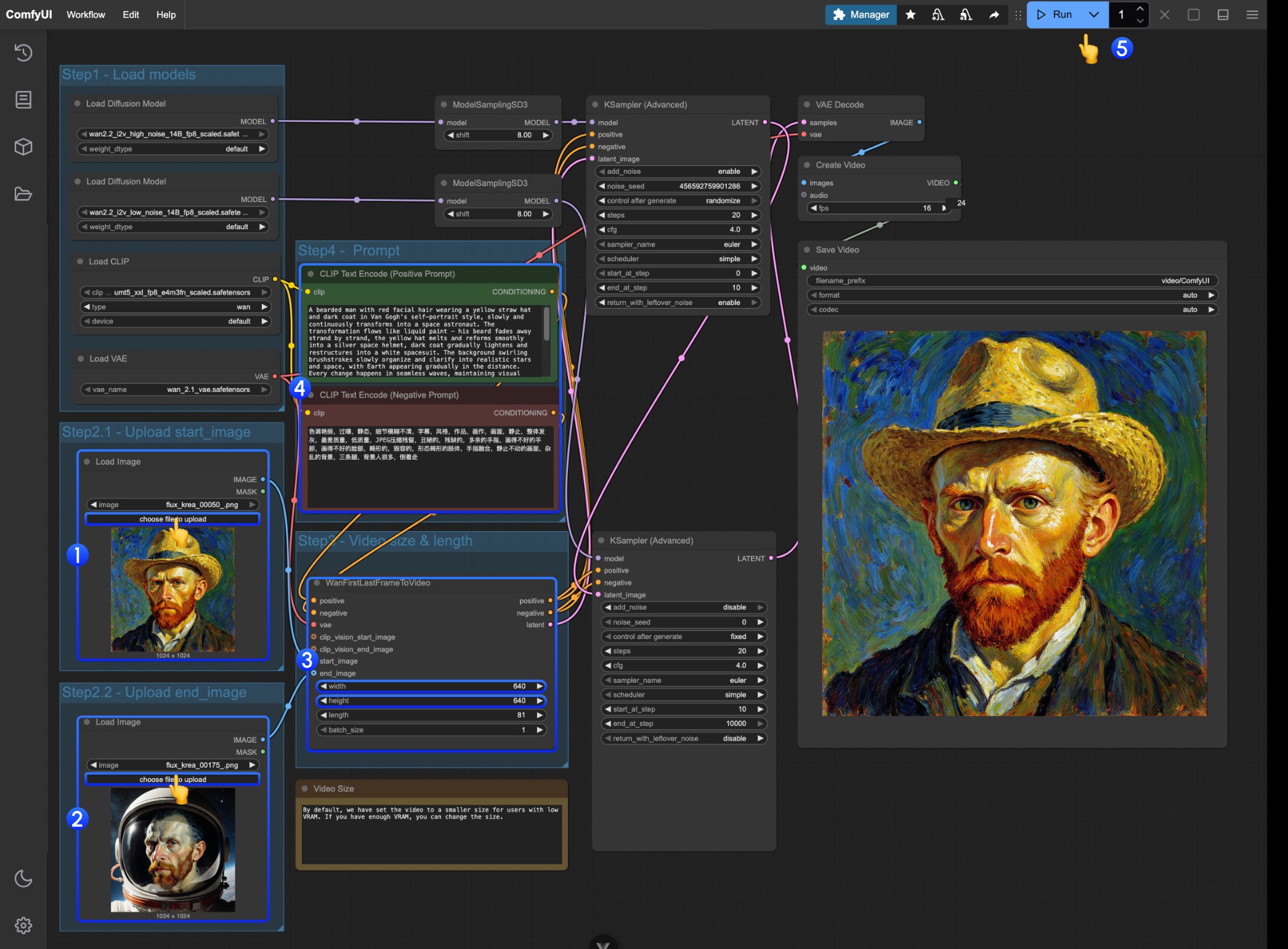
- Upload the image as the starting frame in the first
Load Imagenode - Upload the image as the starting frame in the second
Load Imagenode - Modify the size settings on
WanFirstLastFrameToVideo- The workflow defaults to a relatively small size to prevent low VRAM users from consuming too many resources
- If you have sufficient VRAM, you can try around 720P size
- Write appropriate prompts according to your first-last frames
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute video generation
Wan2.2 Kijai WanVideoWrapper ComfyUI Workflow
This part of the tutorial will introduce the convenient method using Kijai/ComfyUI-WanVideoWrapper.
Related model repository: https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Wan2.2 GGUF Quantized Version ComfyUI Workflow
The GGUF version is suitable for users with limited VRAM, providing the following resources:
Related Custom Nodes: City96/ComfyUI-GGUF
Lightx2v 4steps LoRA Usage Instructions
Lightx2v provides a fast generation optimization solution:
Comments
Sign in with GitHub to join the discussion.