ACE-Step ComfyUI Native and Custom Node Workflow Guide
How to use ACE-Step model to generate music in ComfyUI。
ACE-Step is an open-source music generation foundation model jointly developed by the Chinese team StepFun and ACE Studio, designed to provide music creators with efficient, flexible, and high-quality music generation and editing tools.
The model is released under the Apache-2.0 license and is free for commercial use.
As a powerful music generation base model, ACE-Step offers rich extension capabilities. Through fine-tuning technologies like LoRA and ControlNet, developers can customize the model according to their specific needs. Whether it's audio editing, vocal synthesis, accompaniment production, voice cloning, or style transfer, ACE-Step can provide stable and reliable technical support. This flexible architecture design greatly simplifies the development process of music AI applications, allowing more creators to quickly apply AI technology to music creation.
Currently, ACE-Step has released related training code, including LoRA model training, and corresponding ControlNet training code will be released in the future. You can visit their Github for more details.
ACE-Step Implementation in ComfyUI and Multi-language Support Explanation
In ACE-Step's multi-language implementation, different languages are unified by converting them to corresponding English characters for music generation. However, ComfyUI's native support currently doesn't implement this language-to-English conversion step, only matching conversion for Japanese katakana can be found in this commit. Since implementing this step requires introducing additional dependencies, adding them to core dependencies might lead to various potential issues and custom node conflicts. Therefore, in ComfyUI we currently cannot directly use different languages for input, but need to convert them to corresponding English characters.
However, custom node authors have implemented corresponding language conversion, enabling direct multi-language input. In this documentation, we will combine native workflows and custom nodes to complete the ACE-Step workflow. You may have already downloaded this file. Below is an explanation of the two ACE-Step implementation methods in ComfyUI.
1. ComfyUI Native Support
- Advantages: Uses merged All-in-one model, convenient loading, simple to use
- Disadvantages: Doesn't support direct multi-language input, requires converting corresponding languages to English characters for music generation
Currently, ComfyUI has native support for ACE-Step, but the disadvantage is that it doesn't support direct multi-language input.
2. Custom Node ComfyUI_ACE-Step Implementation
ComfyUI_ACE-Step mainly implements direct multi-language input, supports multi-language lyrics input, and supports multi-language prompt input.
- Advantages: Supports direct multi-language input, simple to use
- Disadvantages: Doesn't use merged model, requires downloading multiple models
This custom node currently adds dependencies for Japanese, Chinese, and Korean translation in its core dependencies, so you can directly use multiple languages for music generation. Additionally, the author has optimized the handling of mixed multi-language input.
In this tutorial workflow, we will add the corresponding ACE-Step Lyrics Language Switch from ComfyUI_ACE-Step. If you need multi-language input, this can greatly facilitate language input.
However, during testing, it was found that this language conversion node still has some issues with Japanese conversion. Therefore, if you want to use Japanese for song generation, please directly use Japanese katakana for input.
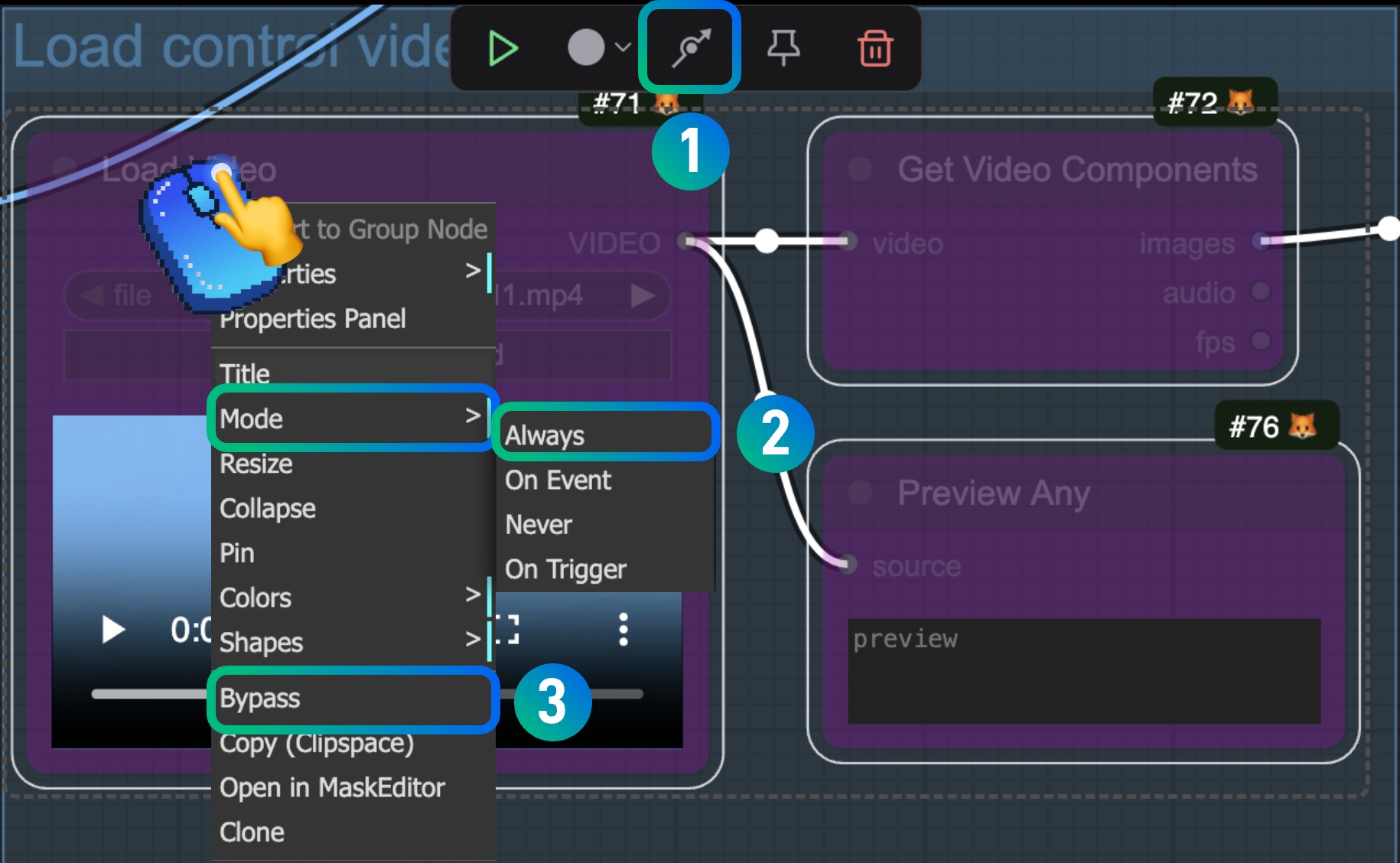
Also, in the workflow I provided, the corresponding node is in Bypass mode by default, so if you need to enable multi-language input, you need to right-click on the node and set the node mode to Always mode.
Preparation Before Starting
- Please upgrade your ComfyUI to the latest version to ensure you have the corresponding native support
- (Optional, if you need direct multi-language input) Install the ComfyUI_ACE-Step plugin (install directly using ComfyUI Manager)
- Model download, download ace_step_v1_3.5b.safetensors and save it to the
ComfyUI/models/checkpointsfolder
ComfyUI ACE-Step Text to Audio Generation
1. Workflow File Download
Click the button below to download the corresponding workflow file, drag it into ComfyUI to load the corresponding workflow information. The workflow includes model download information.
2. Complete Workflow Execution Step by Step
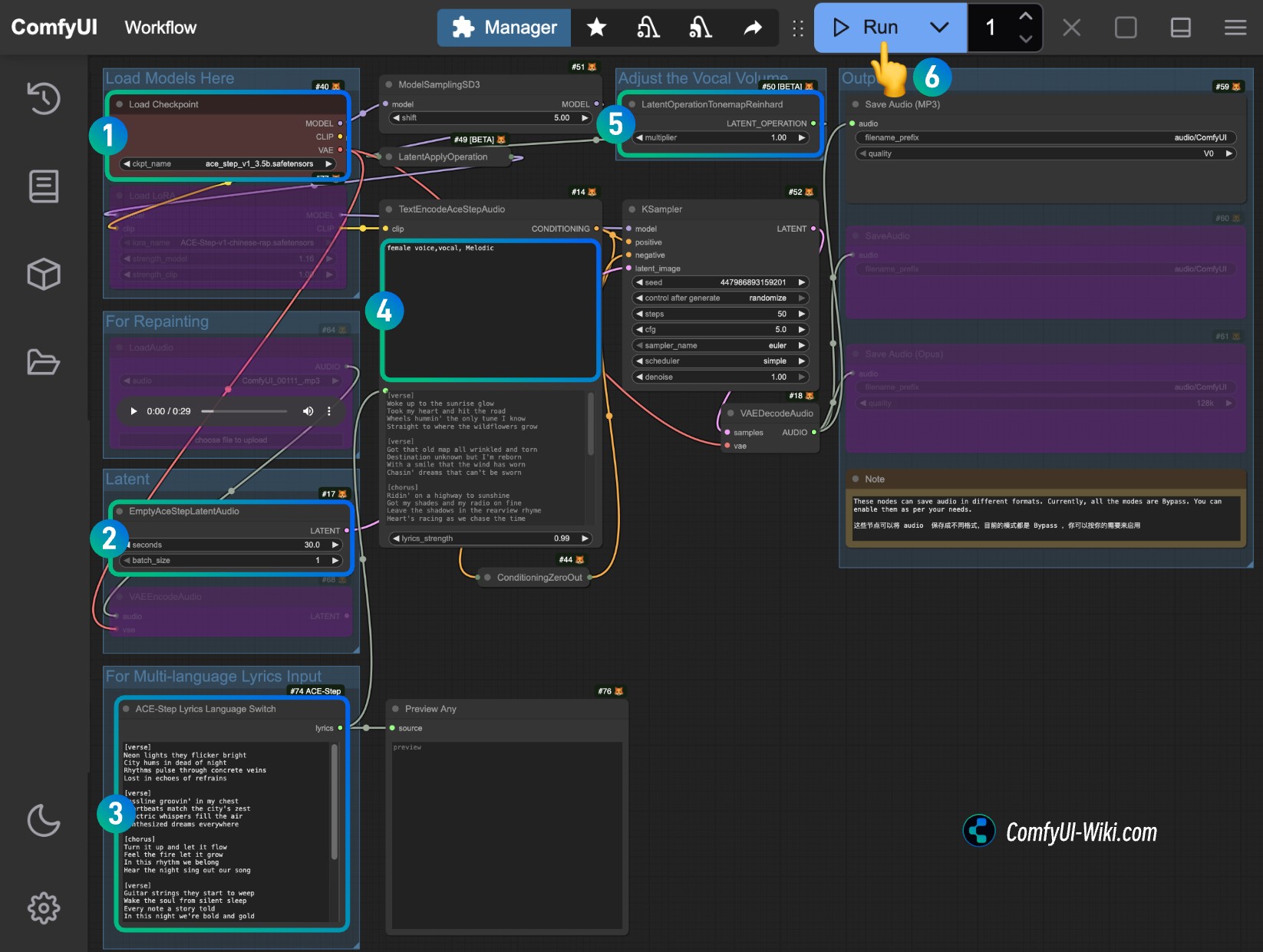
- Ensure the
Load Checkpointsnode loads theace_step_v1_3.5b.safetensorsmodel - (Optional) In the
EmptyAceStepLatentAudionode, you can set the duration of the generated music - (Optional) Input corresponding lyrics in the
ACE-Step Lyrics Language Switch. If you don't know how to input, you can refer to the ACE-Step Project Page. If you need Japanese input, please delete this part and directly use ComfyUI's native node to input Japanese katakana. - (Optional) Input corresponding music style etc. in the
TextEncodeAceStepAudiotags - (Optional) In the
LatentOperationTonemapReinhardnode, you can adjust themultiplierto adjust the vocal volume (larger numbers make vocals more prominent) - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute audio generation. - After the workflow is complete, you can view the generated audio in the
Save Audionode. You can click to play and preview, and the corresponding audio will also be saved toComfyUI/output/audio(subdirectory name determined by theSave Audionode).
ComfyUI ACE-Step Audio to Audio
When using the ACE Step audio-to-audio workflow, you can input a piece of music like in an image-to-image workflow, and use the workflow below to achieve resampling generation. Similarly, you can also adjust the difference from the original audio by controlling the denoise parameter of Ksampler.
You can achieve:
- Music style adjustment
- Modifying parts of the lyrics, etc.
You can see more examples on the ACE-Step Project Page
1. Workflow File Download (Audio to Audio)
Click the button below to download the corresponding workflow file, drag it into ComfyUI to load the corresponding workflow information
We can use the audio from the text-to-audio workflow as input audio
2. Complete Workflow Execution Step by Step (Audio to Audio)
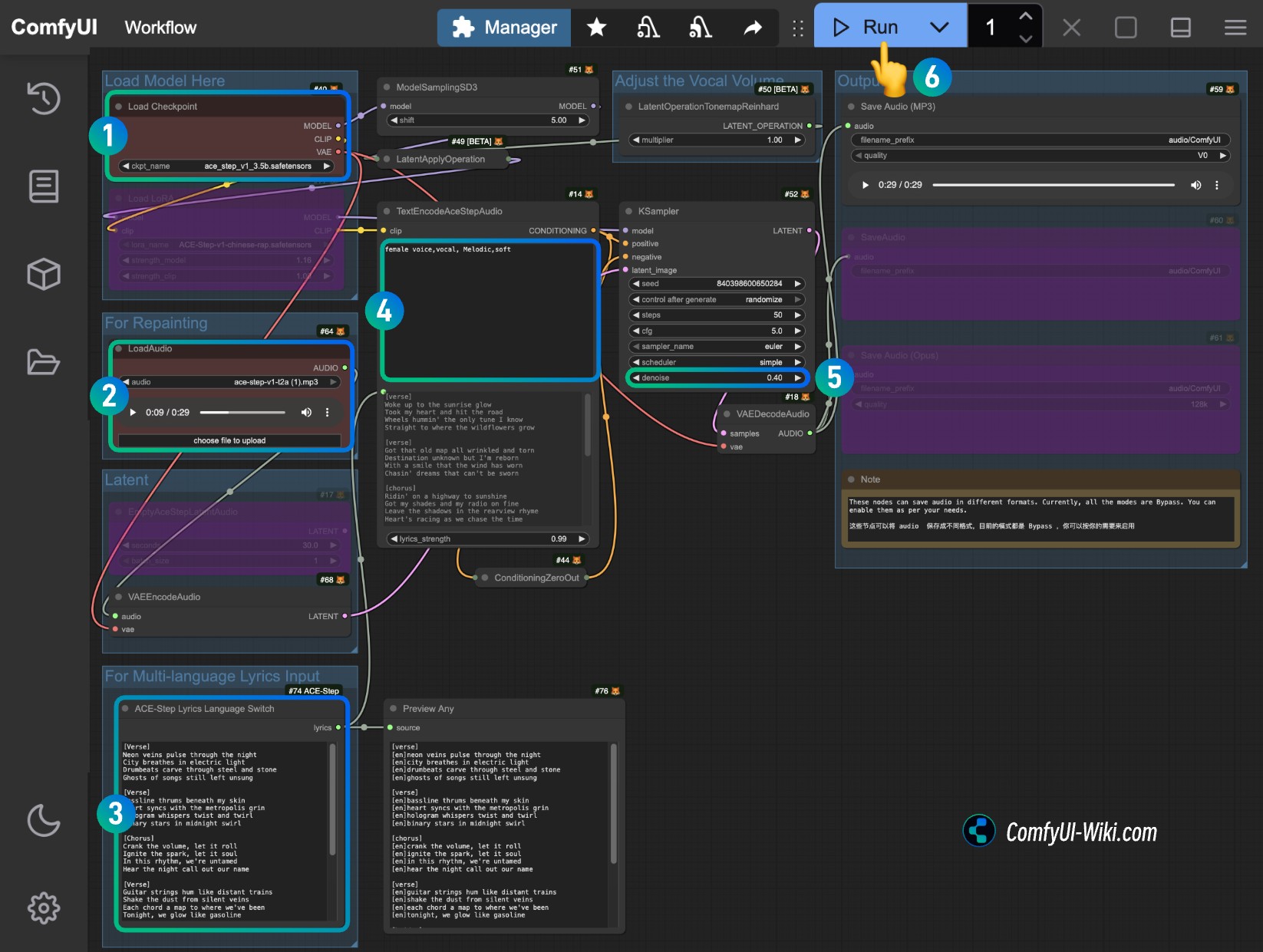
- Ensure the
Load Checkpointsnode loads theace_step_v1_3.5b.safetensorsmodel - Upload the audio to be edited in the
LoadAudionode - (Optional) Input modified lyrics in the
ACE-Step Lyrics Language Switch, you can refer to the ACE-Step Project Page - (Optional) Input corresponding music style in the
TextEncodeAceStepAudiotags - (Optional) Modify the
denoiseparameter of theKSamplernode (larger numbers create more difference from the original audio) - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute audio generation - After the workflow is complete, you can view the generated audio in the
Save Audionode. You can click to play and preview, and the corresponding audio will also be saved toComfyUI/output/audio(subdirectory name determined by theSave Audionode).
ComfyUI ACE-Step LoRA
ACE-Step has officially released a Chinese RAP style LoRA model. You can visit ACE-Step/ACE-Step-v1-chinese-rap-LoRA to download the corresponding LoRA model. Remember to rename it to ace-step-v1-chinese-rap-lora.safetensors. Before starting, you need to manually download the corresponding file and save it to the ComfyUI/models/loras folder.
1. Workflow File Download (LoRA)
2. Complete Workflow Execution Step by Step (LoRA)
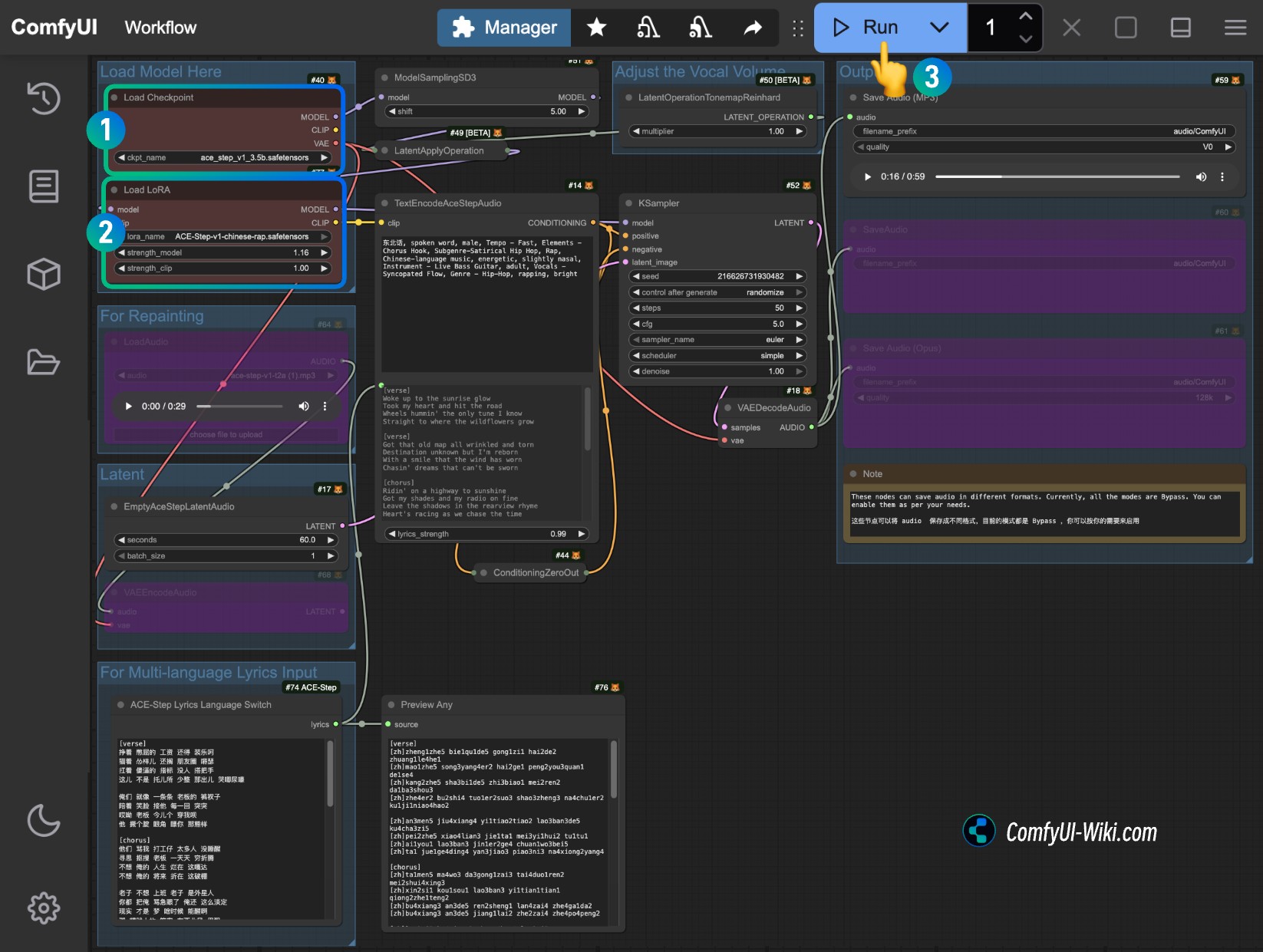
- Ensure the
Load Checkpointsnode loads theace_step_v1_3.5b.safetensorsmodel - Add the
ace-step-v1-chinese-rap-lora.safetensorsmodel in theLoad LoRAnode - Other options are modified the same as text-to-video generation. Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute audio generation - After the workflow is complete, you can view the generated audio in the
Save Audionode. You can click to play and preview, and the corresponding audio will also be saved toComfyUI/output/audio(subdirectory name determined by theSave Audionode).
ACE-Step Music Extension
[To be added]
ACE-Step Prompt Guide
ACE currently uses two types of prompts: tags and lyrics.
tags: Mainly used to describe music style, scene, etc., similar to other generation prompts we commonly use. It mainly describes the overall style and requirements of the audio, separated by English commaslyrics: Mainly used to describe lyrics, supports lyric structure tags such as [verse] (verse), [chorus] (chorus), and [bridge] (bridge) to distinguish different parts of the lyrics. It can also input instrument names for instrumental music
You can find rich examples of tags and lyrics on the ACE-Step Model Homepage. You can refer to the corresponding examples to try the prompts. The prompts below have been organized in the ComfyUI official documentation, mostly from the ACE-Step Project Homepage. It's recommended to visit their official documentation to learn how to write prompts.
tags (prompt)
Mainstream Music Styles
Use short tag combinations to generate specific music styles
- electronic
- rock
- pop
- funk
- soul
- cyberpunk
- Acid jazz
- electro
- em
- soft electric drums
- melodic
More Music Style Combination Examples
- DUBSTEP, DARKNESS, FEAR, TERROR (repeating tags can enhance effects)
- dark, death rock, metal, hardcore, electric guitar, powerful, bass, drums, 110 bpm, G major
- Cuban music, salsa, son, Afro-Cuban, traditional Cuban
- alternative rock, pop, rock
- dark electro, industrial techno, gothic rave
- disco
- electronic rap
- country rock, folk rock, southern rock, bluegrass, pop
- melancholic, world, sad
Scene Types
Combine specific usage scenarios and atmosphere to generate music that matches the corresponding atmosphere
- background music for parties
- radio broadcasts
- workout playlists
Instrument Elements
- saxophone, jazz
- piano, violin
- 808 bass, sub bassline
- orchestral, synthesizer, violin, viola, cello
- phonk, russian dark accordion, russian psaltery, russian harmonica
Voice Types
- female voice
- male voice
- clean vocals
- crystal-clear soprano voice
- deep male voice
Professional Terms
Use common professional terms in music to precisely control music effects:
- 110 bpm, 140 bpm, 160 bpm (specify beats per minute)
- fast tempo
- slow tempo
- loops
- fills
- acoustic guitar
- electric bass
- G major, B flat major, D minor
Advanced Control Parameters
Variant Control
Control the degree of difference between generated music and original style:
- variance=0.1 (very similar, almost identical)
- variance=0.3 (moderate change, retains basic style)
- variance=0.5 (medium change, noticeable difference)
- variance=0.7 (significant change, obvious style transformation)
Audio Repainting
Can modify specific aspects or areas of audio while preserving the rest:
- change singing gender
- change style
- change lyrics
Special Music Type Prompts
- Pure vocals/acapella: Use "a cappella" tag, lyrics can use vowel combinations (like "aaaaaaaa, eeeeeeeee")
- Rap/rhythm control: Use "b-box, deep male voice, trap, hip-hop, super fast tempo"
- Experimental music: Can use unconventional inputs like vowel repetition or special text formats
- Pure instrumental: Use "[inst]" tag in lyrics section
Experimental Input Format
Can try using more structured HTML format to describe music, for example:
<SONG_PROMPT>
<header>
[STYLE: Electro-Acid House] [MOOD: Energetic, Raw, Hypnotic, Futuristic]
[INSTRUMENTATION: Acid Basslines, Punchy Kicks, Snappy Claps, Crisp Hi-Hats]
[TEMPO: 128 BPM] [PRODUCTION: Raw Energy, Dynamic Acid Sequences]
</header>
<SONG_MODULES>
<INTRO>
[Punchy kick and filtered acid bassline create a raw, pulsating groove.]
</INTRO>
<BUILD_UP_1>
[Acid bassline evolves with increasing resonance and modulation.]
</BUILD_UP_1>
<DROP_1>
[Full-power acid bassline dominates with high resonance and distortion.]
</DROP_1>
</SONG_MODULES>
</SONG_PROMPT>Lyrics
Lyric Structure Tags
- [intro]
- [verse]
- [pre-chorus]
- [chorus]
- [bridge]
- [outro]
- [hook]
- [refrain]
- [interlude]
- [breakdown]
- [ad-lib]
Instrumental Music
For instrumental music, you can use in the lyrics section: [inst] Or specify instrument sections:
[verse]
[chorus]
[solo]
[verse]
[chorus]
[outro]Multilingual Support
- ACE-Step V1 supports multiple languages. When used, ACE-Step converts different languages into corresponding English characters for music generation.
- In ComfyUI, we have not fully implemented the conversion from all languages to English characters. Currently, only Japanese hiragana and katakana characters are supported.
Therefore, if you need to use multiple languages for music generation, you need to first convert the corresponding language to English characters, then add the language code abbreviation at the beginning of
lyrics, such as Chinese[zh], Korean[ko], etc., or use theACE-Step Lyrics Language Switchnode mentioned in this article to complete the language conversion.
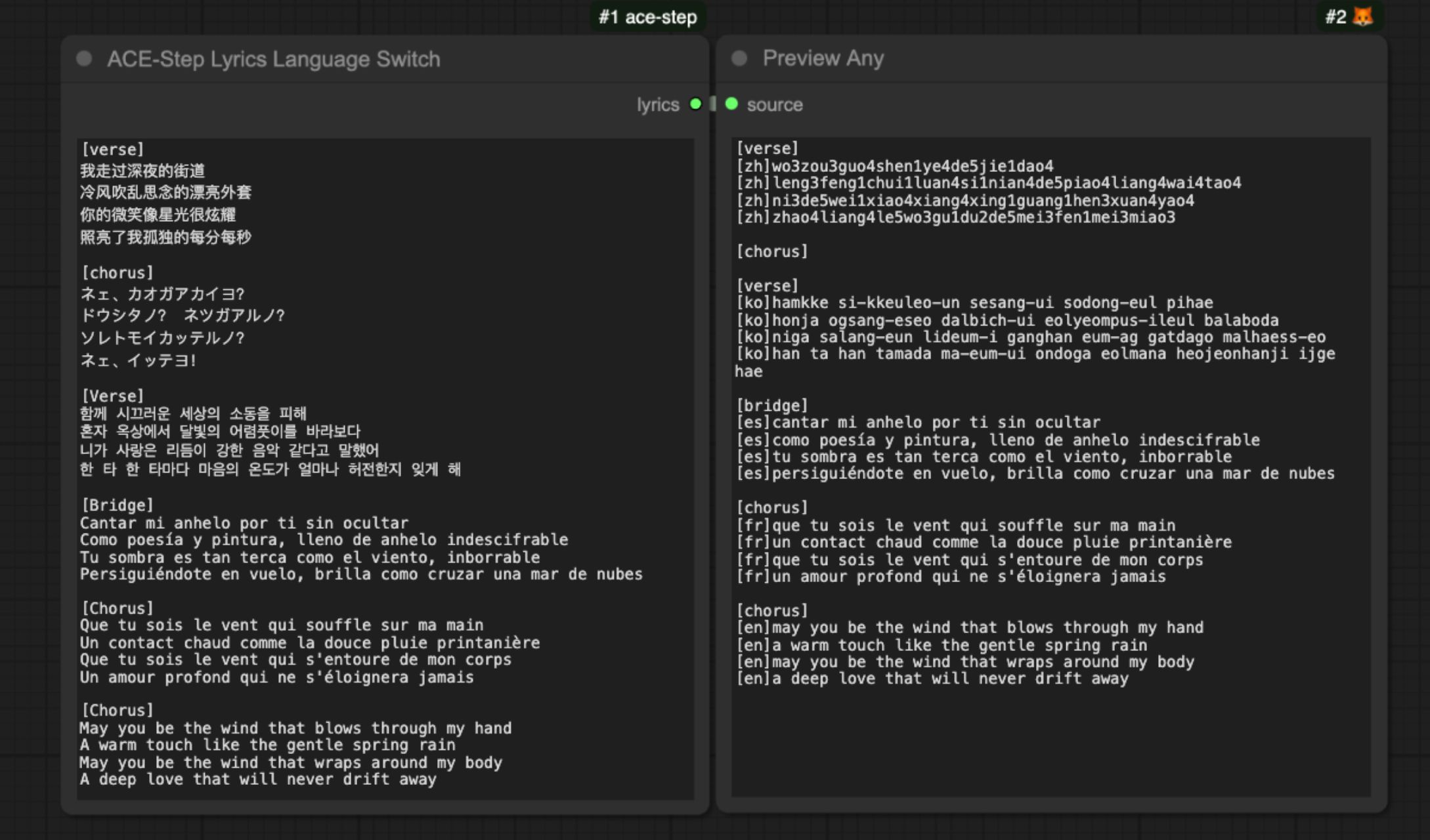
For example:
[verse]
[zh]wo3zou3guo4shen1ye4de5jie1dao4
[zh]leng3feng1chui1luan4si1nian4de5piao4liang4wai4tao4
[zh]ni3de5wei1xiao4xiang4xing1guang1hen3xuan4yao4
[zh]zhao4liang4le5wo3gu1du2de5mei3fen1mei3miao3
[chorus]
[verse]
[ko]hamkke si-kkeuleo-un sesang-ui sodong-eul pihae
[ko]honja ogsang-eseo dalbich-ui eolyeompus-ileul balaboda
[ko]niga salang-eun lideum-i ganghan eum-ag gatdago malhaess-eo
[ko]han ta han tamada ma-eum-ui ondoga eolmana heojeonhanji ijge hae
[bridge]
[es]cantar mi anhelo por ti sin ocultar
[es]como poesía y pintura, lleno de anhelo indescifrable
[es]tu sombra es tan terca como el viento, inborrable
[es]persiguiéndote en vuelo, brilla como cruzar una mar de nubes
[chorus]
[fr]que tu sois le vent qui souffle sur ma main
[fr]un contact chaud comme la douce pluie printanière
[fr]que tu sois le vent qui s'entoure de mon corps
[fr]un amour profond qui ne s'éloignera jamaisACE-Step currently supports 19 languages, but the following ten languages are better supported:
- English
- Chinese: [zh]
- Russian: [ru]
- Spanish: [es]
- Japanese: [ja]
- German: [de]
- French: [fr]
- Portuguese: [pt]
- Italian: [it]
- Korean: [ko]
Lyrics Editing Examples
In the audio-to-audio workflow, you can precisely modify specific lyrics:
- "When I was young" -> "when you were kid"
- "When I was young" -> "When I was old"
- "I'd listen to the radio" -> "I'd listen to the spotify"
- "It made me smile" -> "It made me cry"
You can also perform language conversion while maintaining the same melody and style:
- "When I was young" -> "Quand j'étais jeune" (French)
- "When I was young" -> "In meiner Jugend" (German)
- "When I was young" -> "子供の頃に" (Japanese)
- "When I was young" -> "내가 어렸을 때" (Korean)
- "When I was young" -> "我小的时候" (Chinese)
However, inputting in ComfyUI's native nodes might be cumbersome, so it's recommended to use the ACE-Step Lyrics Language Switch node to handle language conversion.
Comments
Sign in with GitHub to join the discussion.