Text to video
Text to videoBase model
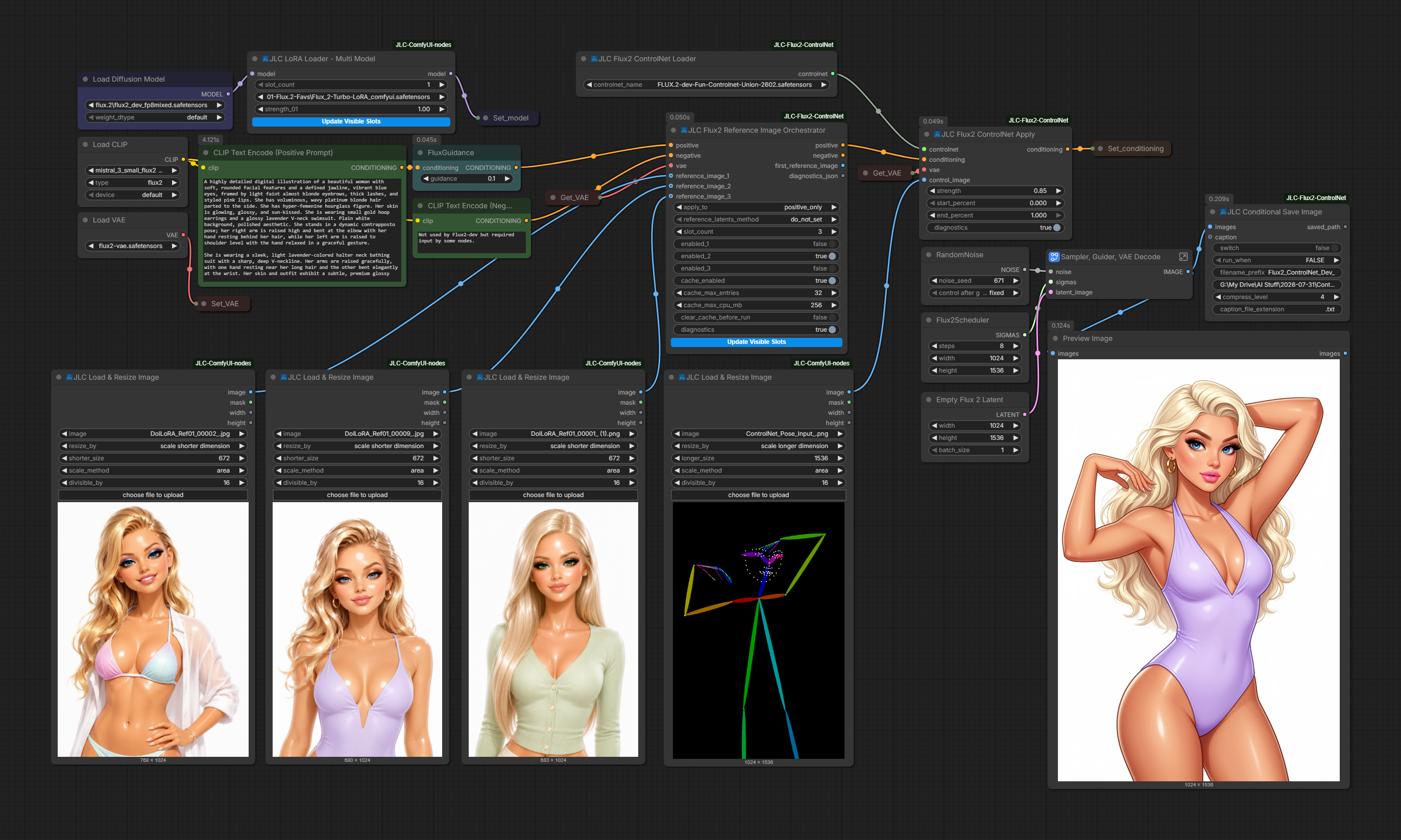
FLUX 3: Black Forest Labs' Multimodal Video, Audio and Image ModelBlack Forest Labs unveils FLUX 3, a unified multimodal foundation model generating 20-second video with native audio, images, and action prediction for robotics.
API-Only