Insert Anything: Open-Source Framework for Seamless Image Insertion
Insert Anything is an open-source unified framework that can seamlessly insert elements such as people, objects, and clothing from reference images into target scenes, supporting various application scenarios

Insert Anything is a new open-source image editing framework jointly developed by a research team (Wensong Song, Hong Jiang, Zongxing Yang, Ruijie Quan, Yi Yang) from Zhejiang University, Harvard University, and Nanyang Technological University. This framework can seamlessly integrate objects from reference images into target scenes under user-specified control guidance.
This unified image insertion framework supports multiple practical application scenarios, including artistic creation, real face replacement, movie scene composition, virtual clothing try-on, accessory customization, and digital prop replacement, fully demonstrating its versatility and effectiveness in various image editing tasks.
Key Features
- Unified Insertion Framework: No need to train separate models for different tasks, one model supports multiple insertion scenarios
- Multiple Control Methods: Supports mask-based and text-based editing guidance
- Identity Feature Preservation: Accurately captures identity features and fine details, while allowing diverse local adjustments in style, color, and texture
- Context Editing Mechanism: Treats reference images as contextual information, using two prompting strategies to harmoniously blend inserted elements with the target scene
- Low VRAM Version Support: Provides a 10GB VRAM version based on Nunchaku, convenient for ordinary users
Application Showcases
Meme Creation
Meme creation is an important application scenario for Insert Anything. Here are some comparison images:






Commercial Advertisement Design
Commercial advertisement design is another important application scenario for Insert Anything. Here are some comparison images:






Pop Culture Creation
Pop culture creation showcases Insert Anything's potential in creative content generation:








Technical Highlights
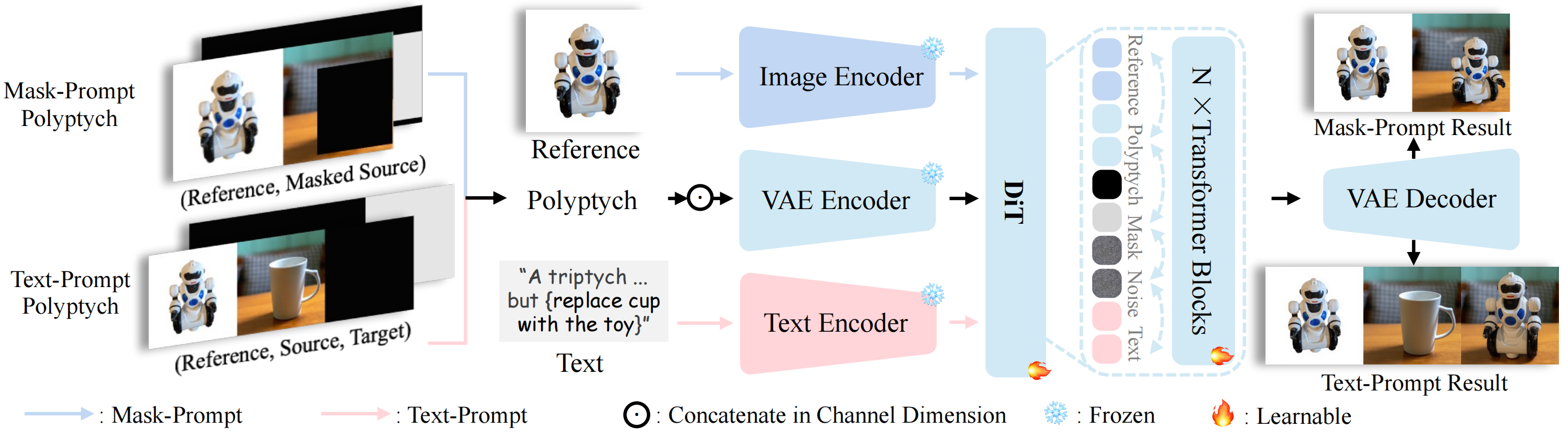
Insert Anything utilizes the multimodal attention mechanism of Diffusion Transformer (DiT), supporting both mask-based and text-based editing. According to different types of prompts, this unified framework processes multiple input images (combinations of reference images, source images, and masks) through a frozen VAE encoder to preserve high-frequency details, and extracts semantic guidance from image and text encoders. These embeddings are combined and input into learnable DiT transformer blocks for context learning, enabling precise and flexible image insertion based on mask or text prompts.
AnyInsertion Dataset


To train this unified framework, the research team created the AnyInsertion dataset, which contains approximately 120,000 prompt-image pairs covering various insertion tasks such as person, object, and clothing insertion. The dataset is divided into mask-based and text-based categories, each further subdivided into accessories, objects, and person subcategories.
The image pairs in the dataset come from internet resources, person videos, and multi-view images. The dataset covers various insertion scenarios:
- Furniture and interior decoration
- Daily necessities
- Clothing and accessories
- Transportation vehicles
- People
Open Source and Usage
The Insert Anything project has been open-sourced on GitHub, and anyone can freely download and use it:
- GitHub Repository: song-wensong/insert-anything
- Dataset: WensongSong/AnyInsertion
The project provides multiple usage methods:
- Command-line inference scripts
- Gradio interface
- ComfyUI integration nodes
Hardware Requirements
Insert Anything offers two versions:
- Standard Version: Requires 26GB or 40GB VRAM
- Lightweight Version: Optimized version based on Nunchaku, requires only 10GB VRAM
Future Plans
According to the official GitHub repository information, the team plans to:
- Release training code
- Release the AnyInsertion text prompt dataset on HuggingFace
Related Links
The release of this open-source framework will provide creative workers, designers, and content creators with a powerful tool to achieve more flexible and precise image editing effects.
Comments
Sign in with GitHub to join the discussion.