Tencent Hunyuan Team Open Sources MixGRPO Framework for Enhanced Human Preference Alignment Training Efficiency
Tencent Hunyuan team releases open-source MixGRPO framework, the first to integrate sliding-window mixed ODE-SDE sampling for GRPO, achieving up to 71% training speedup for human preference alignment in diffusion and flow models.
The Tencent Hunyuan team has officially open-sourced the MixGRPO framework! This is the first framework to integrate sliding-window mixed ODE-SDE sampling for GRPO (Generalized Reward-based Policy Optimization), specifically designed to enhance the efficiency of human preference alignment in AI models.
The framework significantly reduces training overhead while maintaining excellent performance. The MixGRPO-Flash variant achieves up to 71% training speedup, outperforming previous methods like DanceGRPO.
 Performance comparison for different numbers of denoising steps optimized. DanceGRPO's performance improvement relies on more steps optimized, while MixGRPO achieves optimal performance with only 4 steps
Performance comparison for different numbers of denoising steps optimized. DanceGRPO's performance improvement relies on more steps optimized, while MixGRPO achieves optimal performance with only 4 steps
MixGRPO Framework Features
Core Technical Innovations
- Sliding Window Mixed Sampling: First framework to integrate sliding-window mixed ODE-SDE sampling for GRPO
- Significant Efficiency Improvement: MixGRPO-Flash achieves up to 71% training speedup
- Higher-Order Solver Support: Supports higher-order ODE solvers for further acceleration
- Universal Compatibility: Applicable to both diffusion models and flow models
 Technical architecture diagram of MixGRPO, illustrating the working principle of the sliding window mechanism
Technical architecture diagram of MixGRPO, illustrating the working principle of the sliding window mechanism
Performance Advantages
- Dramatically Reduced Training Overhead: Significantly reduces computational resource consumption compared to traditional methods
- Superior to Previous Methods: Outperforms DanceGRPO and other previous methods in both effectiveness and efficiency
- Fast Convergence: Achieves model potential with only a few iteration steps
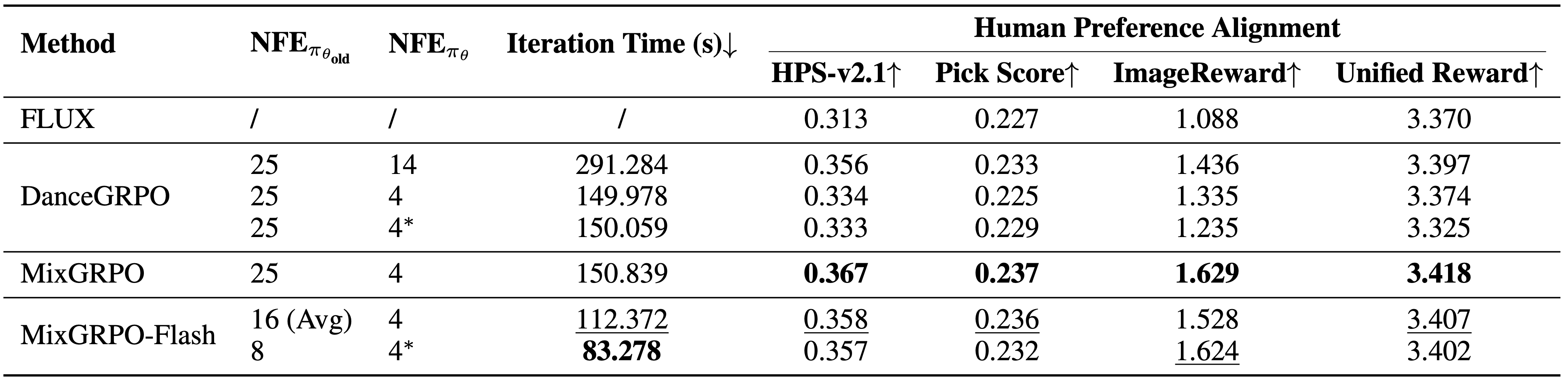 Comparison results for overhead and performance. MixGRPO achieves the best performance across multiple metrics, while MixGRPO-Flash significantly reduces sampling time while outperforming DanceGRPO
Comparison results for overhead and performance. MixGRPO achieves the best performance across multiple metrics, while MixGRPO-Flash significantly reduces sampling time while outperforming DanceGRPO
Technical Application Scenarios
The MixGRPO framework is primarily used for human preference alignment tasks, an important research direction in the AI field. Through this framework, researchers can:
- Train image generation models that better align with human preferences more efficiently
- Reduce computational costs for large-scale model training
- Accelerate experimental iteration while maintaining model quality
This technology is significant for improving the quality of AI-generated content and user satisfaction, particularly in image generation and content creation applications.
Experimental Results
 Qualitative comparison results. MixGRPO achieves superior performance in both semantics and aesthetics
Qualitative comparison results. MixGRPO achieves superior performance in both semantics and aesthetics
 Qualitative comparison with different training-time sampling steps. MixGRPO's performance does not significantly decrease with the reduction in overhead
Qualitative comparison with different training-time sampling steps. MixGRPO's performance does not significantly decrease with the reduction in overhead
 t-SNE visualization for images sampled with different strategies. Employing SDE sampling in the early stages of the denoising process results in a more discrete data distribution
t-SNE visualization for images sampled with different strategies. Employing SDE sampling in the early stages of the denoising process results in a more discrete data distribution
Open Source Resources
The MixGRPO framework is now fully open source. Researchers and developers can access related resources through the following channels:
Related Links
- Project Page: https://tulvgengenr.github.io/MixGRPO-Project-Page/
- Code Repository: https://github.com/Tencent-Hunyuan/MixGRPO
- Research Paper: https://arxiv.org/abs/2507.21802
The open sourcing of MixGRPO will provide powerful tool support for the AI research community, advancing the further development and application of human preference alignment technology.
Comments
Sign in with GitHub to join the discussion.