XVerse Released: A High-Consistency Image Generation Model with Multi-Subject Identity and Semantic Attribute Control
ByteDance open-sources XVerse model, enabling precise independent control of multiple subject identities and semantic attributes (like pose, style, lighting), enhancing AI image generation's personalization and complex scene capabilities.
XVerse is a controllable multi-subject image generation model open-sourced by ByteDance's Creative AI team in 2025. It focuses on solving the challenge of precise independent control of multiple objects (such as people, animals, objects) in AI-generated images. The model supports fine-grained, non-interfering adjustment of identity, pose, style, lighting, and other attributes for multiple subjects in an image, significantly enhancing generation capabilities for personalized and complex scenes.

I. Core Capabilities and Innovations
- Independent Multi-subject Control: Precisely controls identity, actions, and style of multiple subjects simultaneously, avoiding the common "attribute entanglement" issue in traditional methods.
- High Fidelity and Detail Preservation: Preserves details like hair strands and textures through VAE image feature encoding, reducing artifacts and distortion.
- Flexible Semantic Attribute Editing: Supports flexible adjustment of non-identity attributes like lighting and artistic style, maintaining subject characteristics during scene transitions.
- High Consistency and Stability: Innovative text flow modulation mechanism and dual regularization (region protection loss, text-image attention loss) ensure generation stability and consistency.
II. Technical Principles Overview
1. Text Flow Modulation Mechanism (T-Mod Adapter)
- Converts reference images into text embedding offsets, achieving precise independent control of multiple subjects through layered control signals (global sharing + block modulation).
- T-Mod adapter integrates CLIP image features with text prompts, generating cross-modulation signals to avoid feature confusion.
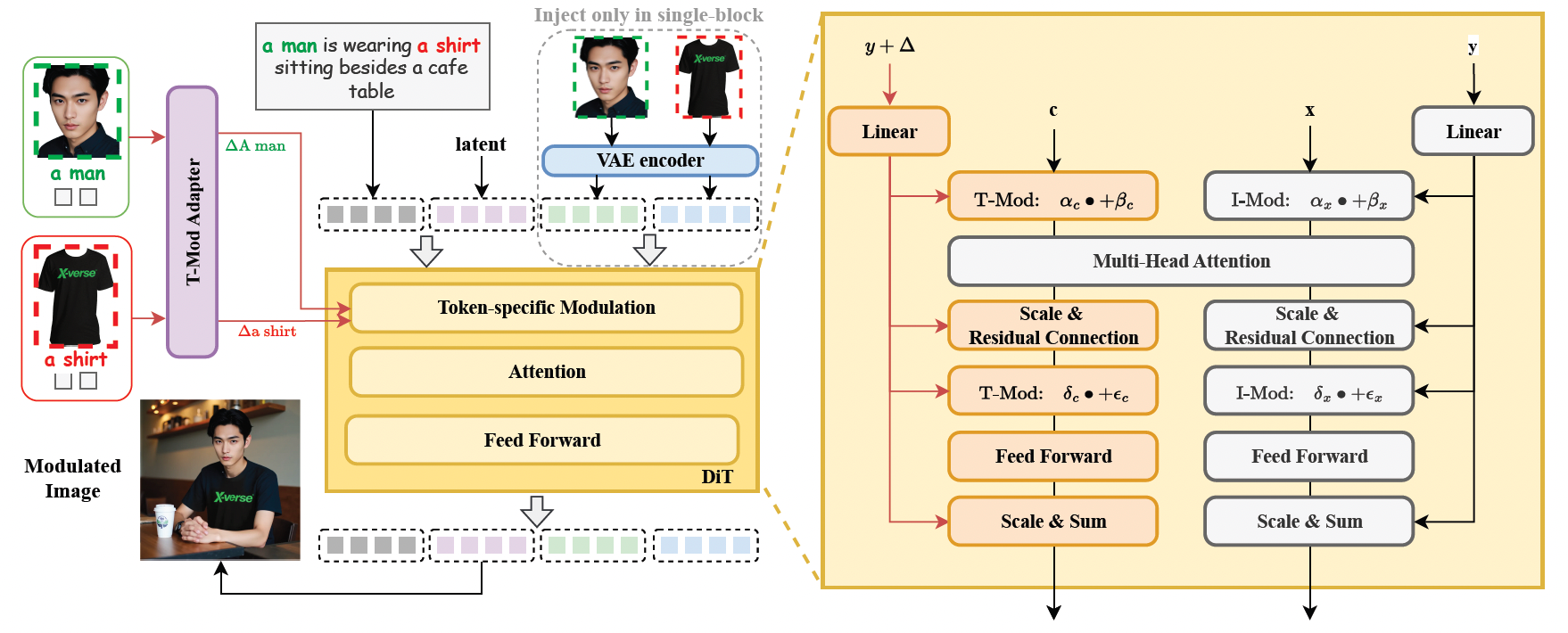
2. VAE Image Feature Encoding Module
- Introduces VAE encoded features in FLUX structure to enhance detail preservation, making generated images more realistic and natural.
3. Dual Regularization Mechanism
- Region Protection Loss: Randomly preserves certain regions from modulation to ensure non-target objects remain undisturbed.
- Text-Image Attention Loss: Optimizes attention allocation to improve semantic alignment accuracy.
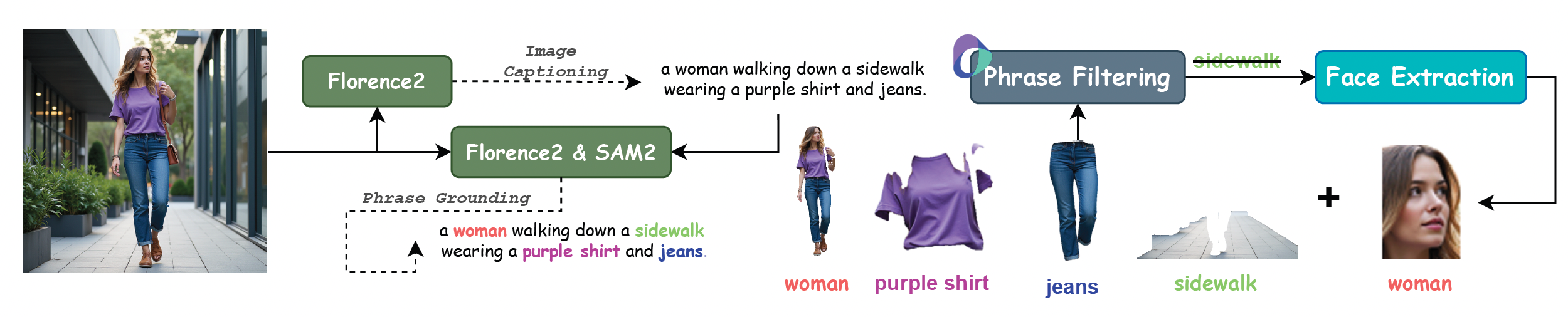
III. Training Data and Evaluation Benchmarks
XVerse uses a high-quality multi-subject control dataset covering 20 types of people, 74 types of items, and 45 types of animals, synthesizing millions of high-aesthetic quality images.
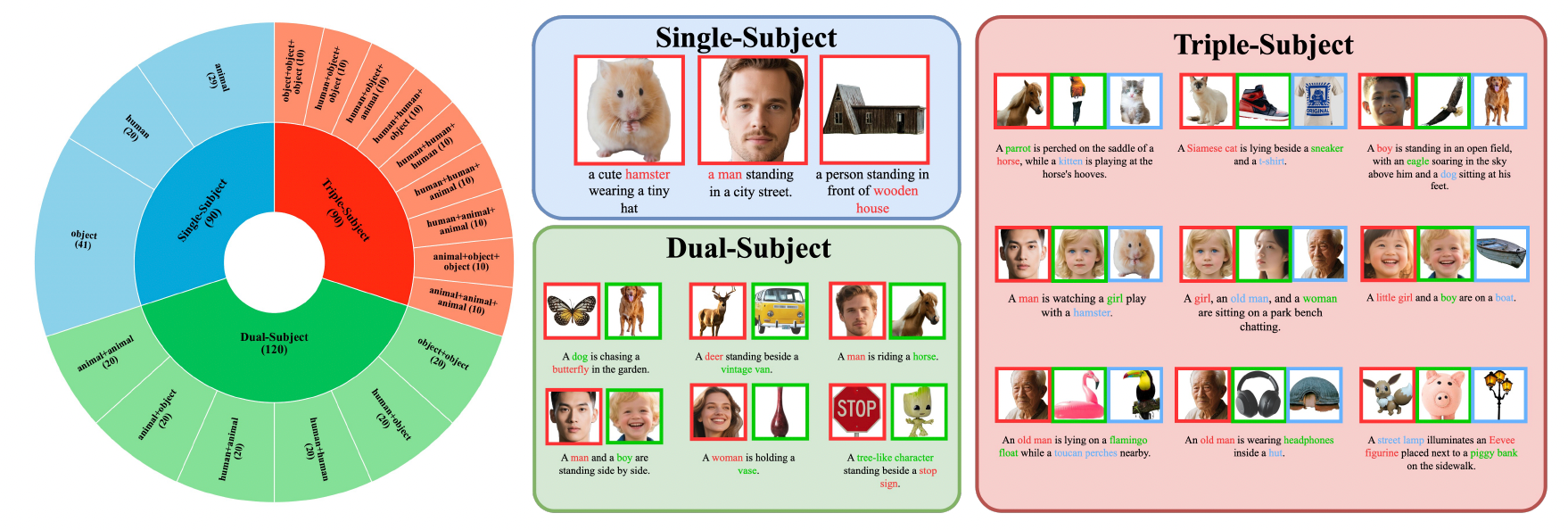
Model performance significantly outperforms similar methods on the XVerseBench benchmark, supporting various control scenarios including single, dual, and triple subjects.
| Metric | Meaning | | | | | DPG Score | Editing Capability | | Face ID Similarity | Person Identity Consistency | | DINOv2 Similarity | Object Feature Consistency | | Aesthetic Score | Image Aesthetic Quality |
IV. Experimental Results and Case Studies
1. Single Subject Identity and Attribute Precise Control
XVerse maintains subject identity consistency across diverse scenarios while flexibly adjusting pose, clothing, environment, and other attributes.





2. Multi-subject Consistency and Independent Control
XVerse achieves independent control of multiple subject identities and attributes within the same image while maintaining natural interaction and scene consistency.





3. Flexible Semantic Attribute Control
XVerse supports detailed adjustment of semantic attributes like lighting, pose, and style to meet diverse creative needs.

V. Open Source and Related Resources
- Project Homepage: https://bytedance.github.io/XVerse/
- GitHub Repository: https://github.com/bytedance/XVerse
- Model Download: https://huggingface.co/ByteDance/XVerse
- Technical Paper: https://arxiv.org/abs/2506.21416
Content referenced from XVerse Official Homepage, GitHub, and related open-source materials.