OmniAvatar: Release of Efficient Audio-Driven Virtual Human Video Generation Model
OmniAvatar model is now open source, supporting audio-driven full-body virtual human video generation with natural movements and rich expressions, suitable for podcasts, interactions, dynamic scenes, and various applications.
OmniAvatar is an open-source project jointly developed by Zhejiang University and Alibaba Group (released in June 2025). It is an audio-driven full-body digital human video generation model that creates natural and fluid virtual human videos through a single reference image, audio input, and text prompts. It supports precise lip-sync, full-body motion control, and multi-scene interaction, marking a significant advancement in digital human technology.
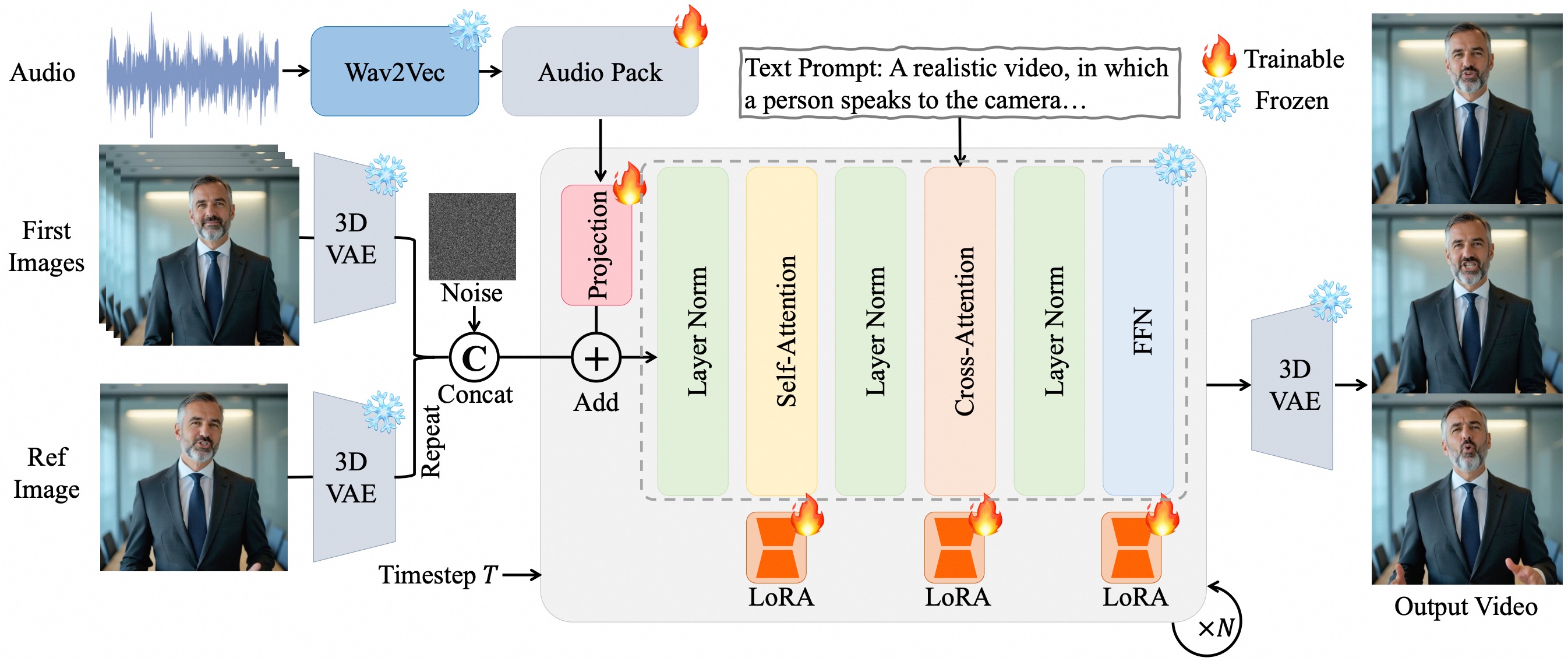
I. Core Technical Principles
Pixel-Level Multi-Layer Audio Embedding
- Uses Wav2Vec2 to extract audio features, aligning voice characteristics to video latent space pixel by pixel through the Audio Pack module, embedding audio information across multiple temporal layers in the diffusion model (DiT).
- Advantages: Achieves frame-level lip synchronization (such as subtle expressions triggered by aspirated words) and full-body motion coordination (like shoulder movements and gesture rhythms), with higher synchronization accuracy than mainstream models.
LoRA Fine-tuning Strategy
- Inserts low-rank adaptation matrices (LoRA) in Transformer's attention layers and feed-forward network layers, fine-tuning only the additional parameters while maintaining base model capabilities.
- Effects: Prevents overfitting, enhances audio-video alignment stability, and supports fine-grained control through text prompts (such as gesture amplitude and emotional expression).
Long Video Generation Mechanism
- Incorporates reference image latent encoding as identity anchors, combined with frame overlap strategy and progressive generation algorithms to mitigate color drift and identity inconsistency issues in long videos.
II. Core Features and Innovations
Full-Body Motion Generation
- Breaks through the traditional "head-only movement" limitation, generating natural and coordinated body movements (such as waving, toasting, dancing).
Multi-Modal Control Capabilities
- Text Prompt Control: Precisely adjusts actions (like "toasting celebration"), backgrounds (like "starry live studio"), and emotions (like "joy/anger") through descriptions.
- Object Interaction: Supports virtual human interaction with scene objects (like product demonstrations), enhancing realism in e-commerce marketing.
Multi-Language and Long Video Support
- Supports lip-sync adaptation for 31 languages including Chinese, English, and Japanese, capable of generating coherent videos over 10 seconds (requires high VRAM devices).
III. Rich Video Demonstrations
The OmniAvatar official website provides numerous real demonstrations covering various scenarios and control capabilities. Here are selected videos:
1. Speaker's Full-Body Motion and Expressions
2. Diverse Actions and Emotional Expressions
3. Human-Object Interaction
4. Background and Scene Control
5. Emotional Expression
6. Podcast and Singing Scenarios
For more demonstrations, visit OmniAvatar Official Website
IV. Open Source and Ecosystem
- Open Source Repository: GitHub - OmniAvatar
- Model Download: HuggingFace - OmniAvatar-14B
- Research Paper: arXiv:2506.18866
Content referenced from OmniAvatar Official Website, GitHub, and related open-source materials.
Comments
Sign in with GitHub to join the discussion.