StdGEN: Semantic-Decomposed 3D Character Generation from Single Images
Tsinghua University and Tencent AI Lab jointly introduce StdGEN, an innovative pipeline that generates high-quality semantically-decomposed 3D characters from single images, enabling separation of body, clothing, and hair

Researchers from Tsinghua University and Tencent AI Lab have recently released StdGEN (Semantic-Decomposed 3D Character Generation), an innovative technology capable of generating high-quality semantically-decomposed 3D character models from single images. This research has been accepted by the top computer vision conference CVPR 2025.
Technical Innovations
StdGEN implements three key features through its innovative pipeline:
- Semantic Decomposition: The generated 3D character models can be completely separated into semantic components such as body, clothing, and hair, facilitating subsequent editing and customization.
- Efficiency: The process from a single image to a complete 3D character takes only 3 minutes.
- High-Quality Reconstruction: The generated 3D models feature fine geometric details and textures.
Core Technology
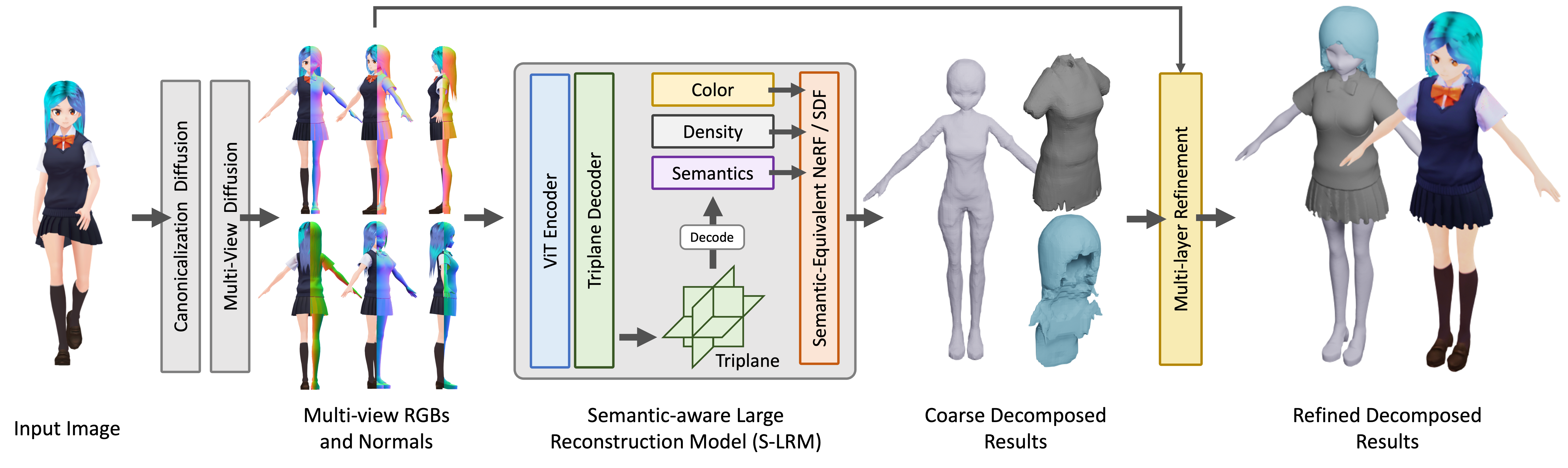 The core of StdGEN is the Semantic-aware Large Reconstruction Model (S-LRM) proposed by the research team. This is a generalizable Transformer-based model capable of jointly reconstructing geometry, color, and semantic information from multi-view images in a feed-forward manner.
The core of StdGEN is the Semantic-aware Large Reconstruction Model (S-LRM) proposed by the research team. This is a generalizable Transformer-based model capable of jointly reconstructing geometry, color, and semantic information from multi-view images in a feed-forward manner.
Additionally, the method introduces the following innovations:
- A differential multi-layer semantic surface extraction scheme for obtaining meshes from the hybrid implicit field reconstructed by S-LRM
- A specialized efficient multi-view diffusion model
- An iterative multi-layer surface refinement module
Application Prospects
This technology has broad application prospects in virtual reality, game development, and film production. Compared to existing methods, StdGEN achieves significant improvements in geometry, texture, and decomposability, providing users with ready-to-use semantically-decomposed 3D characters that support flexible customization.
The research team has open-sourced inference code, datasets, and pre-trained checkpoints, and also provides an online HuggingFace Gradio demo.