Alibaba Open Sources ACE++: Zero-Training Character-Consistent Image Generation
Alibaba Research Institute open sources image generation tool ACE++, supporting character-consistent image generation from single input through context-aware content filling technology, offering online experience and three specialized models.
February 10, 2025 — Alibaba Research Institute officially announces the open-source release of next-generation AI imaging tool ACE++. Based on innovative context-aware content filling algorithms, users can generate new images with highly consistent character features from just a single input image, supporting both online experience and local deployment.
Core Technical Innovations
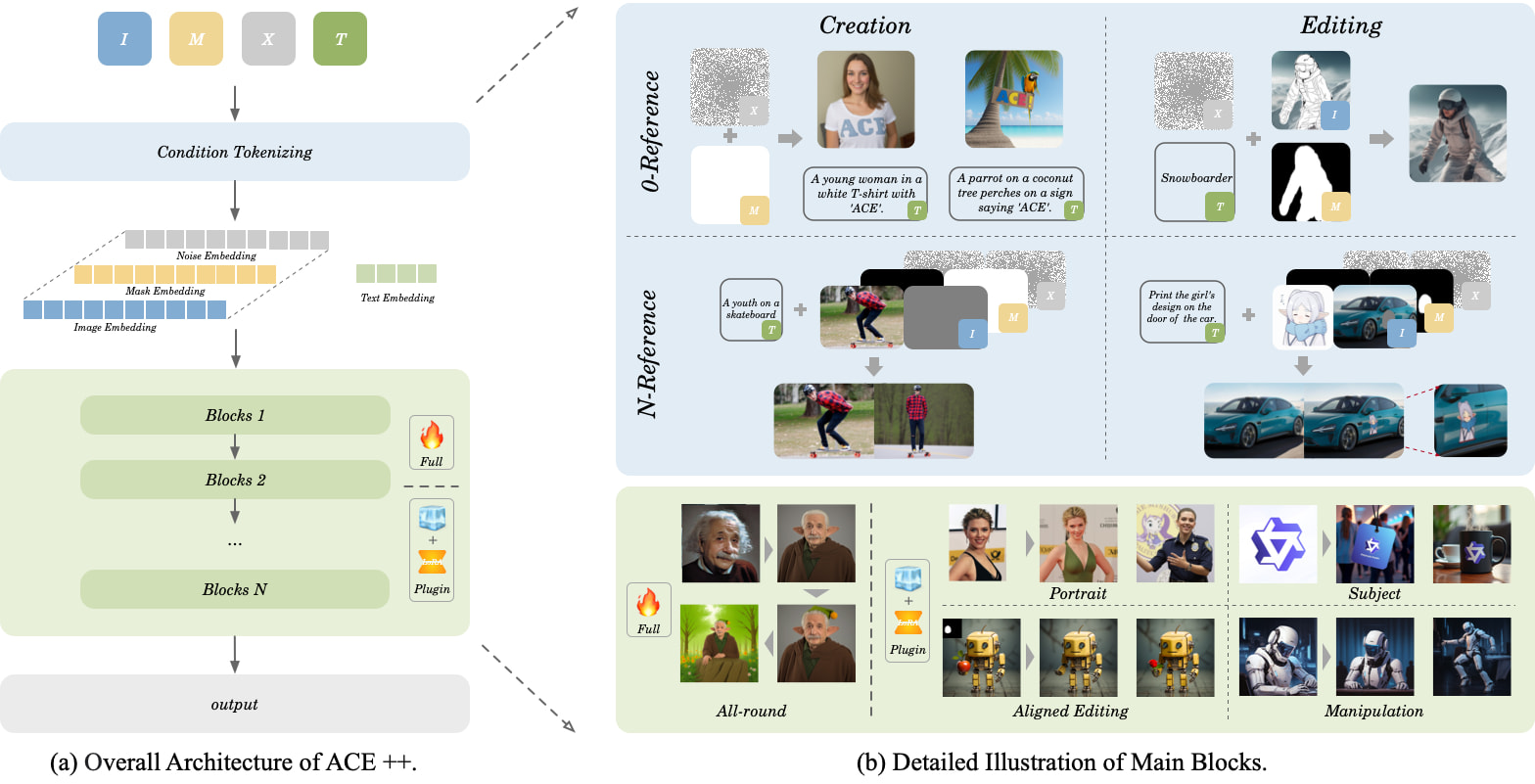
Key Features
- Zero-Training Generation: Leveraging FLUX.1-Fill-dev base model, achieving training-free deployment through LoRA adaptation
- Multimodal Editing:
- Character Outfit Change (supports clothing/hairstyle/accessory changes)
- Scene Reconstruction (background replacement/object addition/removal)
- Smart Restoration (flaw removal/quality enhancement)
- Semantic Understanding: Can parse compound instructions like "add steam to coffee cup, place on wooden table"
Technical Breakthroughs
- Long Context Unit (LCU): Simultaneously processes image content, text instructions, and editing regions
- Dynamic Attention Mechanism: Achieves 92.3% feature retention rate at 512×512 resolution
- Two-Stage Optimization: Step-by-step training approach combining basic restoration and specialized editing skills
Application Scenarios Testing
|  |
|  |
|
|
|
-|
-|
|  |
|  |
|
Typical Applications
-
Virtual Model Outfit Changes
- Generate multi-angle displays from flat clothing images
- Supports dynamic adjustment of skin tone/body type/scene
-
Film Character Design
- Achieves cross-style transformation (realistic→Disney/cyberpunk)
- Multi-scene generation maintaining character feature continuity
-
Smart Image Restoration
- 4K resolution reconstruction of old photos
- Seamless removal of complex occlusions
Resource Access Channels
Official Entries
| Resource Type | Access Link | |
--|
-| | Project Homepage | https://ali-vilab.github.io/ACE_plus_page/ | | Code Repository | GitHub | | Online Experience | ModelScope |
Official Model Download Links
Specialized Adaptation Models
| Model Type | File Name | ModelScope Download | HuggingFace Download | |
|
--|
-|
| | Portrait Generation | comfyui_portrait_lora64.safetensors | Portrait Model | Portrait Model | | Object Transfer | comfyui_subject_lora16.safetensors | Subject Model | Subject Model | | Local Editing | comfyui_local_lora16.safetensors | LocalEditing Model | LocalEditing Model |
Base Dependency Models
| Model Name | Download Channel | |
|
--| | FLUX.1-Fill-dev | HuggingFace Download | | Flux-Fill FP8 | CivitAI Download |
Technical Development Outlook
The current version still has room for improvement in complex object processing (hand detail accuracy 62.3%) and Chinese text support. The development team reveals plans to launch video continuous frame editing functionality in Q3 2025, and will release the complete ACE++ Fully model by year-end.
Please wait for workflow files after ComfyUI Wiki testing for content updates View Workflow Updates
Comments
Sign in with GitHub to join the discussion.