Flex.2-preview: Open Source AI Image Generation Model Released
Flex.2-preview is an open-source text-to-image diffusion model with universal control and built-in inpainting capabilities, providing creators with more powerful image generation tools

Flex.2-preview has been officially released as an open-source text-to-image diffusion model, following Flex.1-alpha. This model is completely open source, featuring 8 billion parameters and built-in image control and inpainting capabilities, providing creators with a more comprehensive image generation experience.
Key Features
Flex.2-preview includes the following key features:
- 8 billion parameters: Powerful parameter scale ensures high-quality image generation
- Guidance embedder: 2x faster generation speed
- Built-in inpainting: Native inpainting support
- Universal control input: Supports multiple control methods including lines, poses, and depth
- Fine-tunable: Supports customized training according to user needs
- Open license: Uses Apache 2.0 open source license
- Long text support: Supports input length of 512 tokens
- Created by and serving the community: Completely community-driven project
Development History
Flex.2-preview has evolved through several important stages: from Flux.1 Schnell to OpenFlux.1, then to Flex.1-alpha, and finally to the current Flex.2-preview.
Each step has seen important improvements, with Flex.2 being the biggest step so far. This preview release aims to gather user feedback and encourage community experimentation and tool development.
Using in ComfyUI
Flex.2 can be used in ComfyUI with the help of the Flex2 Conditioner node found in ComfyUI-FlexTools. It is also recommended to use comfyui_controlnet_aux to generate control images (pose and depth).
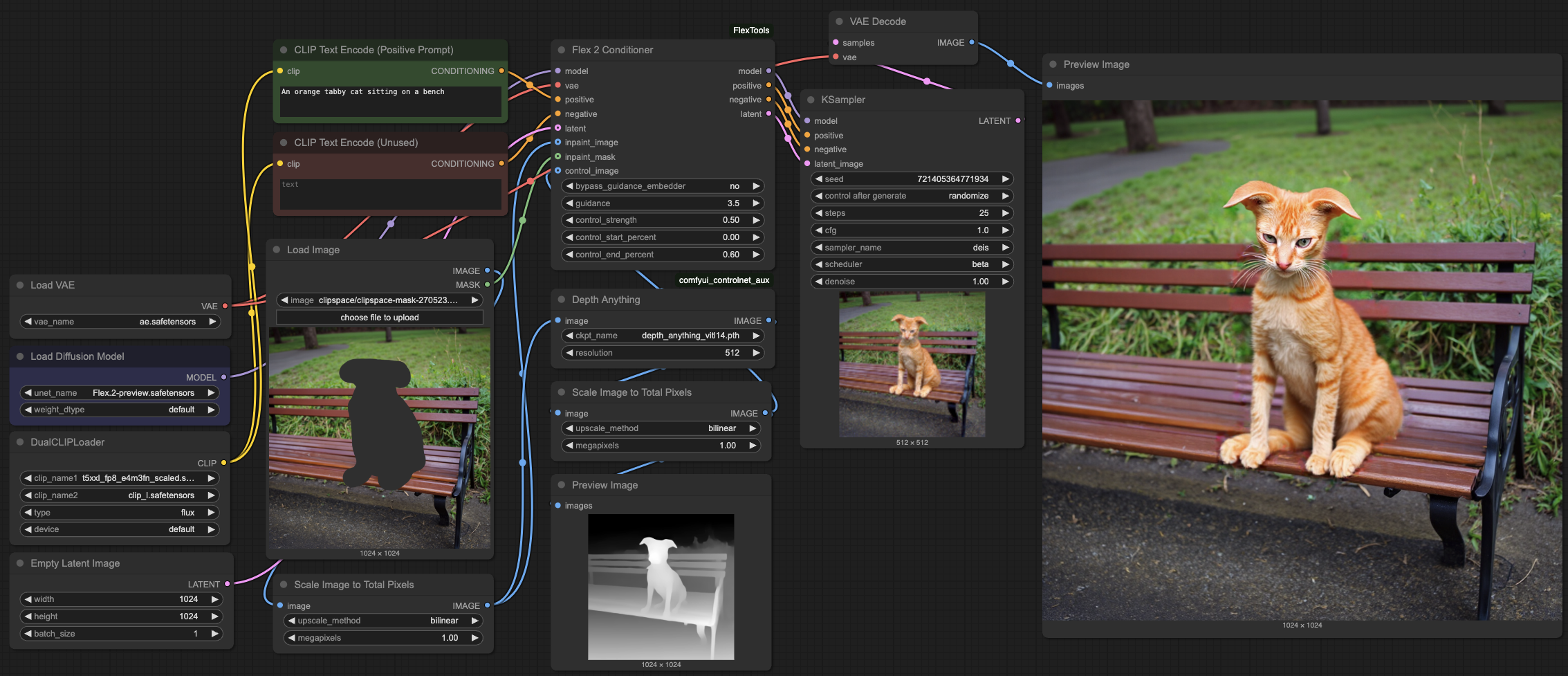
Usage steps:
- Install necessary tools and nodes
- Download Flex.2-preview.safetensors to your ComfyUI model directory
- Restart ComfyUI and start creating with the workflow
Diffusers Library Usage Example
In addition to ComfyUI, Flex.2 can also be used through the Diffusers library. Here's an example:

Limitations and Future Development
As a preview version, Flex.2 is still under active development, with room for improvement in the following areas:
- Accuracy of human anatomy
- Text rendering quality
- Refinement of inpainting functionality
The developer has indicated that they are continuously training to improve these limitations.
Fine-tuning and Customization
Flex.2 is designed to be fine-tunable. Users can use AI-Toolkit for LoRA training and automatically generate control and inpainting inputs for their own datasets.
You can even create your own control methods and teach the model to use them by training a simple LoRA, taking no more time than training a regular LoRA.
Related Links
If you want to try the latest image generation technology, Flex.2-preview offers a powerful and flexible open-source option that can meet various needs from simple creation to complex editing.
Comments
Sign in with GitHub to join the discussion.