Sand AI Releases MAGI-1: Autoregressive Video Generation at Scale
Sand AI has open-sourced MAGI-1, an autoregressive model that generates videos chunk by chunk, offering 24B and 4.5B parameter versions and supporting multiple video generation modes
Sand AI team officially open-sourced the MAGI-1 video generation model on April 21, with plans to release a 4.5B parameter version by the end of April. This is a world model capable of predicting video chunk sequences autoregressively, supporting Text-to-Video (T2V), Image-to-Video (I2V), and Video-to-Video (V2V) generation methods.
Technical Innovations
MAGI-1 employs multiple technical innovations that give it unique advantages in the field of video generation:
Transformer-based VAE
- Uses a Transformer-based variational autoencoder with 8x spatial and 4x temporal compression
- Features the fastest average decoding time while maintaining high-quality reconstruction
Autoregressive Denoising Algorithm
MAGI-1 generates videos in an autoregressive, chunk-by-chunk manner rather than all at once. Each chunk (24 frames) is denoised holistically, and the generation of the next chunk begins as soon as the current one reaches a certain level of denoising. This design enables concurrent processing of up to four chunks for efficient video generation.

Diffusion Model Architecture
MAGI-1 is built upon the Diffusion Transformer, incorporating several key innovations to enhance training efficiency and stability at scale. These advancements include Block-Causal Attention, Parallel Attention Block, QK-Norm and GQA, Sandwich Normalization in FFN, SwiGLU, and Softcap Modulation.
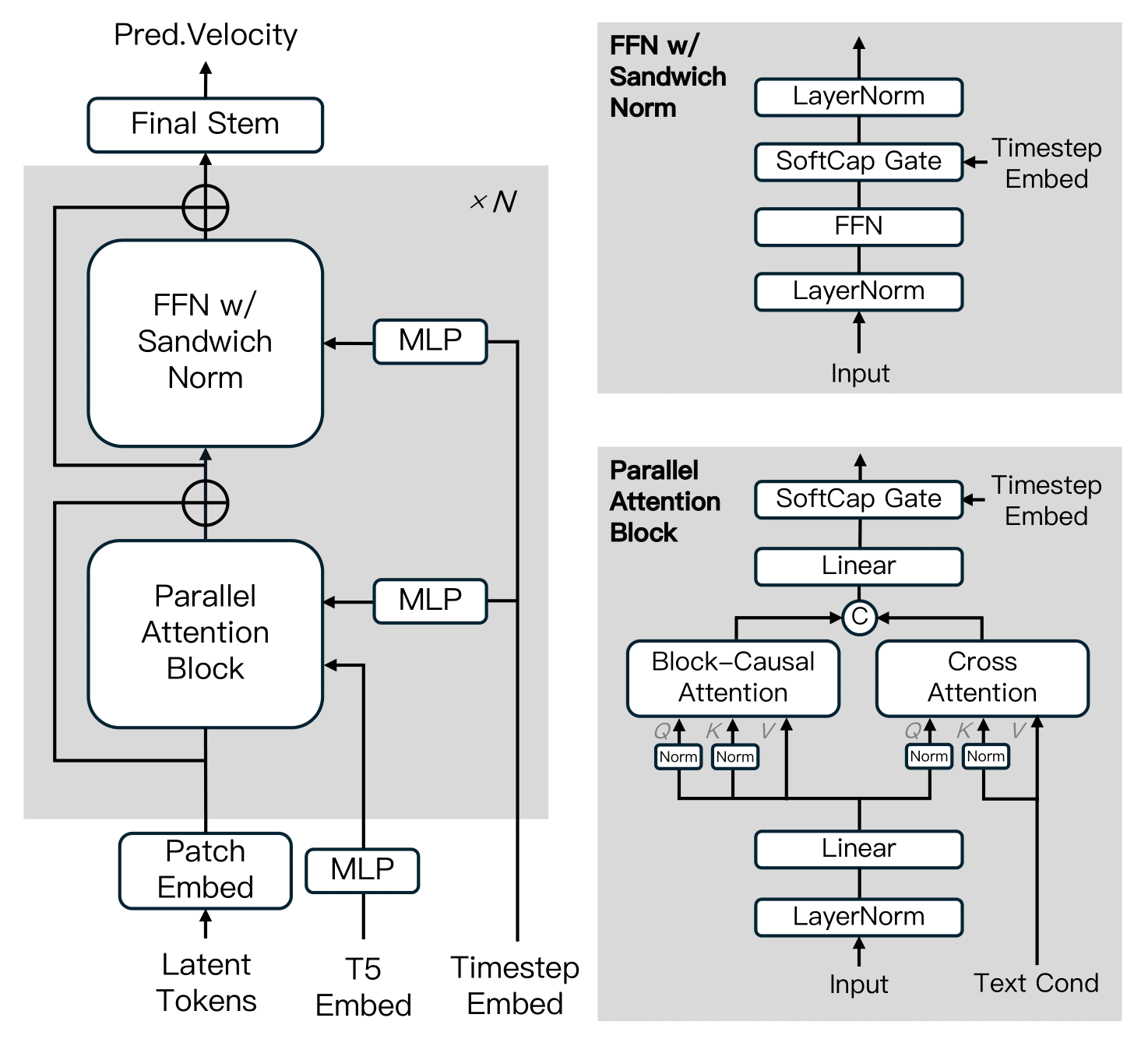
Distillation Algorithm
The model adopts a shortcut distillation approach that trains a single velocity-based model to support variable inference budgets. By enforcing a self-consistency constraint—equating one large step with two smaller steps—the model learns to approximate flow-matching trajectories across multiple step sizes. During training, step sizes are cyclically sampled from 64, 32, 16, 8, and classifier-free guidance distillation is incorporated to preserve conditional alignment. This enables efficient inference with minimal loss in fidelity.
Model Versions
Sand AI provides pre-trained weights for multiple versions of MAGI-1, including 24B and 4.5B models, as well as corresponding distilled and quantized models:
| Model | Recommended Hardware | |
-- |
- | | MAGI-1-24B | H100/H800 × 8 | | MAGI-1-24B-distill | H100/H800 × 8 | | MAGI-1-24B-distill+fp8_quant | H100/H800 × 4 or RTX 4090 × 8 | | MAGI-1-4.5B | RTX 4090 × 1 |
Performance Evaluation
Physical Evaluation
Thanks to the natural advantages of autoregressive architecture, MAGI-1 achieves far superior precision in predicting physical behavior on the Physics-IQ benchmark through video continuation.
In Physics-IQ scoring, MAGI's Video-to-Video (V2V) mode achieves 56.02 points, while its Image-to-Video (I2V) mode reaches 30.23 points, significantly outperforming other open-source and closed-source commercial models such as VideoPoet, Kling1.6, and Sora.
How to Run
MAGI-1 supports running through either Docker environment (recommended) or source code. Users can flexibly control input and output by adjusting parameters in the run.sh script to meet different requirements:
--mode: Specifies the operation mode (t2v, i2v, or v2v)--prompt: The text prompt used for video generation--image_path: Path to the image file (used only in i2v mode)--prefix_video_path: Path to the prefix video file (used only in v2v mode)--output_path: Path where the generated video file will be saved
Comments
Sign in with GitHub to join the discussion.