Pixel-Reasoner: Open-Source Pixel-Level Visual Reasoning Model Released
Pixel-Reasoner, based on Qwen2, offers global and local pixel-level visual understanding and reasoning, supports detailed zoom-in analysis, and advances visual language models.
Pixel-Reasoner is an open-source visual language model based on Qwen2, focusing on enhancing pixel-level visual understanding and reasoning. The model can analyze the entire image globally and also supports zooming in on local areas for detailed observation, helping to capture fine details in images.
Main Features
- Pixel-level reasoning: Pixel-Reasoner can reason directly in the pixel space of images, not limited to traditional text-based reasoning.
- Combining global and local understanding: The model can grasp the overall content of an image and also "zoom in" to focus on specific areas for more detailed analysis.
- Curiosity-driven training: By introducing a curiosity reward mechanism, the model is encouraged to actively explore and use pixel-level operations, improving the diversity and accuracy of visual reasoning.
- Open-source availability: The model, datasets, and related code are all open-source, making it easy for the community to download and try.
A New Paradigm for Pixel-Level Reasoning
Pixel-Reasoner introduces a new concept of "Pixel-Space Reasoning." Unlike traditional visual language models that rely only on text reasoning, Pixel-Reasoner can analyze and operate directly at the pixel level of images.
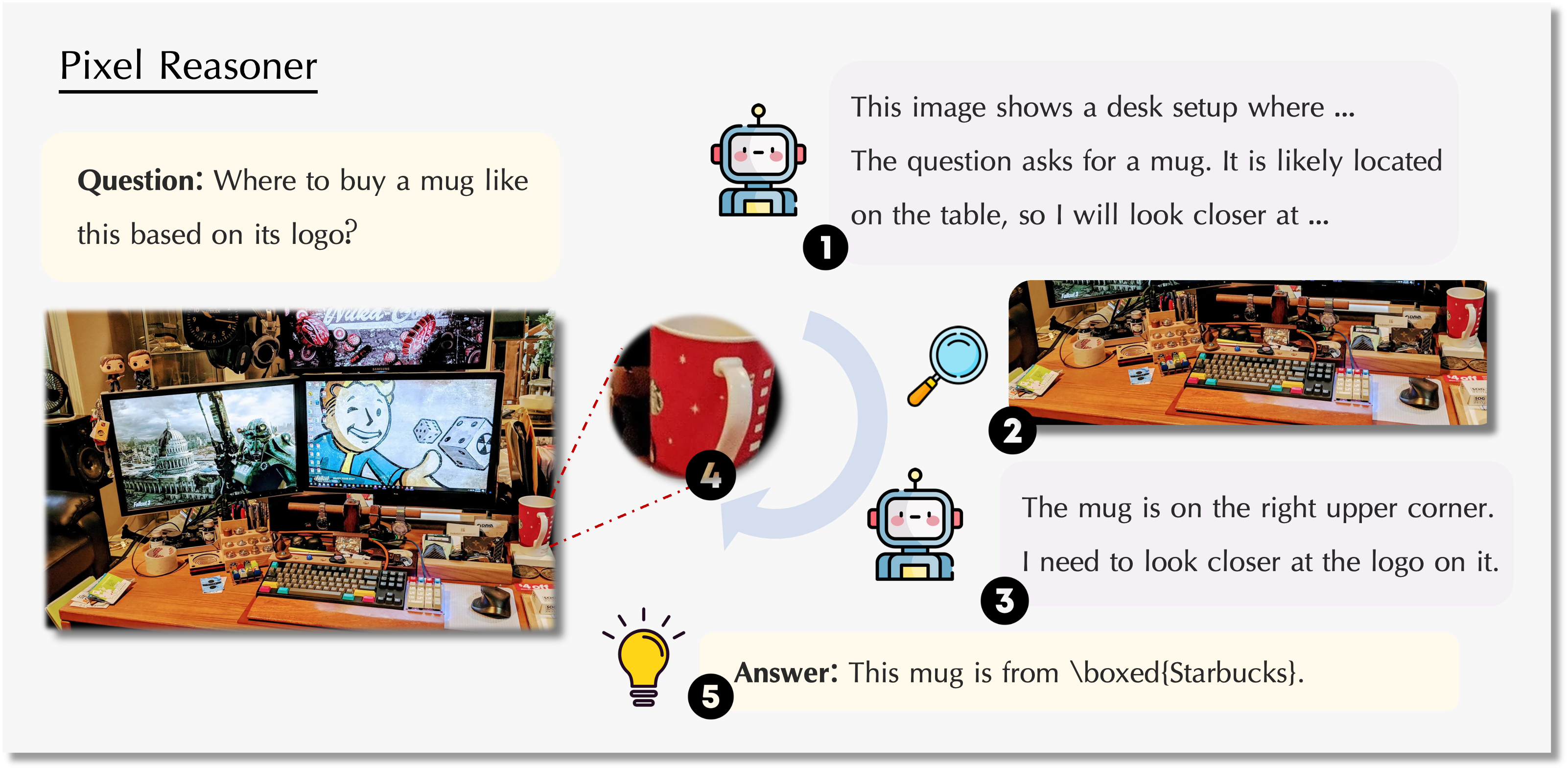 As shown above, the model can understand the whole image and also zoom in or select areas to focus on details, improving its ability to understand complex visual content.
As shown above, the model can understand the whole image and also zoom in or select areas to focus on details, improving its ability to understand complex visual content.
Training Challenges and Innovative Mechanisms
During training, the team found that existing visual language models face a "learning trap" in pixel-level reasoning—they are better at text reasoning and tend to fail at pixel-level operations, lacking motivation to explore visual actions.
 The image above shows the bottleneck encountered in early pixel-space reasoning: due to limited initial ability, the model tends to avoid visual operations, which affects the development of pixel-level reasoning skills.
The image above shows the bottleneck encountered in early pixel-space reasoning: due to limited initial ability, the model tends to avoid visual operations, which affects the development of pixel-level reasoning skills.
To address this, Pixel-Reasoner uses a curiosity-driven reinforcement learning mechanism, rewarding the model for actively trying pixel-level operations and gradually improving its reasoning ability in the visual space.
Data Synthesis and Training Process
Pixel-Reasoner's training is divided into two stages:
- Instruction fine-tuning: Synthetic reasoning trajectories with visual operations help the model get familiar with various pixel-level actions.
- Curiosity-driven reinforcement learning: A reward mechanism encourages the model to actively explore and use visual operations during reasoning.
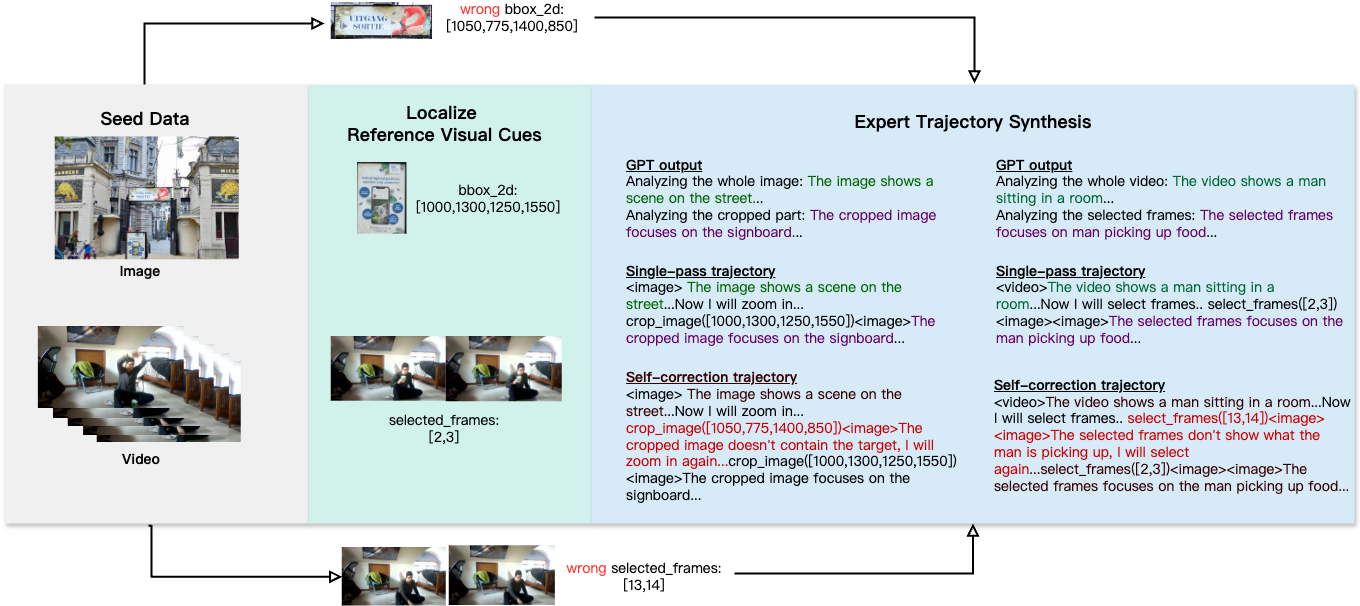 As shown above, the team uses high-resolution images and videos, combined with automatic and manual annotation, to generate diverse reasoning data, helping the model learn to analyze and self-correct in the visual space.
As shown above, the team uses high-resolution images and videos, combined with automatic and manual annotation, to generate diverse reasoning data, helping the model learn to analyze and self-correct in the visual space.
Typical Application Scenarios
Pixel-Reasoner is especially suitable for:
- Tasks that require identifying small objects or details in images
- Understanding multi-region, multi-level information in complex images or videos
- Visual reasoning tasks that combine global and local information
Application Scenarios
Pixel-Reasoner is ideal for scenarios requiring detailed visual understanding, such as:
- Analyzing complex images or video content
- Recognizing small objects, subtle relationships, or embedded text
- Visual tasks that combine global and local information
Related Links
- Paper: https://arxiv.org/abs/2505.15966
- Official Homepage: https://tiger-ai-lab.github.io/Pixel-Reasoner/
- HuggingFace Model: https://huggingface.co/TIGER-Lab/PixelReasoner-RL-v1
- Online Demo: https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
This article refers to official Pixel-Reasoner materials and papers.
Comments
Sign in with GitHub to join the discussion.