Open-Sora 2.0 Released: Commercial-Grade Video Generation at Low Cost
LuChen Technology releases Open-Sora 2.0 open-source video generation model, achieving performance close to top commercial models with just $200,000 in training costs
hpcaitech (the ColossalAI team) has officially released Open-Sora 2.0, an open-source video generation model with 11 billion parameters that has drawn widespread attention for balancing cost and performance. With only about $200,000 in training costs (equivalent to 224 GPUs), the model performs close to top commercial models in multiple evaluations.
Video Demonstrations






Note: The GIFs above are compressed. For original high-quality videos, please visit the official showcase page
Performance
In the authoritative VBench evaluation, the performance gap between Open-Sora 2.0 and OpenAI's Sora model has narrowed from 4.52% in the previous generation to just 0.69%, nearly achieving parity. User preference tests show that the model outperforms several competitors in visual quality (69.5% win rate), text consistency (55.6% win rate), and other metrics, performing comparably to commercial models like Tencent's HunyuanVideo (11B) and Step-Video (30B).
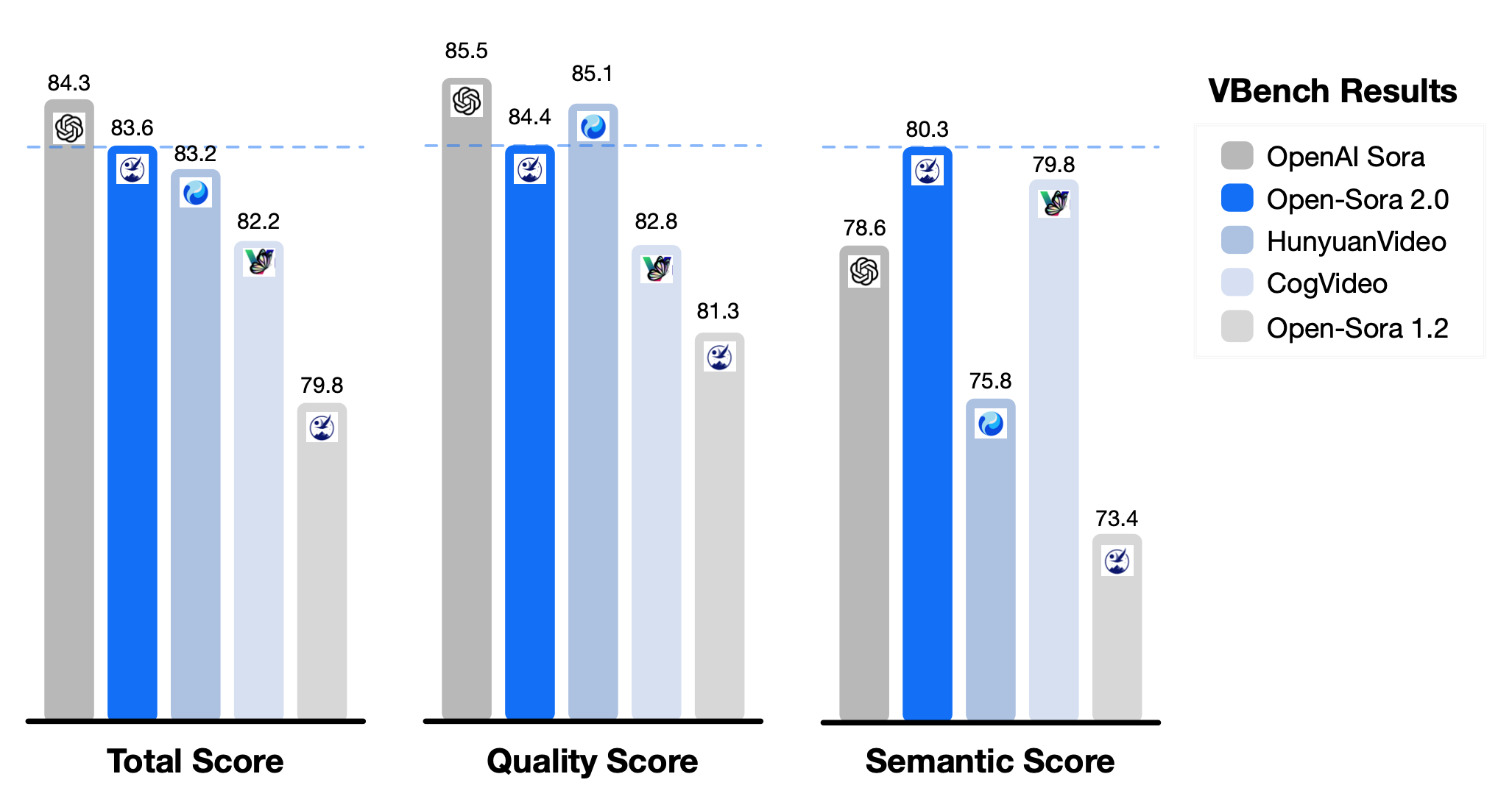
Performance comparison in VBench evaluation
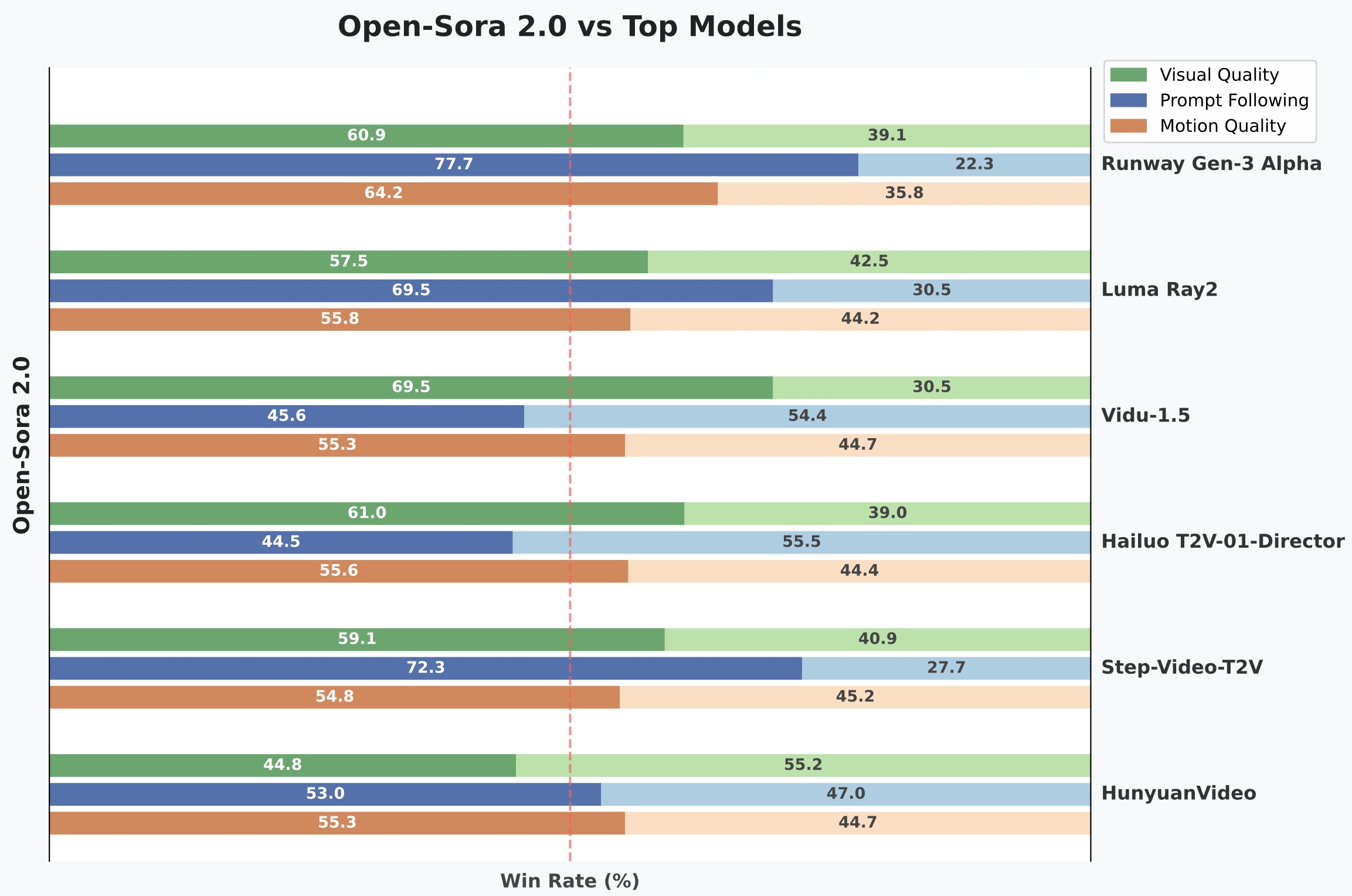
User preference test win rate comparison
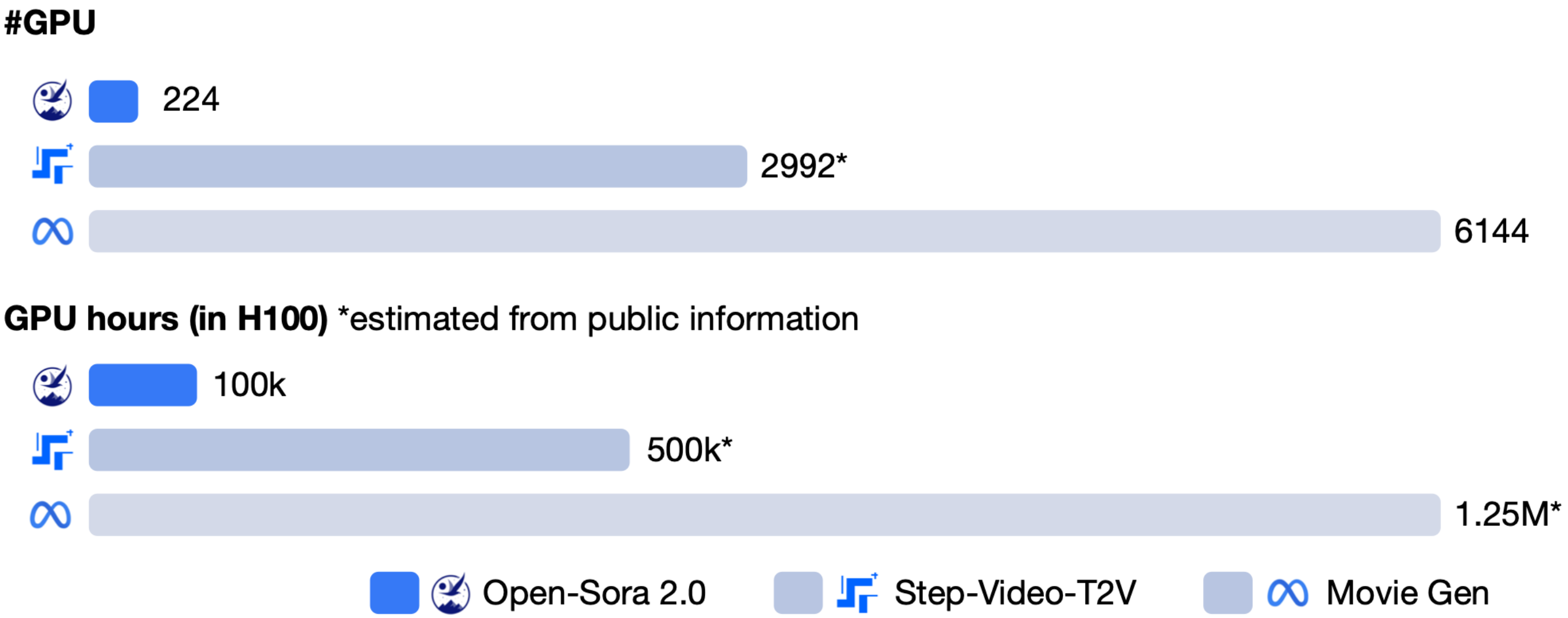
Model training cost comparison
Technical Innovations
Behind Open-Sora 2.0's high performance at low cost are several technical innovations:
- Efficient Model Architecture: Uses 3D full attention mechanisms and MMDiT architecture (Masked Motion Diffusion Transformer) to enhance spatiotemporal feature modeling
- Low-Resolution Priority Strategy: First learns motion features, then improves quality through Text-to-Image-to-Video (T2I2V), saving 40x computing resources
- Parallel Training Framework: Leverages ColossalAI parallel framework, combined with ZeroDP, Gradient Checkpointing and other technologies, achieving 99% GPU utilization
- High-Compression Autoencoder: Reduces 768px video generation time from 30 minutes to 3 minutes, a 10x speed improvement
Value to the Open Source Ecosystem
As a full-stack open source project, Open-Sora 2.0 has publicly released its model weights, training code (including data preprocessing and distributed optimization), and technical reports on GitHub. The model supports various application scenarios:
- Film Previsualization: Generating storyboards and special effects prototypes
- Advertising Creativity: Quickly producing videos with multiple scenes
- Educational Content: Dynamically demonstrating physical principles
- Game Development: Automatically generating NPC behavior animations and scene transition effects
The project has received over a hundred paper citations within six months and attracted ecosystem contributions from multiple companies, including NVIDIA, providing significant momentum for the popularization of video generation technology.
Practical Features
Open-Sora 2.0 offers a rich set of practical features:
Multiple Resolution and Aspect Ratio Support
Supports 256px and 768px resolutions, capable of handling videos with different aspect ratios including 16:9, 9:16, 1:1, and 2.39:1.
Multiple Generation Modes
- Text-to-Video: Generates videos that match written descriptions
- Image-to-Video: Transforms static images into videos with dynamic effects
- Motion Intensity Control: Adjusts the amplitude of movement in videos through the Motion Score parameter (1-7 points)



Motion scores from left to right: 1, 4, and 7
Efficient Inference
The model runs efficiently on high-end GPUs (such as H100/H800):
- 256×256 resolution video generation: approximately 60 seconds on a single GPU
- 768×768 resolution video generation: approximately 4.5 minutes with 8 GPUs in parallel
Availability and Usage
The model is available for download on the following platforms:
Future Development
The hpcaitech team states that Open-Sora will continue to improve with:
- Support for 4K resolution and videos longer than 1 minute
- Exploration of multimodal capabilities (synchronized audio generation, cross-modal editing)
- Further reduction in training and inference costs
This breakthrough is expected to significantly lower the barriers to video content creation and promote the application of AI video tools across a broader range of fields.
Comments
Sign in with GitHub to join the discussion.