Sesame Unveils CSM Voice Model for Natural Conversations
ComfyUI Wikinews
Sesame Research introduces dual-Transformer conversational voice model CSM, achieving human-like interaction with open-source core architecture
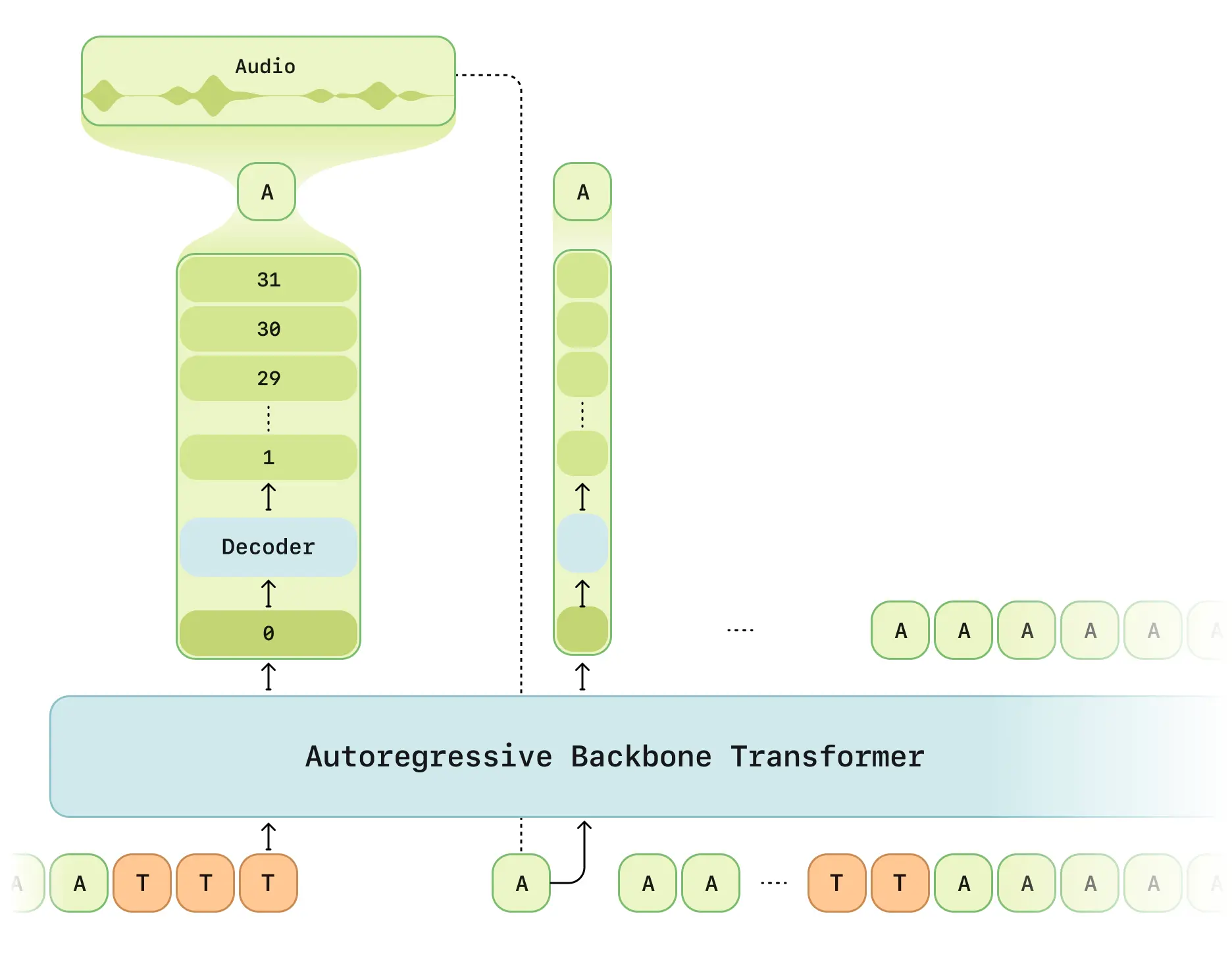
Sesame Research's Conversational Speech Model (CSM) demonstrates breakthrough capabilities in official demo. The dual-Transformer architecture enables near-human voice interactions.
Technical Architecture
Core design features:
- Dual-stage Processing: Multimodal backbone (text/speech) + audio decoder
- RVQ Tokenizer: Mimi discrete quantizer at 12.5Hz frame rate
- Latency Optimization: Solves traditional RVQ generation delays
- Computation Scheduling: 1/16 frame sampling for efficiency
- Llama Framework: LLaMA-based backbone network
Key Features
- Context Awareness: 2-minute conversation memory (2048 tokens)
- Emotional Intelligence: 6-layer emotion classifier
- Real-time Interaction: < 500ms end-to-end latency (avg 380ms)
- Multi-speaker Support: Simultaneous voice processing
Technical Specifications
| Parameter | Details | |
--|
--| | Training Data | 1M hours English conversations | | Model Scale | 8B backbone + 300M decoder | | Sequence Length | 2048 tokens (~2 minutes) | | Hardware Support| RTX 4090 or higher |
Open Source Status
GitHub Repository includes:
- Complete architecture whitepaper
- REST API examples
- Audio preprocessing toolkit
- Model quantization guide
⚠️ Limitations:
- Core training code not released (Q3 2025 planned)
- API key required
- English-first implementation
Evaluation Results
Official benchmarks show:
- Naturalness: CMOS score matches human recordings
- Context Understanding: 37% accuracy improvement
- Pronunciation Consistency: 95% stability
- Latency: 68% first-frame generation improvement
Technical sources: Research Paper | X
Comments
Sign in with GitHub to join the discussion.