Kunlun Wanwei Releases SkyReels-V2 Infinite-Length Film Generative Model
Kunlun Wanwei's SkyReels team releases and open-sources SkyReels-V2, the world's first infinite-length film generative model using Diffusion Forcing framework, capable of producing high-quality, long-duration video content
![]()
Kunlun Wanwei Releases SkyReels-V2 Infinite-Length Film Generative Model
On April 21, Kunlun Wanwei's SkyReels team officially released and open-sourced SkyReels-V2—the world's first infinite-length film generative model using Diffusion Forcing framework. By combining multimodal large language models (MLLM), multi-stage pretraining, reinforcement learning, and the Diffusion Forcing framework, this model achieves collaborative optimization and can generate high-quality videos of 30 seconds, 40 seconds, or even longer.
🎥 Demonstrations
The demonstrations above showcase 30-second videos generated using the SkyReels-V2 Diffusion Forcing model.
Technical Innovations
SkyReels-V2 achieves high-quality video generation through several technical innovations:
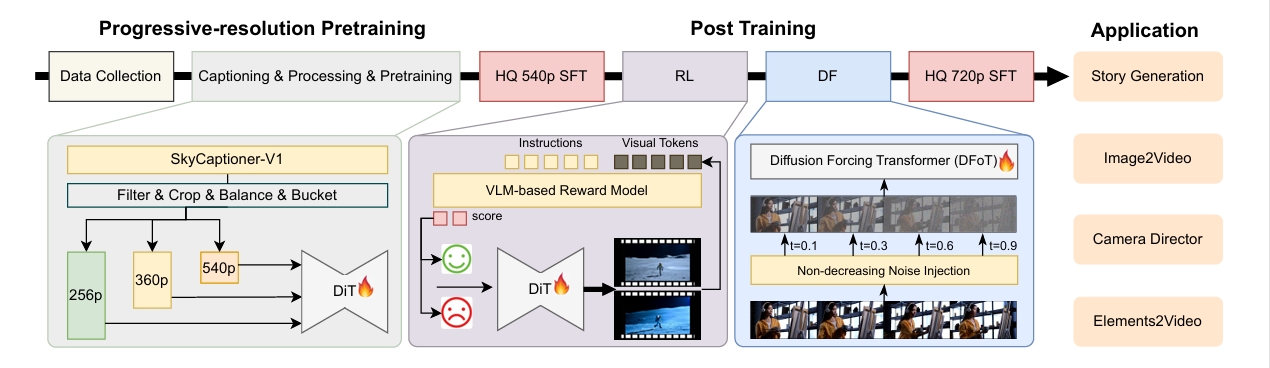
1. Cinematic-Grade Video Understanding Model: SkyCaptioner-V1
The team designed a structured video representation method that combines general descriptions from multimodal LLMs with detailed shot language from sub-expert models. This method identifies subject types, appearances, expressions, actions, and positions in videos.
SkyCaptioner-V1 efficiently understands video data and generates diverse descriptions aligned with the original structural information. It not only comprehends general video content but also captures professional cinematographic language in film scenes, significantly improving prompt adherence in generated videos. This model is now open-sourced and available for direct use.
2. Motion Preference Optimization
Through reinforcement learning training using human annotation and synthetic distortion data, the team addressed issues of dynamic distortion and unrealistic motion in existing video generation models. They designed a semi-automatic data collection pipeline to efficiently generate preference comparison data pairs.
This approach allows SkyReels-V2 to excel in motion dynamics, generating fluid and realistic video content that meets the demands for high-quality motion.
3. Efficient Diffusion Forcing Framework
To achieve long video generation capabilities, the team proposed a Diffusion Forcing post-training method. By fine-tuning pre-trained diffusion models and converting them to Diffusion Forcing models, they not only reduced training costs but also significantly improved generation efficiency.
The team adopted a non-decreasing noise time schedule, reducing the search space for continuous frame denoising schedules from O(1e48) to O(1e32), enabling efficient generation of long videos.
4. Progressive Resolution Pretraining and Multi-Stage Post-Training Optimization
To develop a professional film generation model, the team's multi-stage quality assurance framework integrated data from three main sources: general datasets, self-collected media, and art resource libraries.
Building on this data foundation, the team first established a base video generation model through progressive resolution pretraining, followed by four stages of subsequent training enhancements: initial concept-balanced supervised fine-tuning, motion-specific reinforcement learning training, Diffusion Forcing framework, and high-quality SFT.
Performance
SkyReels-V2 demonstrates excellent performance in multiple evaluations:
-
In the SkyReels-Bench T2V multi-dimensional human evaluation, SkyReels-V2 achieved the highest standards in instruction adherence (3.15) and consistency (3.35), while maintaining first-tier performance in video quality (3.34) and motion quality (2.74).
-
In VBench1.0 automated evaluation, SkyReels-V2 outperformed all comparison models with the highest total score (83.9%) and quality score (84.7%), including HunyuanVideo-13B and Wan2.1-14B.
Application Scenarios
SkyReels-V2 provides powerful support for multiple practical application scenarios:
-
Story Generation: Capable of generating theoretically infinite-length videos using a sliding window method and stabilization techniques to create long shots with coherent narratives.
-
Image-to-Video Synthesis: Offers two methods for image-to-video generation, outperforming other open-source models across all quality dimensions and comparable to closed-source models.
-
Camera Director Functionality: Through specially selected samples and fine-tuning experiments, significantly improves photographic effects, especially in camera movement fluidity and diversity.
-
Element-to-Video Generation: Based on the SkyReels-V2 foundation model, the SkyReels-A2 solution can combine arbitrary visual elements into coherent videos guided by text prompts.
Open-Source Models
The Kunlun Wanwei SkyReels team has fully open-sourced SkyCaptioner-V1 and the SkyReels-V2 series models (including Diffusion Forcing, text-to-video, image-to-video, camera director, and element-to-video models) in various sizes (1.3B, 5B, 14B) to promote further research and applications in academia and industry.
Comments
Sign in with GitHub to join the discussion.