ByteDance Releases USO: Unified Style and Subject-Driven Image Generation Model
ByteDance launches the USO model, capable of freely combining any subject with any style while maintaining subject consistency and achieving high-quality style transfer effects

The UXO team of ByteDance's Intelligent Creation Lab has released USO (Unified Style and Subject-Driven Generation), a customized generation model that unifies style and subject optimization. USO can freely combine any subject with any style, achieving high-quality style transfer effects while maintaining subject consistency.
Model Features
The USO model addresses the issue in existing technologies where style-driven and subject-driven generation tasks are opposed to each other. Traditional methods typically treat these two tasks as independent tasks: style-driven generation prioritizes style similarity, while subject-driven generation emphasizes subject consistency, leading to an obvious antagonistic relationship between the two.
USO solves this problem through a unified framework, with decoupling and recombination of content and style as its core goal. The model adopts a two-stage training method:
Stage One: Align SigLIP embeddings through style alignment training to obtain a model with style capabilities Stage Two: Decouple the conditional encoder and train on triplet data to achieve joint conditional generation
Core Functions
The USO model supports multiple generation modes, enabling free combination of any subject with any style:
Subject-Driven Generation
Maintains subject identity consistency, suitable for stylizing specific subjects such as people and objects. Users can provide a reference image containing a specific subject, and the model will maintain the subject's identity characteristics while applying new styles or scenes.
Identity-Driven Generation
Performs stylization while maintaining identity characteristics. This mode is particularly suitable for portrait stylization, as it can maintain facial features, expressions, and identity information while changing artistic styles, clothing, or background environments.
Style-Driven Generation
Achieves high-quality style transfer by applying the style of reference images to new content. Users can provide a style reference image, and the model will apply this artistic style to text-described content, creating new images with specific styles.
Multi-Style Mixed Generation
Supports the fusion application of multiple styles. Users can simultaneously provide multiple reference images with different styles, and the model will fuse these style elements together to create unique mixed style effects.
Joint Style-Subject Generation
Simultaneously controls subject and style to achieve complex creative expressions. This mode combines the advantages of subject-driven and style-driven generation, allowing users to specify both specific subjects and control artistic styles for more precise creative control.
Working Principle
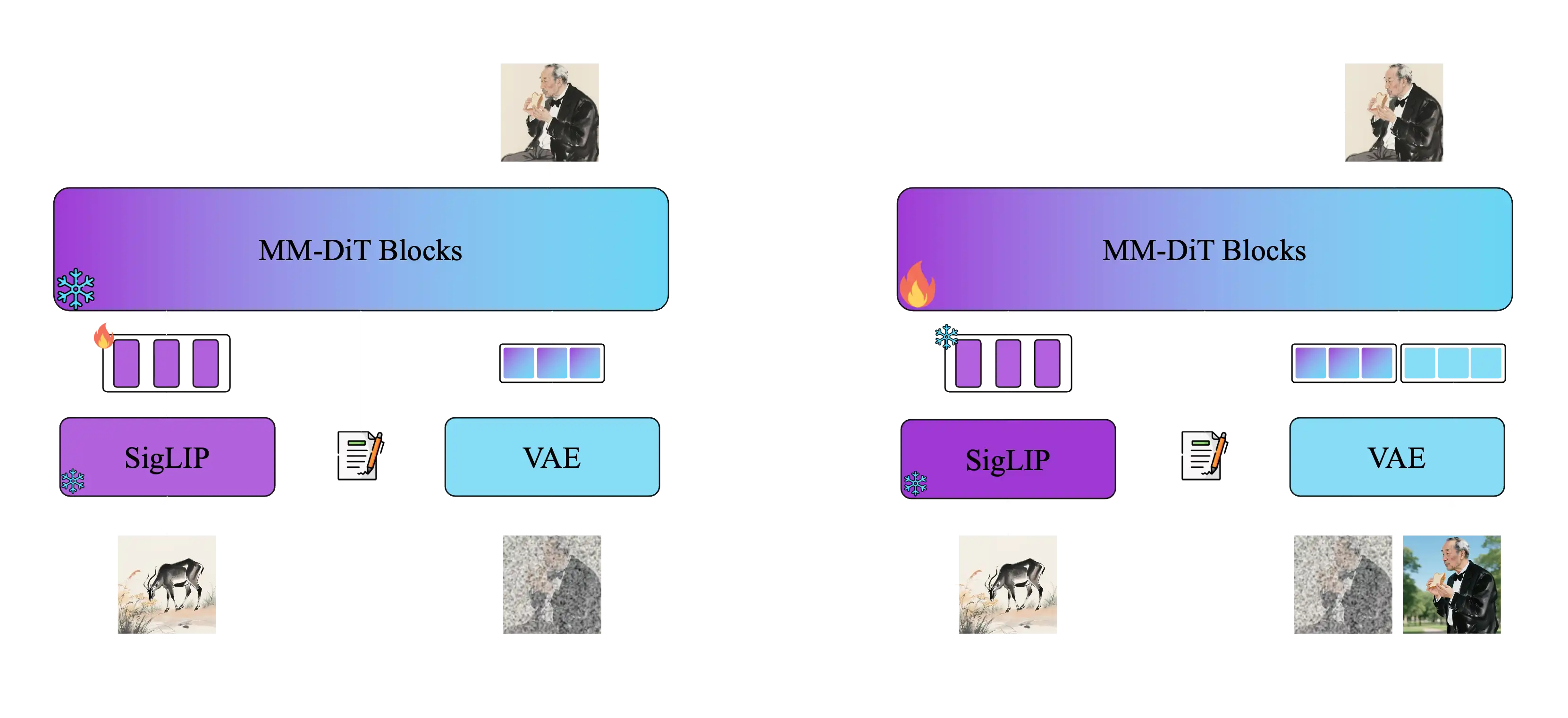
USO adopts a two-stage training method: the first stage aligns SigLIP embeddings through style alignment training to obtain a model with style capabilities; the second stage decouples the conditional encoder and trains on triplet data to achieve joint conditional generation. Finally, the style reward learning paradigm supervises both stages to obtain a stronger unified model.
Comparison with Other Methods
Subject-Driven Generation Comparison

Style-Driven Generation Comparison

Identity-Driven Generation Comparison

Joint Style-Subject Generation Comparison

Dataset and Training
The research team constructed a large-scale triplet dataset containing content images, style images, and their corresponding stylized content images. Through a decoupling learning scheme, the model can simultaneously handle two objectives: style alignment and content-style decoupling.
Performance
Experimental results show that USO achieves the best performance in both subject consistency and style similarity dimensions among open-source models. The model can generate natural, non-plastic portraits while maintaining high subject consistency and strong style fidelity.
The research team also released the USO-Bench benchmark test, which is the first multi-metric benchmark that simultaneously evaluates style similarity and subject fidelity, providing a standardized evaluation tool for related research.
Open Source and Usage
Project Links:
The release of USO brings new solutions to the field of AI image generation, particularly in balancing style transfer and subject preservation. The open-sourcing of this model will advance related research and provide powerful tool support for the open-source community.
Comments
Sign in with GitHub to join the discussion.