Kuaishou Introduces CineMaster: Breakthrough in 3D-Aware Video Generation
Kuaishou officially releases CineMaster text-to-video generation framework, enabling high-quality video content creation through 3D-aware technology
Kuaishou has recently unveiled CineMaster, a groundbreaking text-to-video generation framework, marking a significant milestone in video creation. This framework features powerful 3D awareness capabilities and is hailed as the video version of ControlNet, offering creators unprecedented precise control over video elements, including position, motion trajectories, and 3D spatial layouts.
Technical Innovations in CineMaster
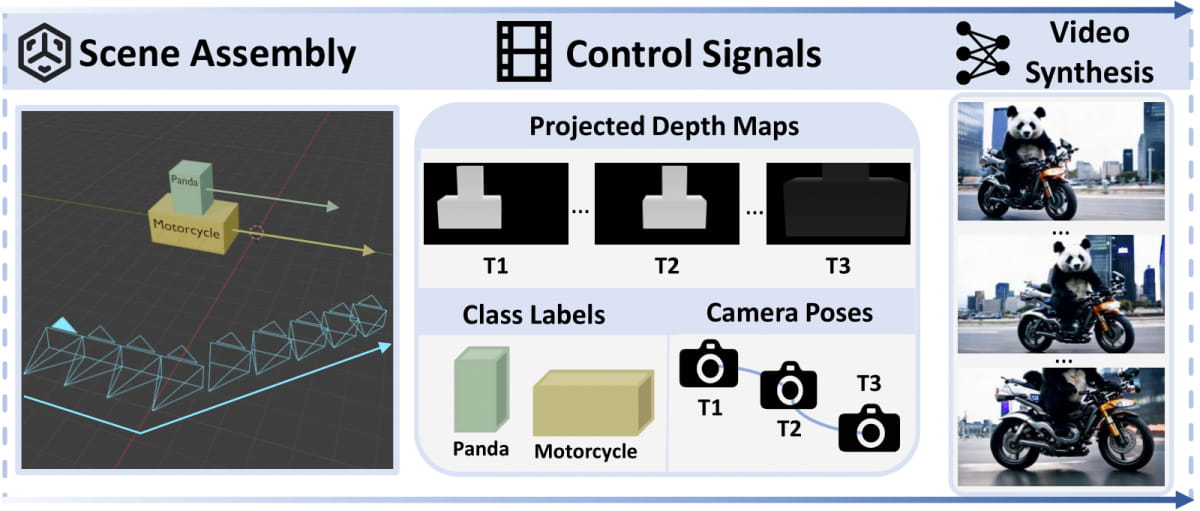
CineMaster employs an innovative two-stage framework design:
CineMaster Framework Highlights
The core strength of CineMaster lies in its high controllability over video generation. Users can not only create fully controllable video content but also extract 3D information from videos for secondary creation and editing, enabling style transfer. This makes CineMaster a powerful creative tool that allows users to precisely place objects and flexibly adjust camera angles in 3D space.
Precise Control of Object and Camera Motion
CineMaster enables creators to precisely control object positions and camera trajectories through multiple control signals. This means users can generate dynamic scenes and embed complex 3D elements, providing unprecedented creative freedom in video production.
CineMaster's Two-Stage Workflow
CineMaster operates in two stages:
-
Interactive Workflow: Users intuitively build control signals by positioning object bounding boxes and defining camera movements in 3D space. This stage provides an intuitive and user-friendly 3D-aware environment.
-
Control Signal Generation: The control signals generated in the first stage (including depth maps, camera trajectories, and object category labels) are fed into the text-to-video diffusion model to guide the generation of video content that meets user requirements.
Dataset Annotation Pipeline
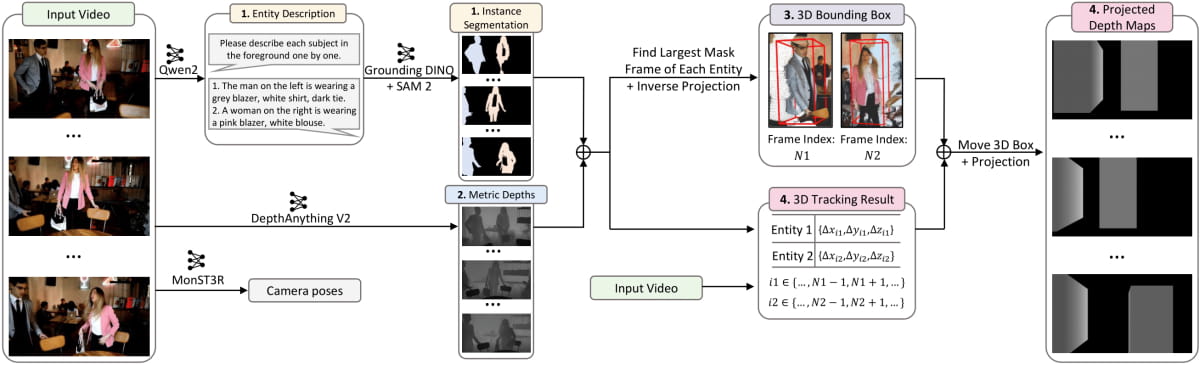
To overcome the scarcity of 3D box and camera pose annotation data, Kuaishou built an automated data annotation pipeline to extract 3D bounding boxes and camera trajectories from large-scale video data. This pipeline includes the following steps:
- Instance Segmentation: Extract instance segmentation results from video foreground.
- Depth Estimation: Generate metric depth maps using DepthAnything V2.
- 3D Point Cloud and Box Computation: Calculate 3D point clouds for each entity through inverse projection and compute 3D bounding boxes using minimum volume method.
- Entity Tracking and 3D Box Adjustment: Calculate 3D bounding boxes per frame through point tracking and project the entire 3D scene onto depth maps.
Performance Surpassing Existing Methods
CineMaster demonstrates excellent performance in extensive qualitative and quantitative experiments, significantly outperforming existing methods, particularly in three scenarios: moving objects with static cameras, static objects with moving cameras, and moving objects with moving cameras. CineMaster shows superior control capabilities in flexibly generating various complex scenes according to user requirements.
Technical Architecture and Innovation
CineMaster's framework innovatively adopts a Semantic Layout ControlNet. This architecture includes a Semantic Injector and a DiT-based ControlNet. The Semantic Injector fuses 3D spatial layouts and category labels to provide necessary control signals. The DiT-based ControlNet further processes these features and enhances the model's representation capabilities. Additionally, the Camera Adapter injects camera trajectories, enabling joint control of object and camera motion.
CineMaster provides creators with a highly flexible and controllable text-to-video generation platform, bringing unprecedented 3D creative freedom. As the technology continues to iterate and optimize, CineMaster is poised to lead new trends in video creation and editing, offering users a richer and more refined creative experience.
Project Open Source Status
- No open source content available yet
CineMaster Links
Project Page: https://cinemaster-dev.github.io/ Paper: https://arxiv.org/pdf/2502.08639
Comments
Sign in with GitHub to join the discussion.