ComfyUI HiDream-I1 fp8, gguf, nf4 Text-to-Image Workflow Example - Complete Guide
This tutorial includes examples of workflows for different versions of HiDream I1.

HiDream-I1 is a text-to-image model officially open-sourced by HiDream-ai on April 7, 2025, with a parameter scale of 17B.
License Type Released under the MIT License, it supports use for personal projects, scientific research, and commercial purposes. The model has performed well in multiple benchmark tests.
In this article, we will cover the following:
- A brief introduction to HiDream-I1
- Information on different versions of the HiDream-I1 model available in the community and their support
- Workflows for different model versions
Since the full version of this model has high VRAM requirements, you can choose a version suitable for your device from the community model section and learn about the corresponding workflows. Please remember to refer to this article Upgrading ComfyUI to the Latest Version to ensure that the corresponding nodes can function properly.
Introduction to HiDream-I1
Model Features
Hybrid Architecture Design Combining diffusion models (DiT) with a mixture of experts (MoE) architecture:
- The main body is based on the Diffusion Transformer (DiT), processing multimodal information through a dual-stream MMDiT module, while a single-stream DiT module optimizes global consistency.
- The dynamic routing mechanism flexibly allocates computational resources, enhancing the ability to handle complex scenes, and performs excellently in color restoration, edge processing, and other details.
Integration of Multimodal Text Encoders Integrates four text encoders:
- OpenCLIP ViT-bigG, OpenAI CLIP ViT-L (visual-semantic alignment)
- T5-XXL (long text parsing)
- Llama-3.1-8B-Instruct (instruction understanding) This combination achieves state-of-the-art performance in complex semantic parsing related to color, quantity, spatial relationships, etc., with significantly better support for Chinese prompts compared to similar open-source models.
Original Model Repository
HiDream-ai provides three versions of the HiDream-I1 model to meet different scenario needs. Below are the links to the original model repositories:
- Full version: 🤗 HiDream-I1-Full with 50 inference steps
- Distilled development version: 🤗 HiDream-I1-Dev with 28 inference steps
- Distilled fast version: 🤗 HiDream-I1-Fast with 16 inference steps
Community HiDream-I1 Model Versions
Currently, there are many variant versions of the HiDream-I1 model in the community. This is a collection of existing versions organized by ComfyUI-Wiki. However, due to some issues I encountered during testing, I will only provide the corresponding workflows.
Repackaged Versions from ComfyOrg
The ComfyOrg repository offers repackaged Full, Dev, and Fast versions, including both the full version and the fp8 version. The full version requires approximately 20GB of VRAM, while the fp8 version requires about 16GB of VRAM. We will use the native example to complete the workflow.
GGUF Version Models
The GGUF version models are provided by city96:
The repository contains multiple versions ranging from Q8 to Q2, with Q4 requiring approximately 12GB of VRAM and Q2 requiring about 8GB of VRAM. If you are unsure, you can start testing with the smallest version.
You will need to use the Unet loader(GGUF) node from ComfyUI-GGUF to load the models, and we will slightly modify the official nodes to complete the workflow.
NF4 Version Models
This version uses 4-bit quantization technology to reduce memory usage and can run with approximately 16GB of VRAM.
- HiDream-I1-Full-nf4
- HiDream-I1-Dev-nf4
- HiDream-I1-Fast-nf4
- Use the ComfyUI-HiDream-Sampler node to utilize the NF4 version models. This node was originally provided by lum3on.
The ComfyUI-HiDream-Sampler will download the models upon the first run and implement unofficial image-to-image functionality. We will also complete the corresponding examples in this document.
Shared Model Installation
The model files below will be used in several workflows, so we can start downloading them and refer to the model file storage locations. We will provide download links for the corresponding diffusion models in the relevant workflows.
Text Encoders:
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors This is a lightweight version of T5XXL, which you may already have.
- llama_3.1_8b_instruct_fp8_scaled.safetensors
VAE
- ae.safetensors This is the VAE model from Flux. If you have used Flux's workflow, you already have this file.
Diffusion Models We will guide you to download the corresponding model files in the relevant workflows.
Model file storage locations
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 text_encoders/
│ │ ├─── clip_l_hidream.safetensors
│ │ ├─── clip_g_hidream.safetensors
│ │ ├─── t5xxl_fp8_e4m3fn_scaled.safetensors
│ │ └─── llama_3.1_8b_instruct_fp8_scaled.safetensors
│ └── 📂 vae/
│ │ └── ae.safetensors
│ └── 📂 diffusion_models/
│ └── ... # Will be guided to install in the corresponding version of the workflowComfyUI Native HiDream-I1 Workflow
The native workflow has been detailed in the official documentation I wrote for Comfy, titled ComfyUI Native HiDream-I1 Workflow Example. However, since the official documentation currently only supports Chinese and English, I will also provide corresponding examples in this guide, considering the multilingual support of ComfyUI Wiki.
In the official documentation, I have written complete workflows for the full, dev, and fast versions. These three workflows generally use the same models and workflows, with only some parameters and models differing. Therefore, we will only use one version of the workflow here and supplement the relevant settings for the other two versions to avoid excessive repetition in this document.
1. Workflow File Download
Please download the image below and drag it into ComfyUI to load the corresponding workflow. The file contains embedded model download information, and ComfyUI will check if the corresponding model files exist in the first-level subdirectories. However, it cannot check if model files exist in second-level subdirectories like ComfyUI/models/text_encoders/hidream/.
If you have already downloaded the corresponding models, you can ignore the prompts. The workflow below uses the hidream_i1_dev_fp8.safetensors model. If you need to use other versions, please refer to the manual model download section to download the corresponding models.

Download the JSON format workflow
2. Manual Model Download
Below are the model files for different versions of HiDream-I1. You can choose the appropriate version based on your VRAM capacity and save it in the ComfyUI/models/diffusion_models/ folder.
| Model Name | Version | Precision | File Size | VRAM Requirement | Download Link |
|---|---|---|---|---|---|
| hidream_i1_full_fp16.safetensors | full | fp16 | 34.2 GB | 20GB | Download Link |
| hidream_i1_dev_bf16.safetensors | dev | bf16 | 34.2 GB | 20GB | Download Link |
| hidream_i1_fast_bf16.safetensors | fast | bf16 | 34.2 GB | 20GB | Download Link |
| hidream_i1_full_fp8.safetensors | full | fp8 | 17.1 GB | 16GB | Download Link |
| hidream_i1_dev_fp8.safetensors | dev | fp8 | 17.1 GB | 16GB | Download Link |
| hidream_i1_fast_fp8.safetensors | fast | fp8 | 17.1 GB | 16GB | Download Link |
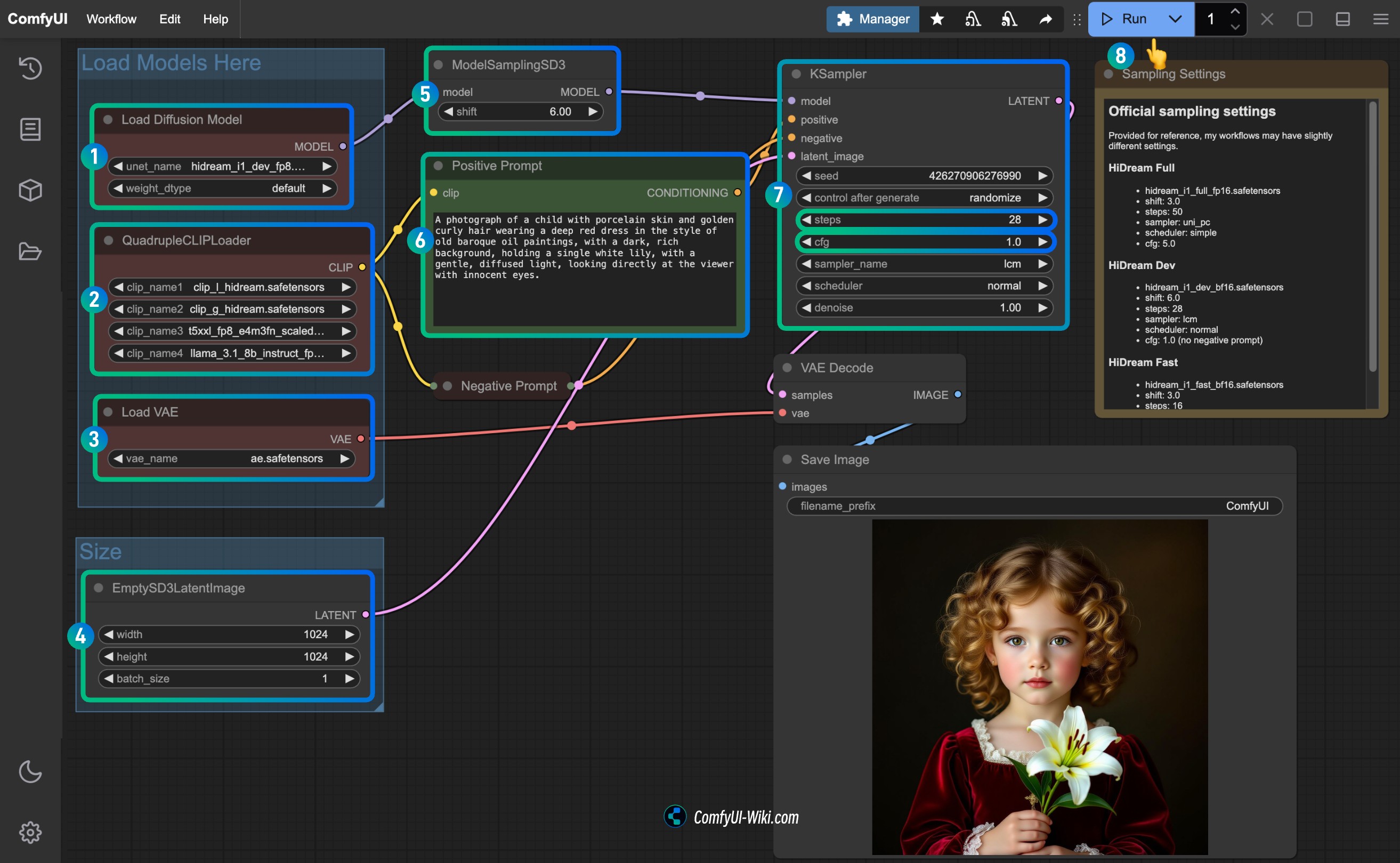
Follow the steps to run the workflow
- Ensure that the
Load Diffusion Modelnode is using thehidream_i1_dev_fp8.safetensorsor the version you downloaded. - Ensure that the four corresponding text encoders in the
QuadrupleCLIPLoaderare loaded correctly:- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- Ensure that the
Load VAEnode is using theae.safetensorsfile. - For the dev version, you need to set the
shiftparameter inModelSamplingSD3to3.0for the full version,6.0for the dev version, and3.0for the fast version. - For the
Ksamplernode, you need to set it according to the version of the model you downloaded:steps:50for the full version,28for the dev version,16for the fast version.cfg: set to5.0for the full version,1.0for the dev version, and1.0for the fast version (the dev and fast versions do not have negative prompts).- (Optional) Set
samplertolcm. - (Optional) Set
schedulertonormal.
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the image generation.
4. Parameter settings for different HiDream-I1 version models
HiDream Full
- Model file: hidream_i1_full_fp16.safetensors
ModelSamplingSD3nodeshiftparameter: 3.0Ksamplernode:- steps: 50
- sampler: uni_pc
- scheduler: simple
- cfg: 5.0
HiDream Dev
- Model file: hidream_i1_dev_bf16.safetensors
ModelSamplingSD3nodeshiftparameter: 6.0Ksamplernode:- steps: 28
- sampler: lcm
- scheduler: normal
- cfg: 1.0 (no negative prompts)
HiDream Fast
- Model file: hidream_i1_fast_bf16.safetensors
ModelSamplingSD3nodeshiftparameter: 3.0Ksamplernode:- steps: 16
- sampler: lcm
- scheduler: normal
- cfg: 1.0 (no negative prompts)
HiDream-I1 GGUF Version Workflow
The GGUF version uses the GGUF version model provided by city96. We will slightly modify the official nodes to complete the workflow.
You need to install the ComfyUI-GGUF plugin or update the previously installed version, and use the Unet loader(GGUF) node to load the model. You can later load my workflow and use the ComfyUI-Manager's check for missing nodes feature to install the corresponding nodes, or refer to installing custom nodes for manual installation.
1. Manual Model Download
The ComfyUI workflow file model information embedding only supports embedding model information for .sft and .safetensors files, so for the GGUF version model, we need to manually download the model first.
The corresponding full, dev, and fast repositories provide multiple versions of model files from Q8 to Q2 for each version, and you can choose the appropriate version based on your VRAM situation and download it to the ComfyUI/models/diffusion_models/ folder.
For other required models, please refer to the shared model installation section.
2. Workflow File
Please download the image below and drag it into ComfyUI to load the corresponding workflow.

Download the workflow in JSON format.
3. Complete the Workflow Execution Step by Step
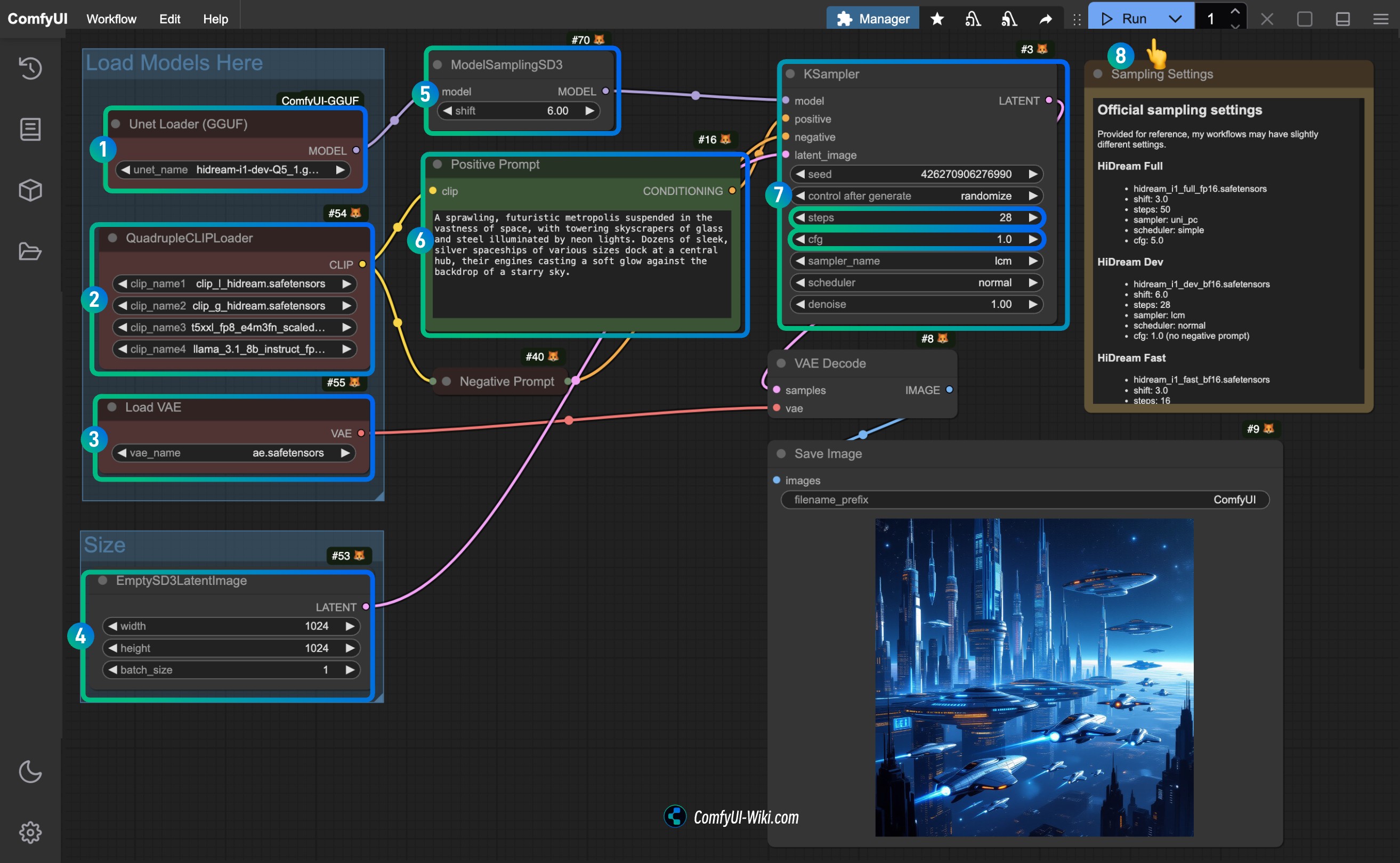
Since we only replaced the Load Diffusion Model node with the Unet loader(GGUF) node, everything else is completely consistent with the original workflow.
Follow the steps to complete the workflow execution:
- Ensure that the
Unet loader(GGUF)node is using the GGUF version model file you downloaded. - Ensure that the four corresponding text encoders in the
QuadrupleCLIPLoaderare loaded correctly:- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- t5xxl_fp8_e4m3fn_scaled.safetensors
- llama_3.1_8b_instruct_fp8_scaled.safetensors
- Ensure that the
Load VAEnode is using theae.safetensorsfile. - For the dev version, you need to set the
shiftparameter inModelSamplingSD3to3.0for the full version,6.0for the dev version, and3.0for the fast version. - For the
Ksamplernode, you need to set it according to the version of the model you downloaded:steps:50for the full version,28for the dev version,16for the fast version.cfg: set to5.0for the full version,1.0for the dev version, and1.0for the fast version (the dev and fast versions do not have negative prompts).- (Optional) Set
samplertolcm. - (Optional) Set
schedulertonormal.
- Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the image generation.
4. Parameter Settings for Different HiDream-I1 GGUF Version Models
Please refer to the original workflow section for settings.
HiDream-I1 NF4 Version Workflow
This version requires the installation of the ComfyUI-HiDream-Sampler plugin, originally created by lum3on.
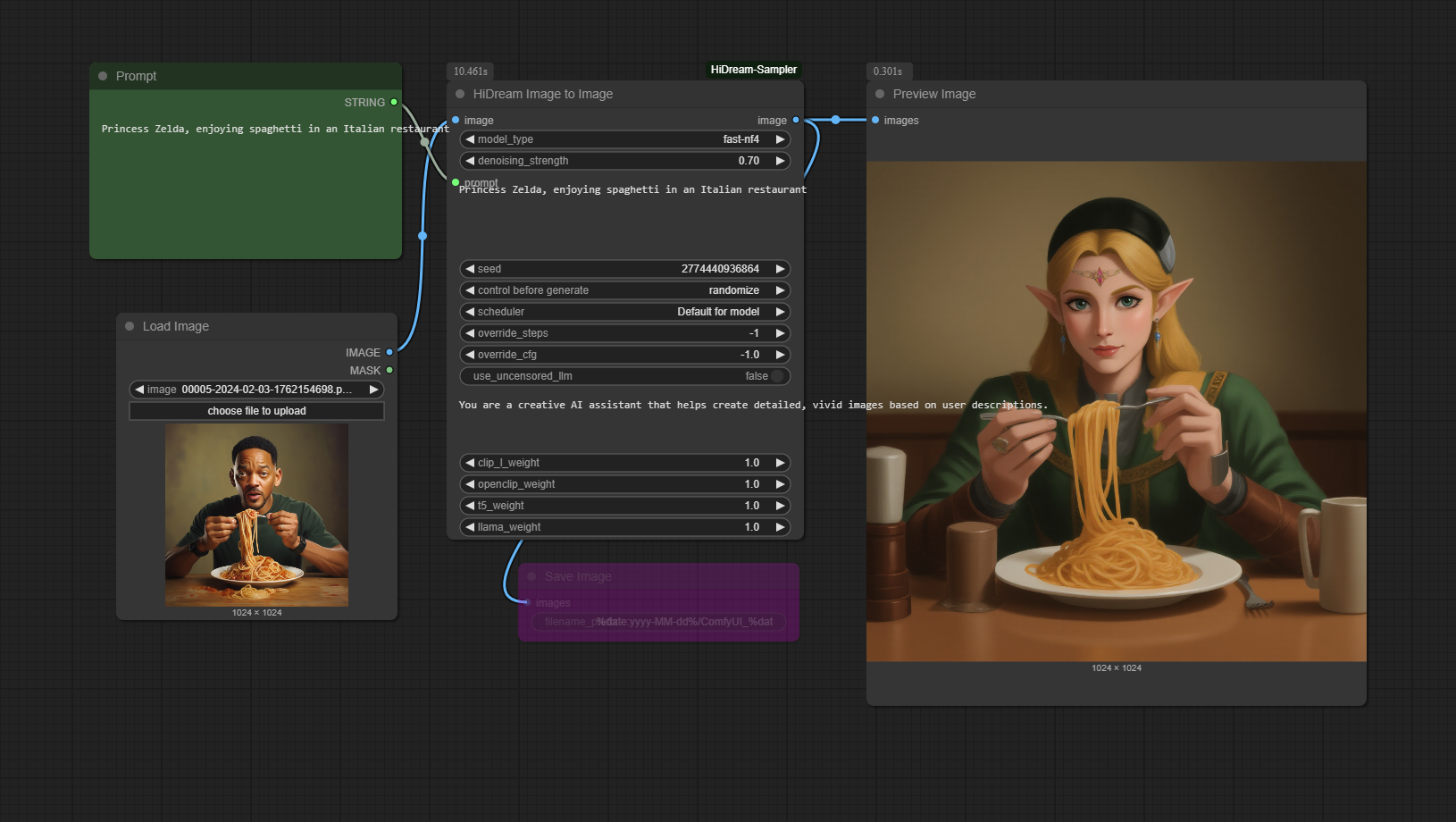
The nodes should automatically download the model, but I found that there was no corresponding download log after installation, as you cannot manually install the model or choose the model location yourself, which made me feel a bit out of control. However, their workflow examples have already implemented the image-to-image functionality. After installation, you should be able to find a sample-workflow folder in the corresponding directory or visit sample-workflow to obtain it. The images below also include the corresponding workflows. If you successfully test it, please let me know in the comments how to proceed. :)
Text-to-Image Workflow
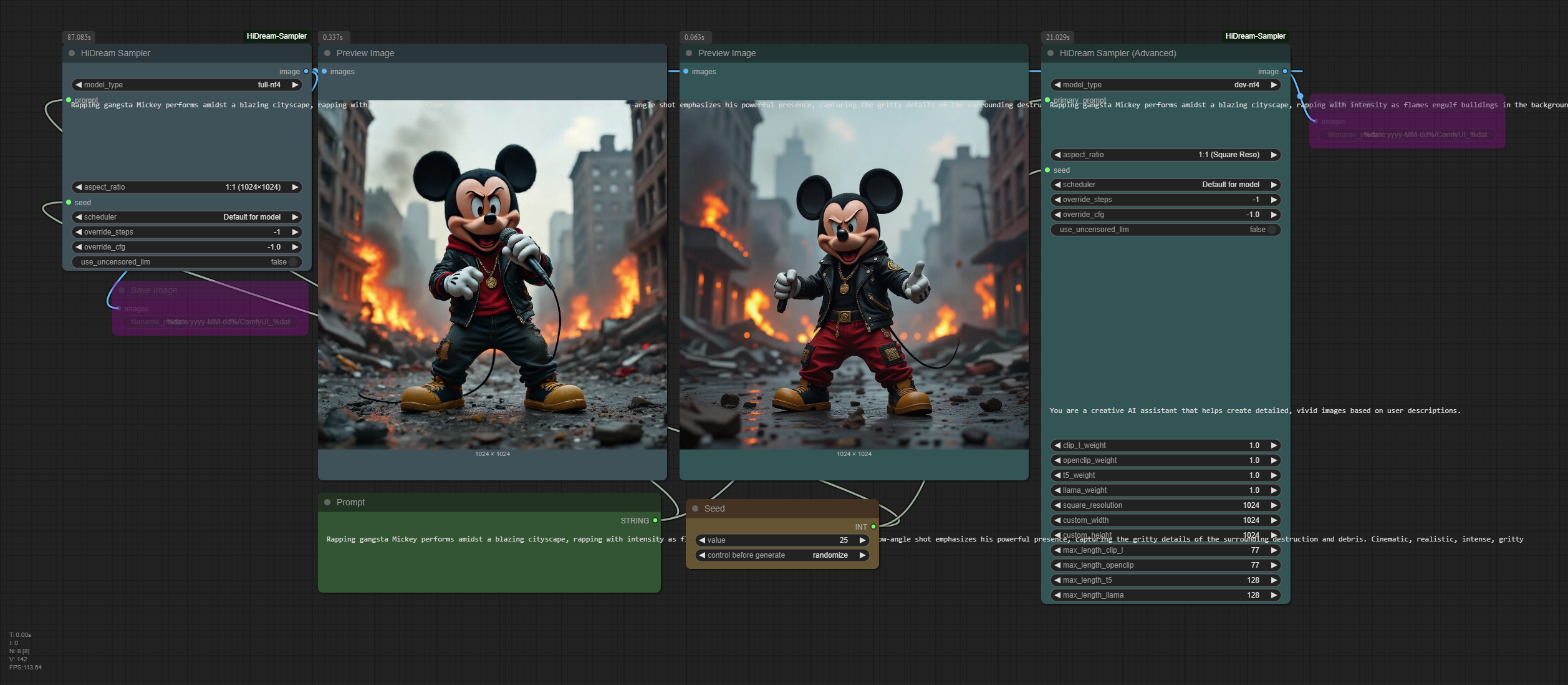
Image-to-Image Workflow
Comments
Sign in with GitHub to join the discussion.