ComfyUI Frame Pack Workflow Complete Step-by-Step Tutorial
This tutorial will guide you on how to use the Frame Pack workflow in ComfyUI, providing detailed step-by-step instructions.
FramePack is an AI video generation technology developed by Dr. Lvmin Zhang's team from Stanford University, the author of ControlNet. Its main features include:
- Dynamic Context Compression: By classifying video frames based on importance, key frames retain 1536 feature markers, while transitional frames are simplified to 192.
- Drift-resistant Sampling: Utilizing bidirectional memory methods and reverse generation techniques to avoid image drift and ensure action continuity.
- Reduced VRAM Requirements: Lowering the VRAM threshold for video generation from professional-grade hardware (12GB+) to consumer-level (only 6GB VRAM), allowing ordinary users with an RTX 3060 laptop to generate high-quality videos up to 60 seconds long.
- Open Source and Integration: FramePack is currently open-sourced and integrated into Tencent's Hunyuan video model, supporting multimodal inputs (text + images + voice) and real-time interactive generation.
Original Links Related to Frame Pack
- Original Repository: https://github.com/lllyasviel/FramePack/
- One-click running integration package for Windows without ComfyUI: https://github.com/lllyasviel/FramePack/releases/tag/windows
Corresponding Prompt
lllyasviel provides a GPT prompt for video generation in the corresponding repository. If you are unsure how to write prompts while using the Frame Pack workflow, you can try the following:
- Copy the prompt below and send it to GPT.
- Once GPT understands the requirements, provide it with the corresponding images, and you will receive the appropriate prompts.
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.Current Implementation of Frame Pack in ComfyUI
Currently, there are three custom node authors who have implemented Frame Pack capabilities in ComfyUI:
- Kijai: ComfyUI-FramePackWrapper
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
Differences Between These Custom Nodes
Below we explain the differences in the workflows implemented by these custom nodes.
Kijai's Custom Plugin
Kijai has repackaged the corresponding models, and I believe you have used Kijai's related custom nodes, thanks to him for bringing such rapid updates!
It seems that Kijai's version is not registered in the ComfyUI Manager, so it cannot currently be installed through the Manager's Custom Nodes Manager. You need to install it via the Manager's Git or manually.
Features:
- Supports video generation with first and last frames
- Requires installation via Git or manual installation
- Models are reusable
HM-RunningHub and TTPlanetPig's Custom Plugins
These two custom nodes are modified versions based on the same code, originally created by HM-RunningHub, and then TTPlanetPig implemented video generation with first and last frames based on the corresponding plugin source code. You can check this PR.
The folder structure of the models used by these two custom nodes is consistent, both using the original repository model files that have not been repackaged. Therefore, these model files cannot be used in other custom nodes that do not support this folder structure, leading to larger disk space usage.
Features:
- Supports video generation with first and last frames
- The downloaded model files may not be reusable in other nodes or workflows
- Takes up more disk space because the model files are not repackaged
- Some compatibility issues with dependencies
Kijai ComfyUI-FramePackWrapper FLF2V ComfyUI Workflow
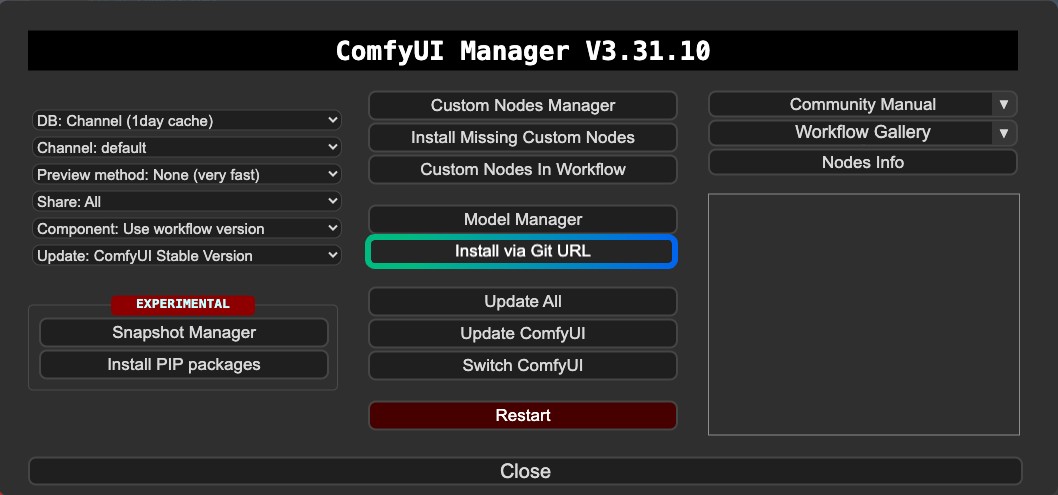
1. Plugin Installation
For ComfyUI-FramePackWrapper, you may need to install it using the Manager's Git:
Here are some articles you might find useful:
- How to install custom nodes
- "This action is not allowed with this security level configuration" issue resolution
2. Workflow File Download
Download the video file below and drag it into ComfyUI to load the corresponding workflow. I have added the model information in the file, which will prompt you to download the model.
Video Preview
Download the images below, which we will use as image inputs.


3. Manual Model Installation
If you are unable to successfully download the models in the workflow, please download the models below and save them to the corresponding location.
CLIP Vision
VAE
Text Encoder
Diffusion Model Kijai provides two versions with different precisions. You can choose one to download based on your graphics card performance.
| File Name | Precision | Size | Download Link | Graphics Card Requirement |
|---|---|---|---|---|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | Download Link | High |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | Download Link | Low |
File Save Location
📂 ComfyUI/
├──📂 models/
│ ├──📂 diffusion_models/
│ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # or bf16 precision
│ ├──📂 text_encoders/
│ │ ├─── clip_l.safetensors
│ │ └─── llava_llama3_fp16.safetensors
│ ├──📂 clip_vision/
│ │ └── sigclip_vision_patch14_384.safetensors
│ └──📂 vae/
│ └── hunyuan_video_vae_bf16.safetensors4. Complete the corresponding workflow step by step
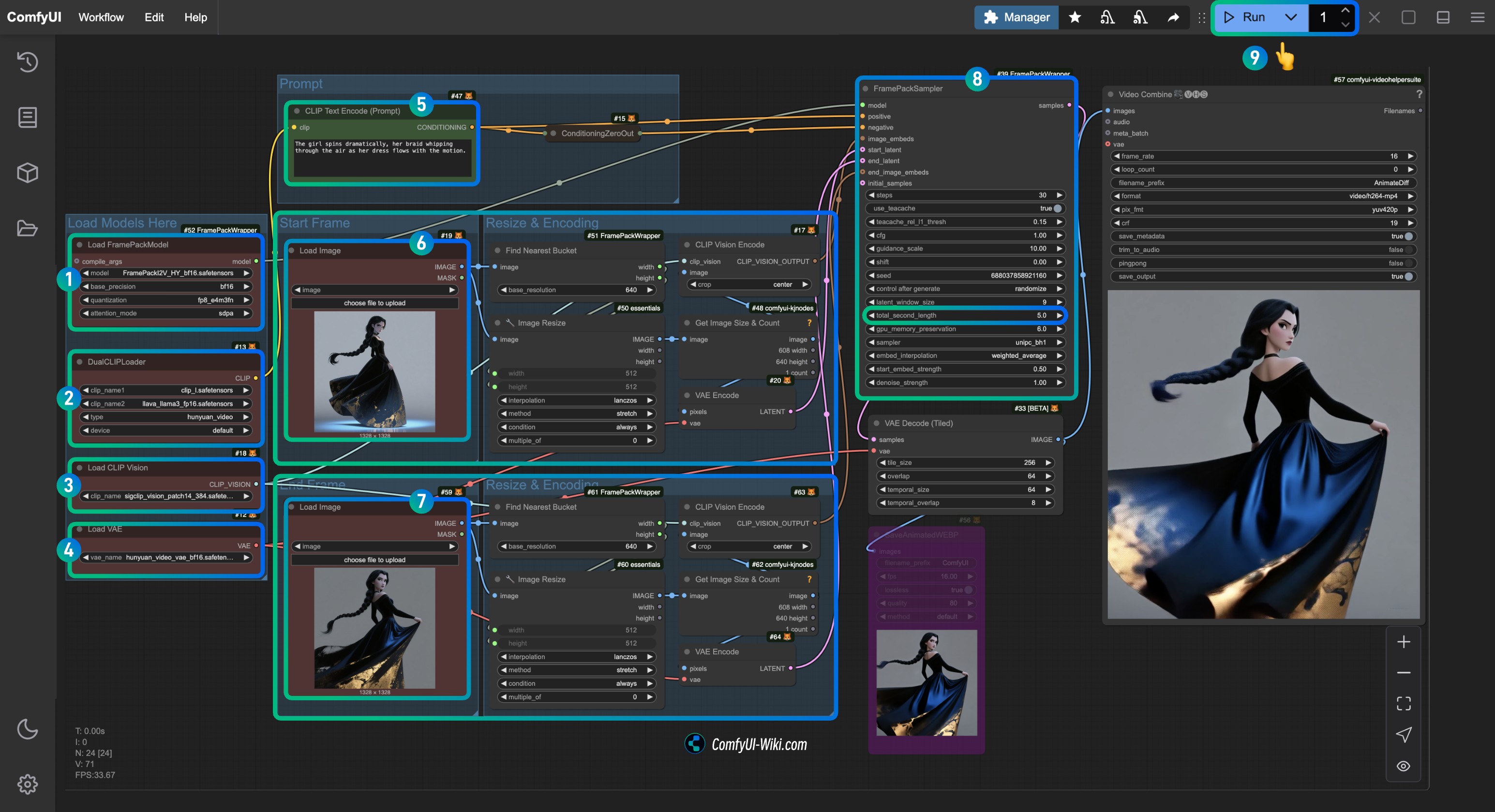
- Ensure that the
Load FramePackModelnode has loaded theFramePackI2V_HY_fp8_e4m3fn.safetensorsmodel. - Ensure that the
DualCLIPLoadernode has loaded:- The
clip_l.safetensorsmodel - The
llava_llama3_fp16.safetensorsmodel
- The
- Ensure that the
Load CLIP Visionnode has loaded thesigclip_vision_patch14_384.safetensorsmodel. - You can load the
hunyuan_video_vae_bf16.safetensorsmodel in theLoad VAEnode. - (Optional, if using my input images) Modify the
Promptparameter in theCLIP Text Encodernode to input the video description you want to generate. - In the
Load Imagenode, loadfirst_frame.jpg, which is related to the input processing offirst_frame. - In the
Load Imagenode, loadlast_frame.jpg, which is related to the input processing oflast_frame(if you do not need the last frame, you can delete it or use Bypass to disable it). - In the
FramePackSamplernode, you can modify thetotal_second_lengthparameter to change the duration of the video; in my workflow, it is set to5seconds, and you can adjust it according to your needs. - Click the
Runbutton or use the shortcutCtrl(cmd) + Enterto execute the video generation.
If you do not need the last frame, please bypass the entire input processing related to last_frame.
HM-RunningHub and TTPlanetPig Plugin Details
These two plugins use the same model storage location, but as I mentioned earlier, they download the entire original repository, which needs to be saved in a specified location. This prevents other plugins from reusing these models, leading to some wasted disk space. However, they do implement the generation of first and last frames, so you can try them out if you want.
list index out of range issue. You can check this issue. Currently, it has been discussed that the possible situation is:
"The version of torchvision you are using is likely incompatible with the version of PyAV you have installed."
However, after trying the methods mentioned in the issue, I still couldn't resolve the problem. Therefore, I can only provide the relevant tutorial information here. If you manage to solve the issue, please feel free to provide feedback. I recommend checking this issue to see if anyone has proposed similar solutions.
Plugin Installation
- You can choose to install one of the following or both; the nodes differ, but they are both simple to use with only one node:
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
- Enhance the video editing experience in ComfyUI:
If you have used the VideoHelperSuite for video-related workflows, it is still crucial for expanding ComfyUI's video capabilities.
1. Model Download
HM-RunningHub provides a Python script to download all the models. You just need to run this script and follow the prompts. My approach is to save the code below as download_models.py and place it in the root directory of ComfyUI/models, then run python download_models.py in the terminal from the corresponding directory.
cd <your installation path>/ComfyUI/models/Then run the script:
python download_models.pyThis requires that your Python independent environment / system environment has installed the huggingface_hub package.
from huggingface_hub import snapshot_download
# Download HunyuanVideo model
snapshot_download(
repo_id="hunyuanvideo-community/HunyuanVideo",
local_dir="HunyuanVideo",
ignore_patterns=["transformer/*", "*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download flux_redux_bfl model
snapshot_download(
repo_id="lllyasviel/flux_redux_bfl",
local_dir="flux_redux_bfl",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download FramePackI2V_HY model
snapshot_download(
repo_id="lllyasviel/FramePackI2V_HY",
local_dir="FramePackI2V_HY",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)You can also manually download the models below and save them to the corresponding location, which means downloading all the files from the corresponding repository.
- HunyuanVideo: HuggingFace Link
- Flux Redux BFL: HuggingFace Link
- FramePackI2V: HuggingFace Link
File Save Location
comfyui/models/
flux_redux_bfl
├── feature_extractor
│ └── preprocessor_config.json
├── image_embedder
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── image_encoder
│ ├── config.json
│ └── model.safetensors
├── model_index.json
└── README.md
FramePackI2V_HY
├── config.json
├── diffusion_pytorch_model-00001-of-00003.safetensors
├── diffusion_pytorch_model-00002-of-00003.safetensors
├── diffusion_pytorch_model-00003-of-00003.safetensors
├── diffusion_pytorch_model.safetensors.index.json
└── README.md
HunyuanVideo
├── config.json
├── model_index.json
├── README.md
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ └── model.safetensors.index.json
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── vae
├── config.json
└── diffusion_pytorch_model.safetensors2. Download Workflow
HM-RunningHub
TTPlanetPig
