HunyuanVideo Image-to-Video GGUF, FP8 and ComfyUI Native Workflow Complete Guide with Examples
A comprehensive tutorial on using Tencent's HunyuanVideo model in ComfyUI for image-to-video generation, including environment setup, model installation, and workflow instructions
Tencent officially released the HunyuanVideo image-to-video model on March 6, 2025. The model is now open-source and can be found at HunyuanVideo-I2V.
Below is the overall architecture diagram of HunyuanVideo:
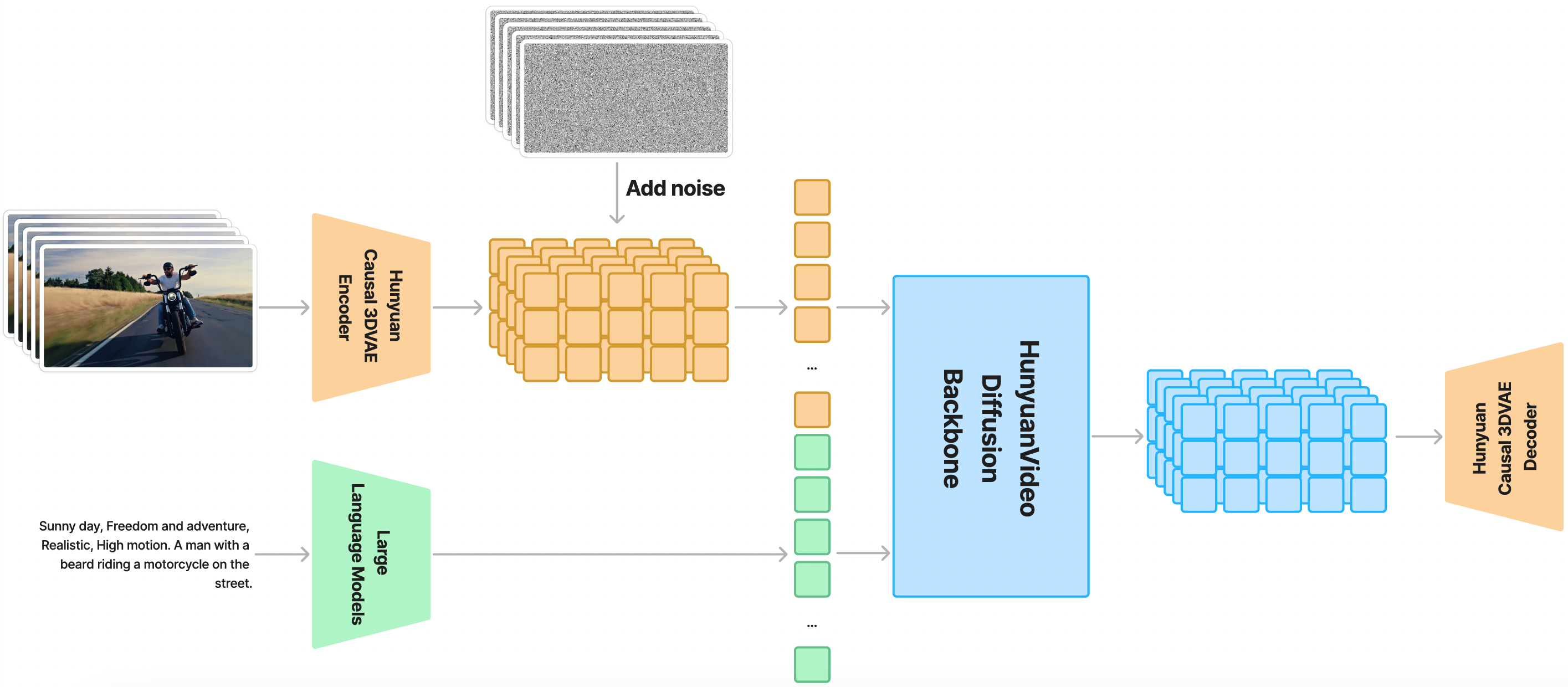
ComfyUI now natively supports the HunyuanVideo-I2V model, and community developers kijai and city96 have updated their custom nodes to support the HunyuanVideo-I2V model.
In addition to Tencent's official model, here are other versions compiled by ComfyUI Wiki:
- ComfyUI official repackaged version (no plugin required): Comfy-Org/HunyuanVideo_repackaged
- Kijai's version (requires ComfyUI-HunyuanVideoWrapper): Kijai/HunyuanVideo_comfy
- city96's packaged version (requires ComfyUI-GGUF): city96/HunyuanVideo-I2V-gguf
In this article, we'll provide complete model installation instructions and workflow examples for each of these versions.
This article focuses on image-to-video workflows. If you want to learn about Tencent Hunyuan's text-to-video workflow, please refer to Tencent Hunyuan Text-to-Video Workflow Guide and Examples.
ComfyUI Official HunyuanVideo I2V Workflow
This workflow comes from the ComfyUI official documentation.
Before starting this tutorial, please refer to How to Update ComfyUI to update your ComfyUI to the latest version to avoid missing the following Comfy_Core nodes for HunyuanVideo:
- HunyuanImageToVideo
- TextEncodeHunyuanVideo_ImageToVideo
1. HunyuanVideo I2V Workflow File
Download the workflow file below, then drag it into ComfyUI, or use the menu Workflows -> Open (ctrl+o) to load the workflow.

JSON Format Workflow Download
2. HunyuanVideo I2V Model Downloads
The following models are from Comfy-Org/HunyuanVideo_repackaged. Please download these models:
- llava_llama3_vision.safetensors
- clip_l.safetensors
- llava_llama3_fp16.safetensors
- llava_llama3_fp8_scaled.safetensors
- hunyuan_video_vae_bf16.safetensors
- hunyuan_video_image_to_video_720p_bf16.safetensors
After downloading, organize the files according to the structure below and save them to the corresponding folders under ComfyUI/models:
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_image_to_video_720p_bf16.safetensors3. Input Image
Download the image below as the input image

Complete the Check for Each HunyuanVideo I2V Workflow Node
Refer to the image to complete the check for each node's content to ensure the workflow runs normally
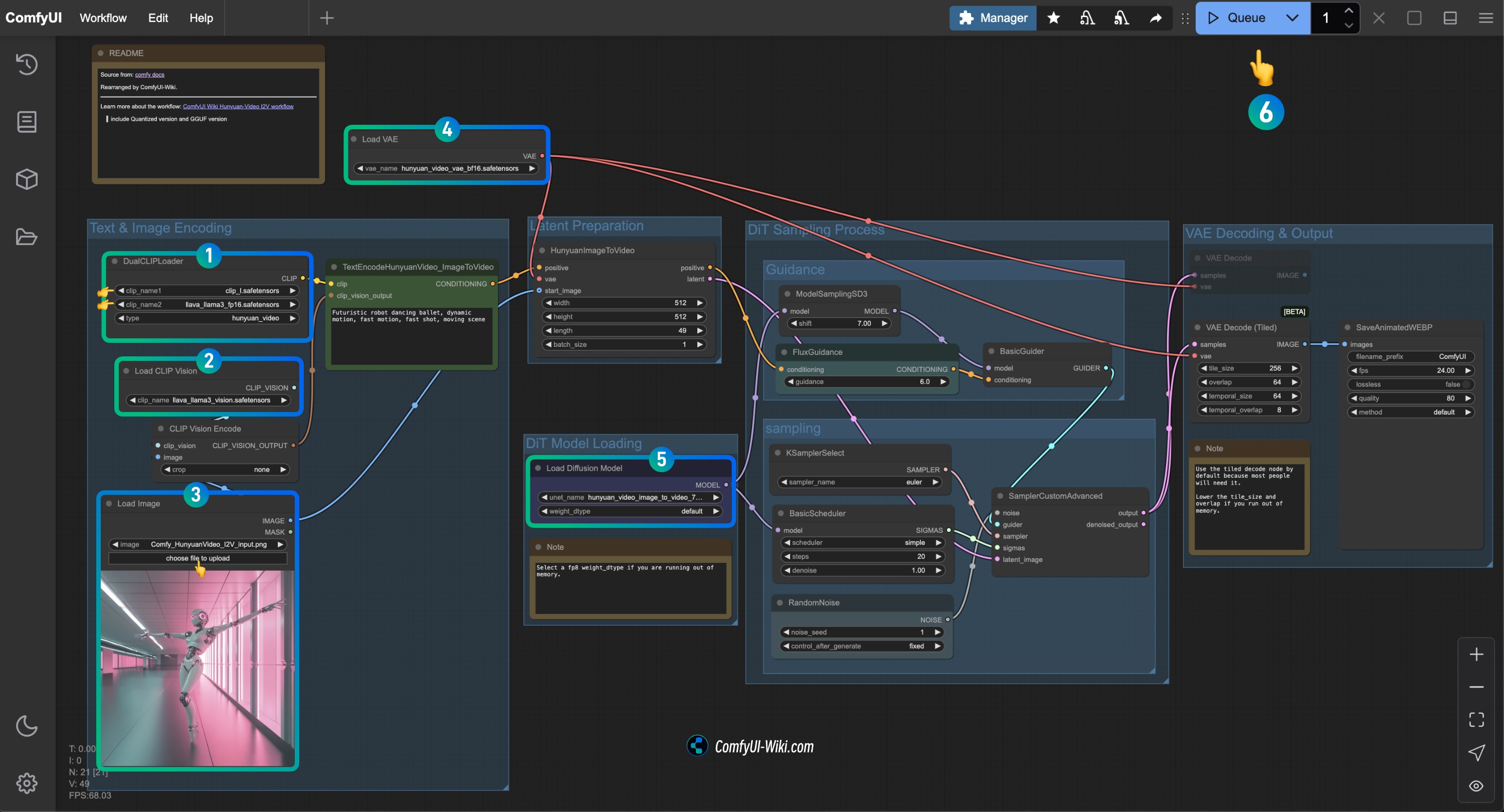
- Check the
DualCLIPLoadernode:
- Ensure
clip_name1: clip_l.safetensors is correctly loaded - Ensure
clip_name2: llava_llama3_vision.safetensors is correctly loaded
- Check the
Load CLIP Visionnode: Ensure llava_llama3_vision.safetensors is correctly loaded - In the
Load Imagenode, upload the input image provided earlier - Check the
Load VAEnode: Ensure hunyuan_video_vae_bf16.safetensors is correctly loaded - Check the
Load Diffusion Modelnode: Ensure hunyuan_video_image_to_video_720p_bf16.safetensors is correctly loaded
- If you encounter a
running out of memory.error during execution, you can try setting theweight_dtypetofp8type
- Click the
Runbutton or use the shortcut keyCtrl(cmd) + Enter(回车)to execute video generation
Kijai HunyuanVideoWrapper Version
1. Custom Node Installation
You need to install the following custom nodes:
If you don't know how to install custom nodes, please refer to ComfyUI Custom Node Installation Guide
2. Model Downloads
Downloaded files should be organized according to the structure below and saved to the corresponding folders under ComfyUI/models:
ComfyUI/
├── models/
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_I2V_fp8_e4m3fn.safetensors3. HunyuanVideo I2V Workflow File
Complete the Check for Each HunyuanVideo I2V Workflow Node (Kijai)
Refer to the image to complete the check for each node's content to ensure the workflow runs normally
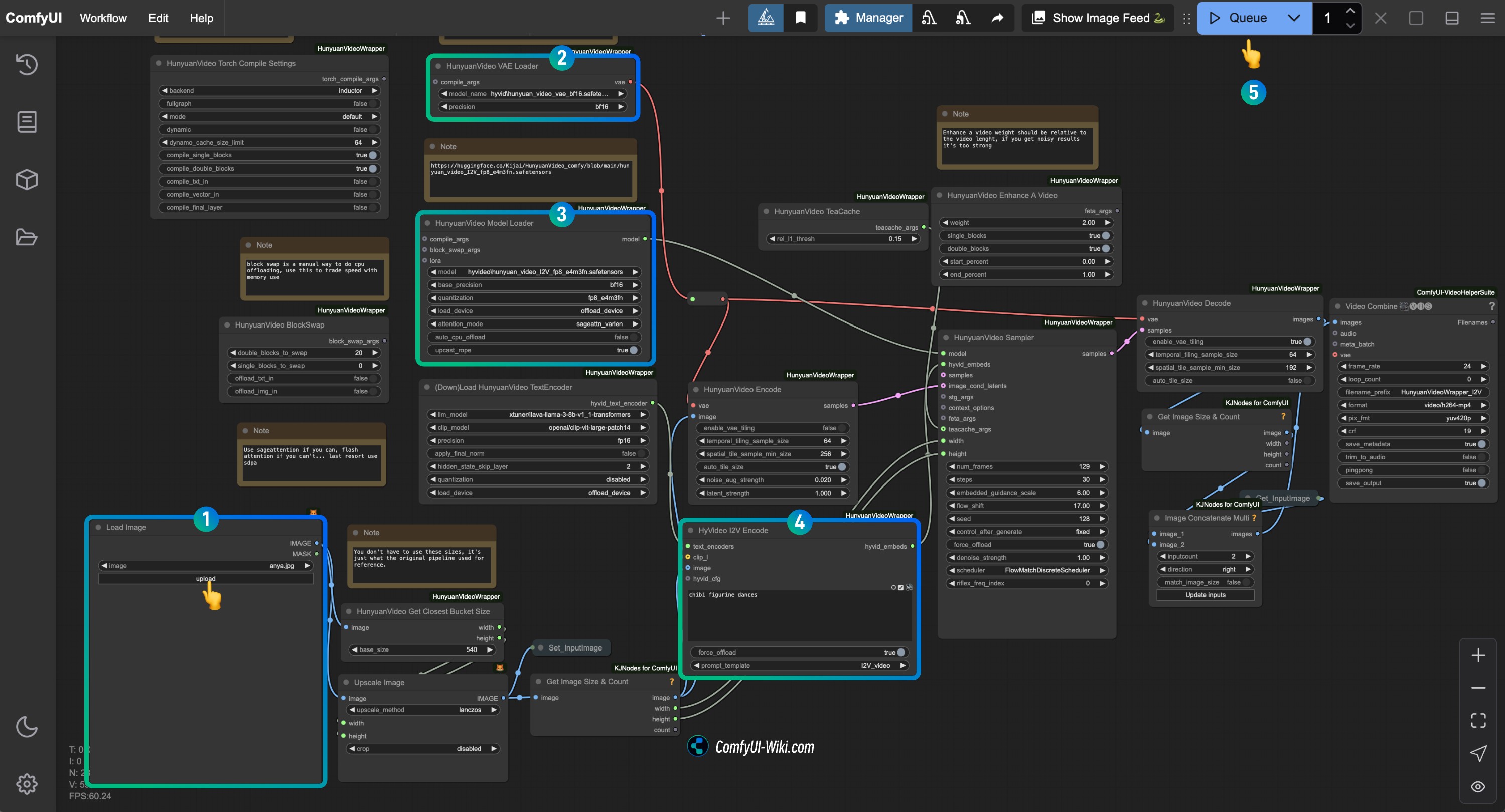
- In the
Load Imagenode, upload the image you want to use for image-to-video generation - In the
HunyuanVideo VAE Loadernode, ensurehunyuan_video_vae_bf16.safetensorsis correctly loaded - In the
HunyuanVideo Model Loadernode, ensurehunyuan_video_I2V_fp8_e4m3fn.safetensorsis correctly loaded - Modify the prompt text in the
HyVideo I2V Encodenode in theHyVideo I2V Encodenode, enter the description of the video you want to generate - Click the
Runbutton or use the shortcut keyCtrl(cmd) + Enter(回车)to execute video generation
city96 GGUF Version
1. Custom Node Installation (GGUF)
You need to install the following custom nodes:
If you don't know how to install custom nodes, please refer to ComfyUI Custom Node Installation Guide
2. Model Downloads (GGUF)
This version's model is basically the same as the Comfy official version, so please refer to the Comfy official version section for manual download of the corresponding model.
You need to visit city96/HunyuanVideo-I2V-gguf to download the model you need and save the corresponding gguf model file to the ComfyUI/models folder:
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── unet/
│ └── hunyuan-video-i2v-720p-Q4_K_M.gguf // Depending on the GGUF version you downloaded3. HunyuanVideo I2V Workflow File (GGUF)
Complete the Check for Each HunyuanVideo I2V Workflow Node (GGUF)
Refer to the image to complete the check for each node's content to ensure the workflow runs normally
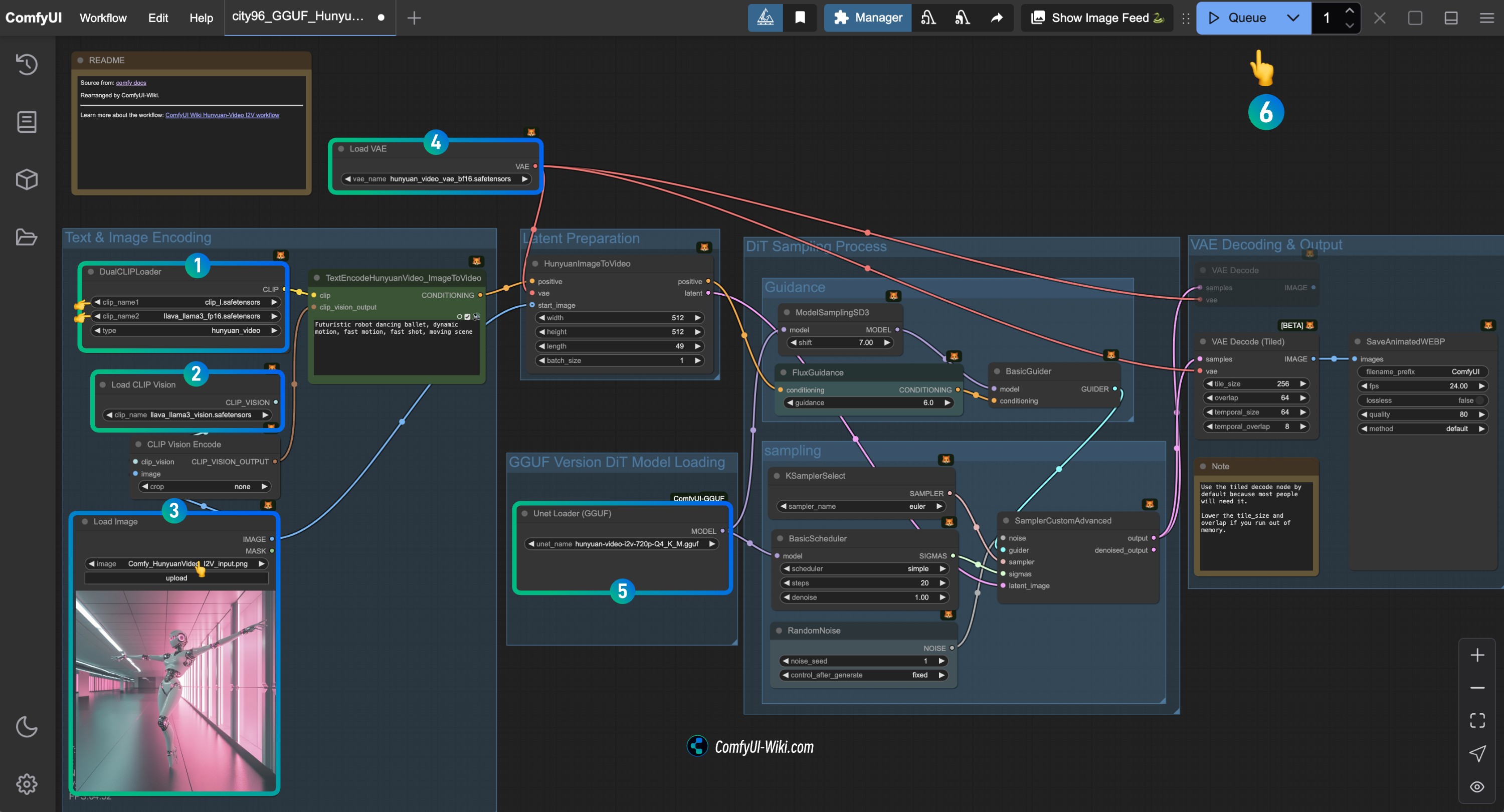
- Check the
DualCLIPLoadernode:
- Ensure
clip_name1: clip_l.safetensors is correctly loaded - Ensure
clip_name2: llava_llama3_vision.safetensors is correctly loaded
- Check the
Load CLIP Visionnode: Ensure llava_llama3_vision.safetensors is correctly loaded - In the
Load Imagenode, upload the input image provided earlier - Check the
Load VAEnode: Ensure hunyuan_video_vae_bf16.safetensors is correctly loaded - Check the
Load Diffusion Modelnode: Ensure the corresponding HunyuanVideo GGUF model is correctly loaded - Click the
Runbutton or use the shortcut keyCtrl(cmd) + Enterto execute video generation
Comments
Sign in with GitHub to join the discussion.