Wan2.2-S2V Audio-Driven Video in ComfyUI: Complete Guide
Create talking avatars with natural lip-sync using Wan2.2-S2V in ComfyUI. Covers model setup, audio-to-video pipeline, and workflow configuration for realistic talking head video.
Wan2.2-S2V represents a significant advancement in AI video generation technology, capable of creating dynamic video content from static images and audio inputs. This innovative model excels at producing synchronized videos with natural lip-sync, making it particularly valuable for content creators working on dialogue scenes, musical performances, and character-driven narratives.
Model Highlights
- Audio-Driven Video Generation: Transforms static images and audio into synchronized videos with natural lip-sync and expressions
- Cinematic-Grade Quality: Generates film-quality videos with authentic facial expressions, body movements, and camera language
- Minute-Level Generation: Supports long-form video creation up to minute-level duration in a single generation
- Multi-Format Support: Works with real people, cartoons, animals, digital humans, and supports portrait, half-body, and full-body formats
- Enhanced Motion Control: Generates actions and environments from text instructions with AdaIN and CrossAttention control mechanisms
- High Performance Metrics: Achieves FID 15.66, CSIM 0.677, and SSIM 0.734 for superior video quality and identity consistency
Wan2.2 S2V ComfyUI Native Workflow
1. Download Workflow File
Download the following workflow file and drag it into ComfyUI to load the workflow.
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/wan2.2_s2v/wan2.2-s2v.mp4"
Download the following image and audio as input:

2. Model Links
You can find the models in our repo
diffusion_models
audio_encoders
vae
text_encoders
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_s2v_14B_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 audio_encoders/ # Create one if you can't find this folder
│ │ └─── wav2vec2_large_english_fp16.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors3. Workflow Instructions
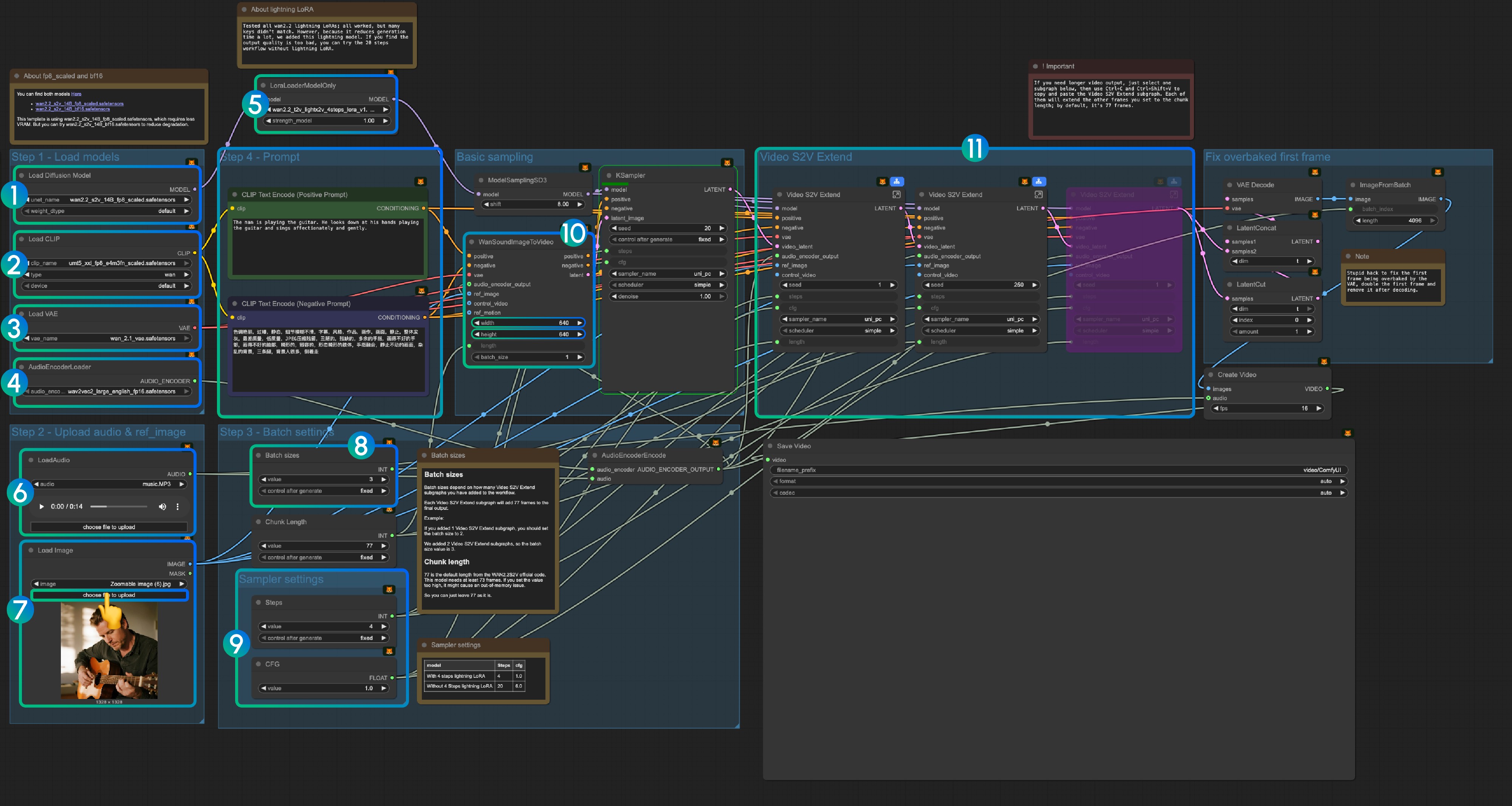
3.1 Lightning LoRA(Optional, for acceleration)
Lightning LoRA reduces generation time from 20 steps to 4 steps but may affect quality. Use for quick previews, disable for final output.
3.1.1 Audio Preprocessing Tips
Voice Separation for Better Results: Since ComfyUI core doesn't include voice separation nodes, we recommend using external tools to separate vocals from background music before processing. This is especially important for dialogue and lip-sync generation, as clean vocal tracks produce significantly better results than mixed audio with background music or noise.
3.2 About fp8_scaled and bf16 Models
You can find both models here:
The template uses wan2.2_s2v_14B_fp8_scaled.safetensors for lower VRAM usage. Try wan2.2_s2v_14B_bf16.safetensors for better quality.
3.3 Step-by-Step Operation Instructions
Step 1: Load Models
- Load Diffusion Model: Load
wan2.2_s2v_14B_fp8_scaled.safetensorsorwan2.2_s2v_14B_bf16.safetensors- The workflow uses
wan2.2_s2v_14B_fp8_scaled.safetensorsfor lower VRAM requirements - Use
wan2.2_s2v_14B_bf16.safetensorsfor better quality output
- The workflow uses
- Load CLIP: Load
umt5_xxl_fp8_e4m3fn_scaled.safetensors - Load VAE: Load
wan_2.1_vae.safetensors - AudioEncoderLoader: Load
wav2vec2_large_english_fp16.safetensors - LoraLoaderModelOnly: Load
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)- This LoRA reduces generation time but may affect quality
- Disable if output quality is insufficient
- LoadAudio: Upload the provided audio file or your own audio
- Load Image: Upload reference image
- Batch sizes: Set according to the number of Video S2V Extend subgraph nodes
- Each Video S2V Extend subgraph adds 77 frames to the output
- Example: 2 Video S2V Extend subgraphs = batch size 3
- Chunk Length: Keep default value of 77
- Sampler Settings: Choose based on Lightning LoRA usage
- With 4-step Lightning LoRA: steps: 4, cfg: 1.0
- Without Lightning LoRA: steps: 20, cfg: 6.0
- Size Settings: Set the output video dimensions
- Video S2V Extend: Video extension subgraph nodes
- Each extension generates 77 / 16 = 4.8125 seconds of video
- Calculate nodes needed: audio length (seconds) × 16 ÷ 77
- Example: 14s audio = 224 frames ÷ 77 = 3 extension nodes
- Use Ctrl-Enter or click the Run button to execute the workflow
Related Links
- Wan2.2 S2V Code: GitHub
- Wan2.2 S2V Model: Hugging Face
Comments
Sign in with GitHub to join the discussion.