ComfyUI Sonic Workflow for Digital Human Video Generation
Detailed tutorial for Tencent Sonic ComfyUI workflow
Sonic is an open-source digital human model by Tencent that can generate impressive video output from just images and audio input.
Here are the original Sonic-related links: Project page: https://jixiaozhong.github.io/Sonic/ Online demo: http://demo.sonic.jixiaozhong.online/ Source code: https://github.com/jixiaozhong/Sonic
Recently, community members have completed the plugin integration. This tutorial is based on the ComfyUI_Sonic plugin to reproduce Sonic's official example effects.
1. ComfyUI Sonic Plugin Installation
This workflow depends on the following plugins. Please ensure you have completed the plugin and dependency installation, or install missing nodes using ComfyUI-manager after downloading the workflow:
ComfyUI_Sonic: https://github.com/smthemex/ComfyUI_Sonic ComfyUI-VideoHelperSuite: https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite
If you're unfamiliar with the installation process, please refer to the ComfyUI Plugin Installation Tutorial
2. Downloading and Installing Sonic Models
The plugin repository provides model downloads. If the following model links are invalid or inaccessible, please check the plugin author's repository for updates.
Models should be saved in the following locations:
📁ComfyUI
├── 📁models
│ ├── 📁checkpoints
│ │ └── 📁video // video folder for model categorization (optional)
│ │ └── svd_xt_1_1.safetensors // svd_xt.safetensors or svd_xt_1_1.safetensors model file
│ └── 📁sonic // Create new sonic folder, save all content here from Google Drive
│ ├── 📁 whisper-tiny
│ │ ├── config.json
│ │ ├── model.safetensors
│ │ └── preprocessor_config.json
│ ├── 📁 RIFE
│ │ └── flownet.pkl
│ ├── audio2bucket.pth
│ ├── audio2token.pth
│ ├── unet.pth
│ └── yoloface_v5m.pt2.1 Choose one of these Stable Video Diffusion models:
svd_xt_1_1.safetensors https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main svd_xt_1_1.safetensors https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1/tree/main
2.2 Download Sonic-related models
Visit the following drive address and download all resources in the folder: Sonic models: https://drive.google.com/drive/folders/1oe8VTPUy0-MHHW2a_NJ1F8xL-0VN5G7W
2.3 Download whisper-tiny model
whisper-tiny https://huggingface.co/openai/whisper-tiny/tree/main
Download only these three files:
- config.json
- model.safetensors
- preprocessor_config.json
ComfyUI Sonic Workflow Resources
Please download the following audio, photos, and workflow files, or use your own materials:
Image:

Audio, please download any sample audio from: https://github.com/smthemex/ComfyUI_Sonic/tree/main/examples/wav
ComfyUI Sonic Workflow Explanation
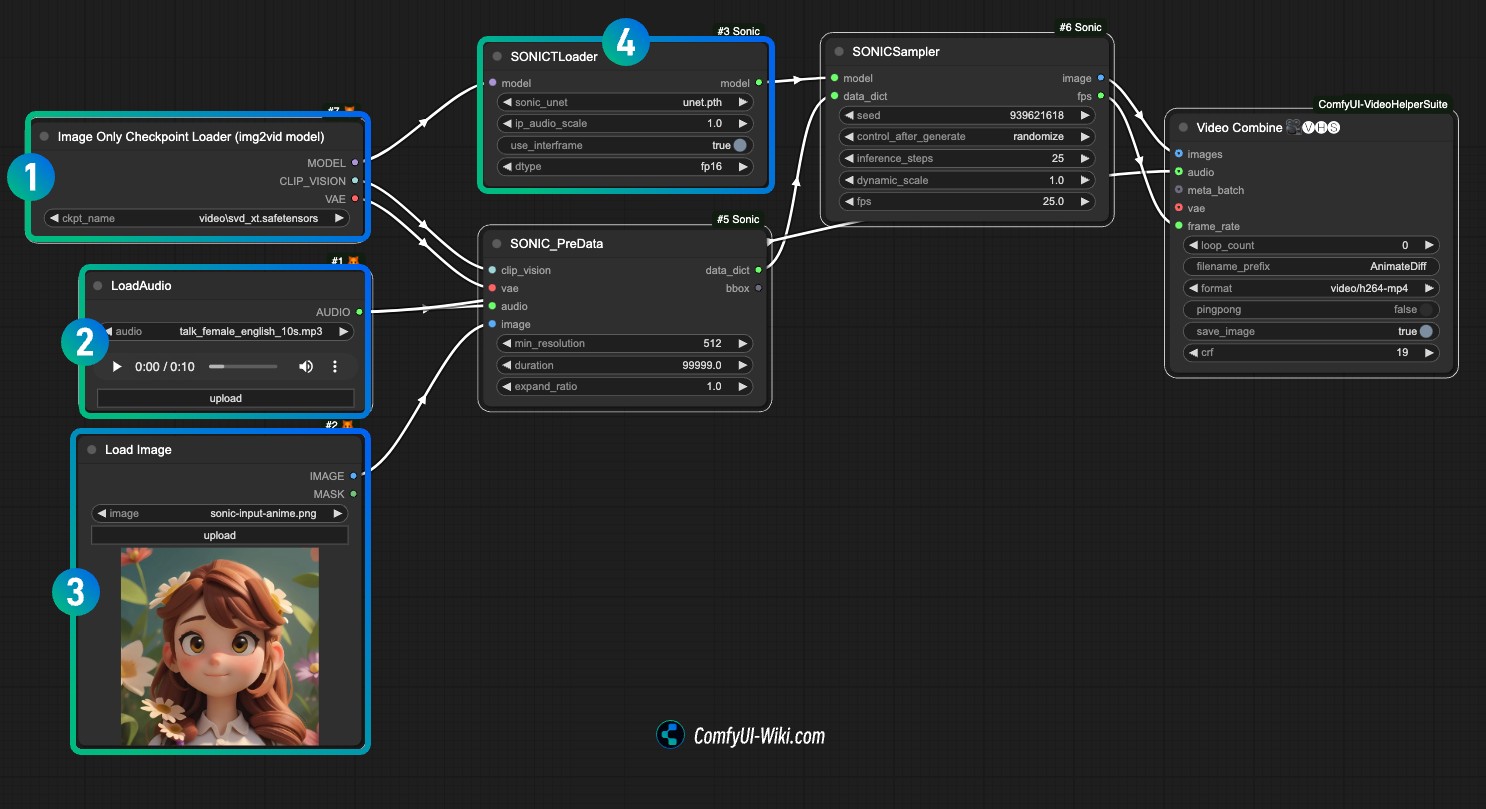
- At position
1, load the stable video diffusion model like svd_xt_1_1.safetensors - At position
2, upload and load the audio file - At position
3, upload the sample image - At position
4, load the unet.pth model file - Use Queue or shortcut
Ctrl(Command)+Enterto run the workflow for image generation
Troubleshooting
- Transformers version issue Since this plugin requires transformers==4.43.2, if your workflow doesn't run properly, please modify:
📁ComfyUI
├── 📁custom_nodes
│ └── 📁ComfyUI_Sonic // Plugin directory
│ └── requirements.txt // Plugin requirements filePlease modify in requirements.txt from:
#transformers ==4.43.2Remove #
transformers ==4.43.2Then restart ComfyUI or use pip to install the dependency
- frame_rate type mismatch issue
I encountered a numeric type mismatch in the last node. I tried using a primitive node as input
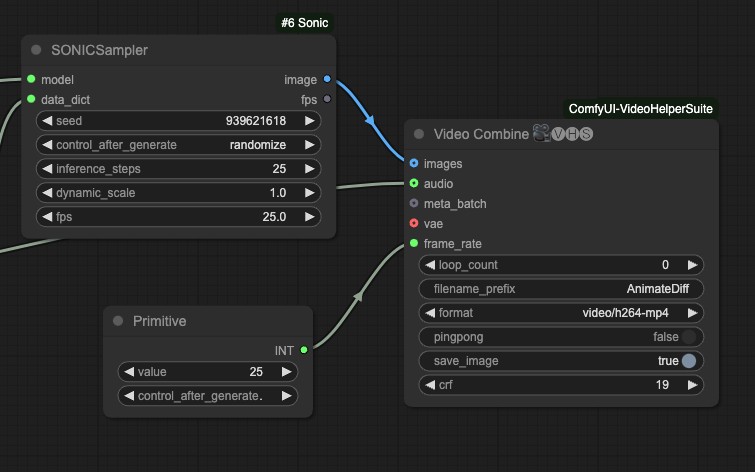
Additionally, as we're still testing this workflow, if you have better solutions, please leave a comment. I will update this tutorial promptly.
Comments
Sign in with GitHub to join the discussion.