ComfyUI Server Configuration Instructions
Current Version: ComfyUI Desktop v0.4.5
Server configuration is done on the server side (host side) of ComfyUI Desktop, where you can set up ComfyUI’s LAN access settings, various precision settings, and cache settings, etc. When accessing from other devices on the LAN, these settings cannot be modified.
Network
Whilst ComfyUI don’t block the server from being accessed over the network, it’s just not the intent of the Desktop app to be run as a server. Electron is not at all suited for this.
-
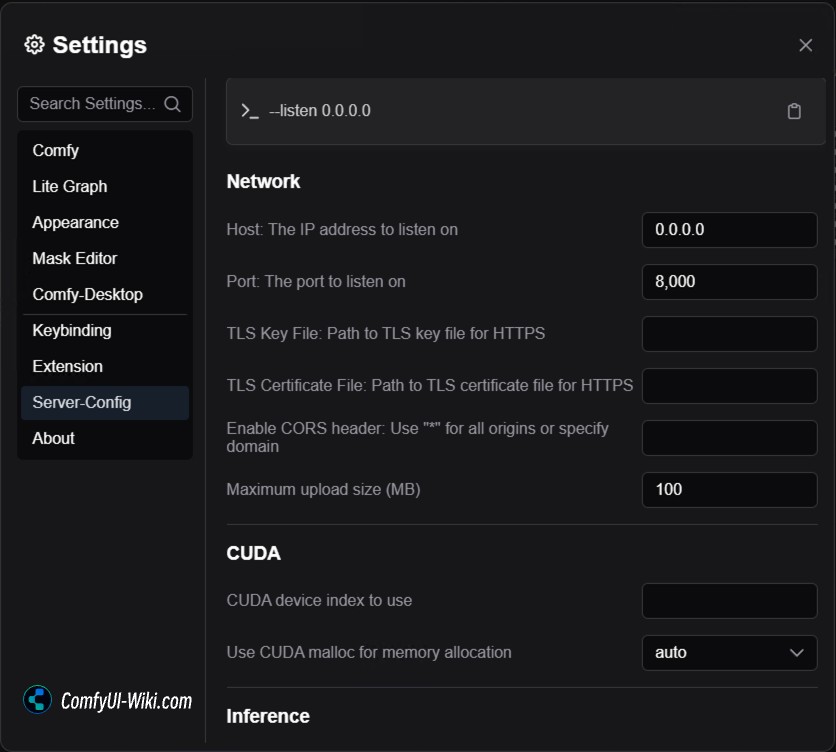
Listen Address (listen)
- Function: Set the IP address for the server to listen on. Usually keep default.
- Default Value:
127.0.0.1(localhost only access)
-
Port (port)
- Function: Set the port number for the server to listen on. Ensure it’s not used by other applications.
- Default Value:
8000(like a house number, only needs changing if there’s software conflict)
-
TLS Key File (tls-keyfile) and TLS Certificate File (tls-certfile)
- Function: Used for setting up HTTPS secure connection. Can be ignored if HTTPS is not needed.
-
Enable CORS Header (enable-cors-header)
- Function: Allow other websites to access your server. Use ”*” to allow all websites.
-
Maximum Upload Size (max-upload-size)
- Function: Limit the maximum size of file uploads in MB.
- Default Value:
100(like a suitcase capacity)
If you want to set up LAN access to ComfyUI, you need to set the listen address to 0.0.0.0, port to 8000 or another port, then other devices on the LAN can access through the host’s LAN IP address and port. For example, if the LAN IP is 192.168.1.100 and port is 8000, other devices can access ComfyUI through http://192.168.1.100:8000
This is similar to setting -listen 0.0.0.0 in the .bat file of early Portable version ComfyUI, but now it’s more convenient to set in ComfyUI Desktop.
CUDA Settings
-
CUDA Device (cuda-device)
- Function: Choose which GPU to use
- Simple Explanation: If you have multiple GPUs, you can choose which one to use. Like choosing which studio to work in
- Options:
- 0: First GPU
- 1: Second GPU (if available)
- null: Auto select
- Recommendation: Users with single GPU should keep default
-
Use CUDA Malloc (cuda-malloc)
- Function: Determine how GPU memory is allocated
- Simple Explanation: Like deciding how to arrange workspace in the studio
- Options:
Option Description Use Case Auto Let system decide best method Recommended for beginners Enable Use more aggressive memory allocation When need more VRAM Disable Use conservative memory allocation When having VRAM issues
Inference
Precision: Like the level of detail in painting. High precision is like painting with a fine brush - more details but slower; low precision is like using a broad brush - faster but might lose details.
-
Global Floating Point Precision (global-precision)
- Function: Control overall computation precision
- Options:
Option Description Use Case AUTO Auto select best precision, recommended for beginners Suitable for most cases FP32 Highest precision mode, like using a microscope When you need best image quality FP16 Lower precision but faster, like viewing with naked eye When you want faster generation
-
UNET Precision (unet-precision)
- Function: Control precision of AI’s core painting process
- Note: UNET is AI’s “brush”, determining how text becomes image
- Options:
Option Description Use Case AUTO Auto select, recommended for beginners Suitable for most cases FP32 Highest quality, but slower When need best quality FP16 Balanced mode, medium speed and quality Daily use BF16 Special balanced mode, for certain new GPUs Specific GPU use
-
VAE Precision (vae-precision)
- Function: VAE (Variational Autoencoder) handles final image detail processing, like an artist’s “coloring and refinement” technique
- Simple Explanation: Determines the fineness of final image details, like how detailed the artist’s final touches are
- Options:
Option Description Use Case AUTO Auto select suitable precision Recommended for beginners FP16 Faster but might have fewer details When need quick generation FP32 Best quality but slower When need best quality BF16 Between FP16 and FP32 For specific new GPUs
-
Run VAE on CPU (cpu-vae)
- Function: Let CPU handle final image refinement
- Simple Explanation: Like letting the butler (CPU) do the artist’s (GPU) finishing work
- Use Cases:
- When GPU memory is insufficient
- When processing very large images
- When GPU performance is insufficient
-
Text Encoder Precision (text-encoder-precision)
- Function: Control how precisely AI understands text descriptions
- Simple Explanation: Like how carefully the artist understands your requirements
- Options:
Option Description Use Case AUTO Auto select best precision Recommended for beginners FP32 Most careful understanding, but slower When need precise prompt interpretation FP16 Quick understanding, might have slight deviation When need faster speed BF16 Balance between both For specific GPU optimization
Memory
-
Force Channels-Last Memory Format (force-channels-last)
- Function: Change how image data is arranged in memory
- Simple Explanation: Like rearranging tools in the studio for better efficiency
- Recommendation: Keep default unless you understand its impact
-
DirectML Device Index (directml)
- Function: Select DirectML device
- Simple Explanation: A special painting mode, mainly for AMD GPUs
- Use Case: AMD GPU users might need to set this
-
Disable IPEX Optimization (disable-ipex-optimize)
- Function: Disable IPEX optimization. Usually doesn’t need changing.
- Default Value:
false
Preview Settings
-
Preview Method (preview-method)
- Function: Control how generation process is previewed
- Simple Explanation: Like whether to see the artist’s creation process
- Options:
Option Description Use Case NoPreviews No preview When need fastest speed Latent Show blurry creation process When want to see progress Taesd Show clearer creation process When want to see clear progress
-
Preview Image Size (preview-size)
- Function: Set preview window size
- Simple Explanation: Like deciding sketch size
- Recommended Values:
- Normal use: 512
- Low performance: 256
- High performance: Can set larger
Cache
-
Use Classic Cache System (cache-classic)
- Function: Use traditional cache management method
- Simple Explanation: Like artist organizing tools and materials in fixed way
- Use Cases:
- When system memory is sufficient
- When need stable performance
- Recommendation: Keep default unless having memory issues
-
Use LRU Cache (cache-lru)
- Function: Set amount of recently used data to cache
- Simple Explanation: Like limiting artist to keep only recently used tools and paints
- Use Cases:
- When memory is limited
- When need to balance performance and memory use
- Recommended Values:
- 8GB RAM: Set to 2-3
- 16GB RAM: Set to 4-6
- 32GB+ RAM: Set to 8-12
Attention Settings
-
Cross Attention Method (cross-attention-method)
- Function: Control how AI understands text and converts to images
- Simple Explanation: Like how artist understands your requirements and conceptualizes
- Options:
Option Description Use Case auto Auto select best method Recommended for beginners split Save VRAM but might be slower When VRAM is insufficient quad Traditional way, stable but slower When need stable effects pytorch Use PyTorch native method When having compatibility issues
-
Force Attention Upcast (force-attention-upcast)
- Function: Force using higher precision for attention mechanism
- Simple Explanation: Like making artist think more carefully about details
- Use Case: When generated image details are not ideal
-
Prevent Attention Upcast (prevent-attention-upcast)
- Function: Prevent using higher precision for attention mechanism
- Simple Explanation: Let artist work quickly without excessive detail focus
- Use Case: When need faster generation speed
VRAM Management
-
VRAM Management Mode (vram-management)
- Function: Control how GPU memory is used
- Simple Explanation: Like managing studio space usage
- Options:
Option Description Use Case Auto Auto manage, like having butler organize studio Recommended for beginners Full Use all available space When VRAM is sufficient Low Save space usage When VRAM is insufficient
-
Reserve VRAM (reserve-vram)
- Function: Reserve GPU memory for other programs
- Simple Explanation: Like reserving studio space for other uses
- Use Cases:
- When running other GPU-intensive programs (like games)
- Recommended value: 2-4GB depending on other program needs
General
-
Disable xFormers Optimization (disable-xformers)
- Function: Disable xFormers acceleration optimization
- Simple Explanation: xFormers is like artist’s quick painting technique, disabling makes artist use traditional method
- Recommendation: Keep enabled (unchecked) unless having issues
-
Default Hashing Function (default-hashing-function)
- Function: Choose method to check model file integrity
- Simple Explanation: Like checking if tools are in good condition
- Options:
Option Description sha256 Most common and secure checking method
-
Use PyTorch’s Slower Deterministic Algorithms When Possible
- Function: Use more stable but slower random algorithms in some cases
- Simple Explanation: Like letting artist use more traditional but stable way for random creation
- Recommendation: Usually no need to enable
-
Enable Some Untested Optimizations That May Lower Quality
- Function: Use experimental optimization methods
- Simple Explanation: Try new quick painting techniques, but might affect artwork quality
- Recommendation: Not recommended when pursuing stable effects
-
Don’t Print Server Output to Console
- Function: Don’t show backend running logs
- Simple Explanation: Let artist work quietly without reporting every detail
- Recommendation: Keep disabled (unchecked) when need to troubleshoot
-
Disable Saving Prompt Data in Files
- Function: Don’t save prompt information in generated image files
- Simple Explanation: Don’t record creation recipe behind artwork
- Use Case: When want to keep prompts private
-
Disable Loading All Custom Nodes
- Function: Prevent loading all custom function modules
- Simple Explanation: Use only basic tools, not extra special tools
- Use Case: When want most basic stable experience
-
Log Level (log-level)
- Function: Set system log detail level
- Simple Explanation: Like setting how detailed artist reports work
- Options:
Option Description Use Case DEBUG Show all details including debug info For developers or troubleshooting INFO Show general info including operations and status Recommended for daily use WARNING Only show warnings and errors When only want problem alerts ERROR Only show errors When only care about serious issues CRITICAL Only show fatal errors When only want most serious issues
Directory Settings
-
Input Directory (input-directory)
- Function: Set directory for input files
- Default Value: Empty string
-
Output Directory (output-directory)
- Function: Set directory for output files
- Default Value: Empty string