Lumina Image 2.0 ComfyUI Workflow Examples
A detailed guide on using the Lumina Image 2.0 model in ComfyUI, including model installation, workflow configuration, and parameter optimization tips.
 Lumina-Image-2.0 is a text-to-image model open-sourced by the Alpha-VLLM team during Chinese New Year 2025. With 2.6B parameters and based on the DiT architecture, this model demonstrates impressive performance in image quality, composition, and prompt comprehension.
Lumina-Image-2.0 is a text-to-image model open-sourced by the Alpha-VLLM team during Chinese New Year 2025. With 2.6B parameters and based on the DiT architecture, this model demonstrates impressive performance in image quality, composition, and prompt comprehension.
Lumina-Image-2.0 Github: https://github.com/Alpha-VLLM/Lumina-Image-2.0 Lumina-Image-2.0 huggingface: https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0 Online Demo 1 (Chinese): https://magic-animation.intern-ai.org.cn/image/create Online Demo (Gradio): http://47.100.29.251:10010/
This article will explain examples based on ComfyUI Example
Lumina Image 2.0 Workflow Examples
1. Download and Install Lumina Image 2.0 Model
| Name | Size | Installation Location | Download Link |
|---|---|---|---|
| Lumina Image 2.0 | 10.6GB | ComfyUI/models/checkpoints | Download Here |
📁ComfyUI
└── 📁models
└── 📁checkpoints
└── lumina_2.safetensors // Please save the model to this file location2. Lumina Image 2.0 ComfyUI Workflow
Please click the button below to download the corresponding ComfyUI workflow and open it with ComfyUI
Lumina Image 2.0 Workflow Instructions
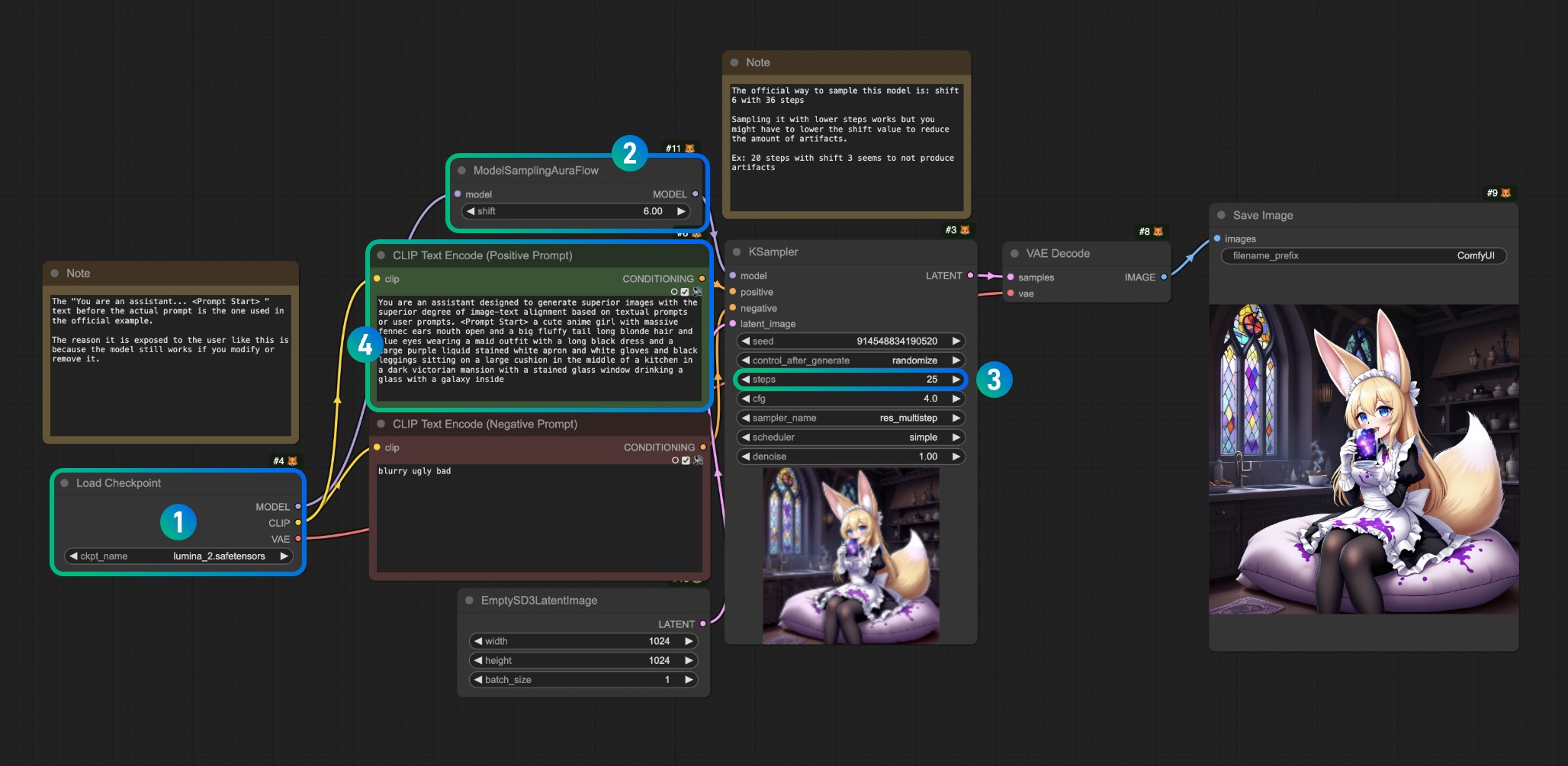
Referring to the image, please complete the corresponding operations at each numbered position
- Please ensure that the
lumina_2.safetensorsmodel is properly loaded in the Load Checkpoint. If the corresponding model is not present, please check the model location or refresh/restart ComfyUI
After loading the corresponding model, use Queue or the shortcut Ctrl(Command)+Enter to run the workflow for image generation
If you modify the sampling steps at number 3, you can proportionally adjust the offset at number 2
For example:
- step 36 corresponds to shift 6
- step 20 corresponds to shift 3
Comments
Sign in with GitHub to join the discussion.