Wan2.1 ComfyUI Workflow
The Wan2.1 model, open-sourced by Alibaba in February 2025, is a benchmark model in the field of video generation. It is licensed under the Apache 2.0 license and offers two versions: 14B (14 billion parameters) and 1.3B (1.3 billion parameters), covering various tasks including text-to-video (T2V) and image-to-video (I2V).
Additionally, community authors have created GGUF and quantized versions:
- GGUF: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
- Quantized version: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
This article will guide you through the corresponding workflows related to Wan2.1, including:
- The native Wan2.1 workflow supported by ComfyUI
- The version from Kijai
- The GGUF version from City96
All workflow files used in this tutorial contain the corresponding workflow information, which can be directly dragged into ComfyUI to load the corresponding workflow and model information. After the pop-up, click to download the corresponding model. If the model download cannot be completed, please refer to the manual installation section to complete the model installation. All output videos will be saved to the ComfyUI/output directory.
Since Wan2.1 separates the models for 480P and 720P, the corresponding workflows do not differ except for the model and canvas size. You can adjust the other version of the workflow based on the corresponding 720P or 480P workflow.
Example of Wan2.1 ComfyUI Native Workflow
The following workflow comes from the official ComfyUI blog. Currently, ComfyUI natively supports Wan2.1. To use the officially supported version, please upgrade your ComfyUI to the latest version. Refer to the section on how to upgrade ComfyUI for guidance. The ComfyUI Wiki has organized the original workflows.
After updating ComfyUI to the latest version, you can find the Wan2.1 workflow template in the menu bar under Workflows -> Workflow Templates.
All corresponding workflow files for this version come from Comfy-Org/Wan_2.1_ComfyUI_repackaged.
Among them, Diffusion models provides multiple versions. If the model version used in this article’s official native version has high hardware requirements, you can choose the version that suits your needs.
- i2v stands for image to video model, and t2v stands for text to video model.
- 14B and 1.3B represent the corresponding parameter amounts; larger values require higher hardware performance.
- bf16, fp16, and fp8 represent different precisions; higher precision requires higher hardware performance.
- bf16 may require support from Ampere architecture or higher GPUs.
- fp16 is more widely supported.
- fp8 has the lowest precision and hardware requirements, but the effect may also be relatively poorer.
- Generally, larger file sizes require higher hardware specifications.
1. Wan2.1 Text-to-Video Workflow
1.1 Download Wan2.1 Text-to-Video Workflow File
Download the image below and drag it into ComfyUI, or use the menu bar Workflows -> Open(Ctrl+O) to load the workflow.

Download the JSON format file.
1.2 Manual Model Installation
If the above workflow file cannot complete the model download, please download the model files below and save them to the corresponding locations.
Different types of models have multiple files; please download one. The ComfyUI Wiki has already sorted them in order of GPU performance requirements from high to low. You can visit here to view all model files.
Select one Diffusion models file to download:
- wan2.1_t2v_14B_bf16.safetensors
- wan2.1_t2v_14B_fp16.safetensors
- wan2.1_t2v_14B_fp8_e4m3fn.safetensors
- wan2.1_t2v_14B_fp8_scaled.safetensors
- wan2.1_t2v_1.3B_bf16.safetensors
- wan2.1_t2v_1.3B_fp16.safetensors
Select one version from Text encoders to download:
VAE
File save location
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_t2v_14B_fp16.safetensors # Or the version you choose
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # Or the version you choose
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 Steps to Run the Workflow
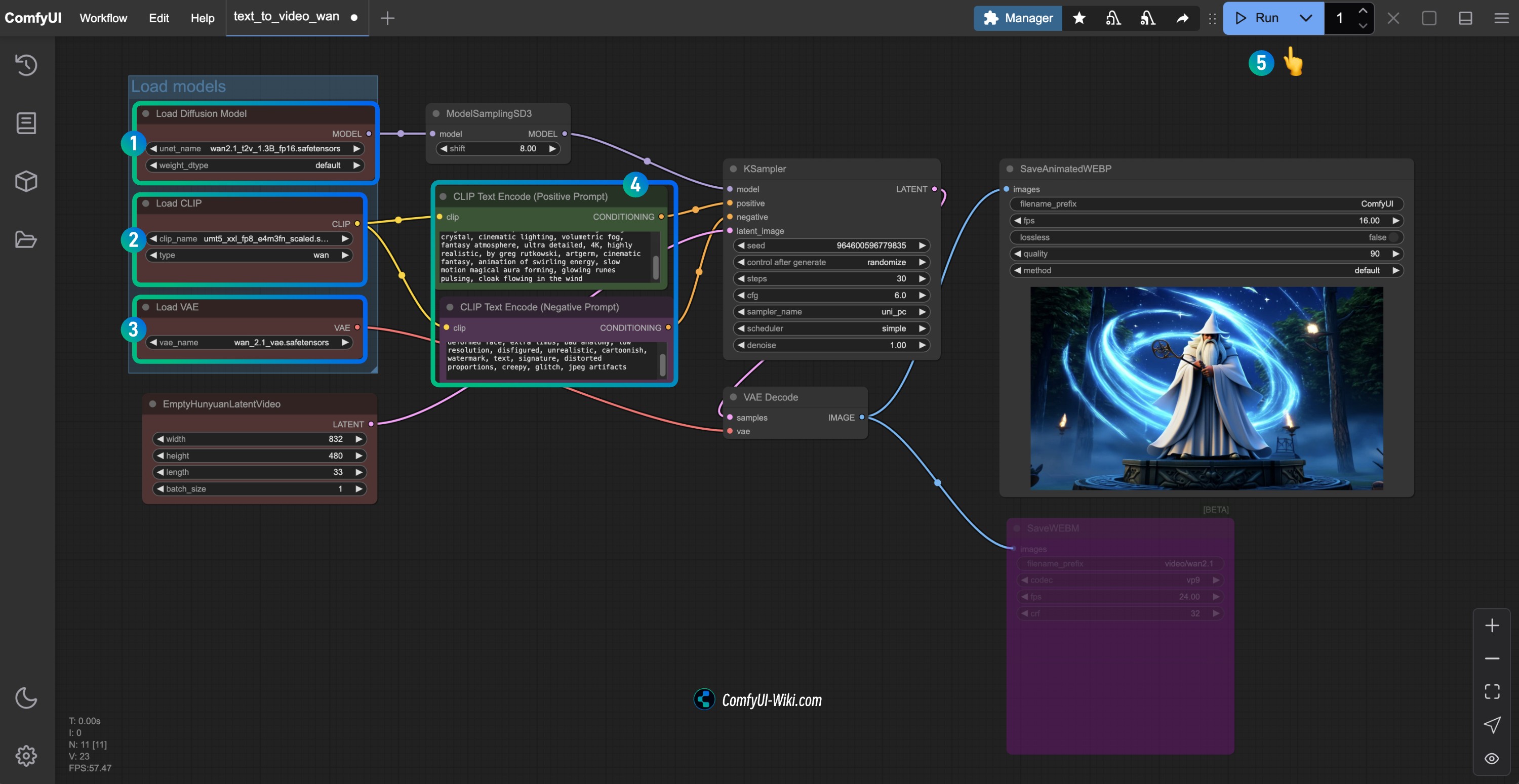
- Ensure that the
Load Diffusion Modelnode has loaded thewan2.1_t2v_1.3B_fp16.safetensorsmodel. - Ensure that the
Load CLIPnode has loaded theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel. - Ensure that the
Load VAEnode has loaded thewan_2.1_vae.safetensorsmodel. - You can enter the video description content you want to generate in the
CLIP Text Encodernode. - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enterto execute the video generation.
2. Wan2.1 Image-to-Video Workflow
2.1 Wan2.1 Image-to-Video Workflow 14B Workflow
Workflow File Download
Please click the button below to download the corresponding workflow, then drag it into the ComfyUI interface or use the menu bar Workflows -> Open(Ctrl+O) to load it.

Download the JSON format file.
This version of the workflow is basically the same as the 480P version, except that it uses a different diffusion model and has different dimensions for the WanImageToVideo node.
Download the image below as the input image.

2.2 Manual Model Download
If the above workflow file cannot complete the model download, please download the model files below and save them to the corresponding locations.
Diffusion models
720P version
- wan2.1_i2v_720p_14B_bf16.safetensors
- wan2.1_i2v_720p_14B_fp16.safetensors
- wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_720p_14B_fp8_scaled.safetensors
480P version
- wan2.1_i2v_480p_14B_bf16.safetensors
- wan2.1_i2v_480p_14B_fp16.safetensors
- wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_480p_14B_fp8_scaled.safetensors
Text encoders
VAE
CLIP Vision
File save location
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_i2v_480p_14B_fp16.safetensors # Or the version you choose
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # Or the version you choose
│ └── vae/
│ │ └── wan_2.1_vae.safetensors
│ └── clip_vision/
│ └── clip_vision_h.safetensors2.3 Steps to Run the Workflow
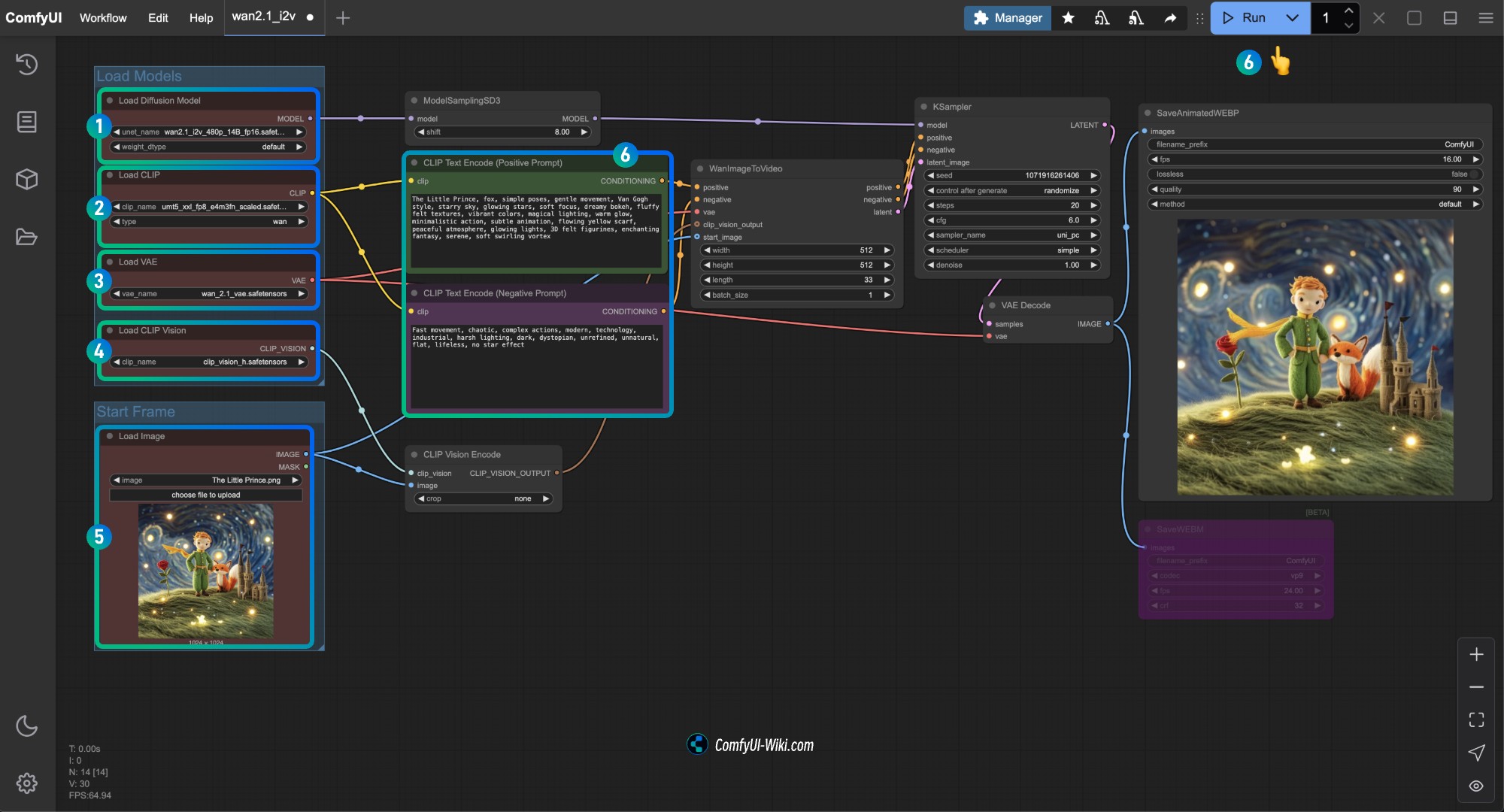
- Ensure that the
Load Diffusion Modelnode has loaded thewan2.1_i2v_480p_14B_fp16.safetensorsmodel - Ensure that the
Load CLIPnode has loaded theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure that the
Load VAEnode has loaded thewan_2.1_vae.safetensorsmodel - Ensure that the
Load CLIP Visionnode has loaded theclip_vision_h.safetensorsmodel - Load the input image in the
Load Imagenode - Input the content you want to generate in the
CLIP Text Encodernode, or use the example in the workflow - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enter(Enter)to execute the video generation
Kijai Wan2.1 Quantized Version Workflow
This version is provided by Kijai, and requires the following custom nodes:
You need to install the following three nodes:
Please install the corresponding three custom nodes before starting. You can refer to ComfyUI Custom Node Installation Tutorial for guidance.
Model repository: Kijai/WanVideo_comfy
The repository provides multiple versions of models, please select the appropriate model based on your device performance. Generally, larger files have better effects but also require higher hardware performance.
If the ComfyUI native workflow runs well on your device, you can also use the model provided by Comfy Org, and I will use the model provided by Kijai to complete the example in the example.
1. Kijai Text-to-Video Workflow
1.1 Kijai Wan2.1 Text-to-Video Workflow Download
Please click the button below to download the corresponding workflow, then drag it into the ComfyUI interface or use the menu bar Workflows -> Open(Ctrl+O) to load it.
The two workflow files are basically the same, but the second file has optional notes.
1.2 手动模型安装
Visit: https://huggingface.co/Kijai/WanVideo_comfy/tree/main to view the file size. Generally, larger files have better effects but also require higher hardware performance.
Diffusion models
- Wan2_1-T2V-14B_fp8_e4m3fn.safetensors
- Wan2_1-T2V-14B_fp8_e5m2.safetensors
- Wan2_1-T2V-1_3B_fp32.safetensors
- Wan2_1-T2V-1_3B_bf16.safetensors
- Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors
Text encoders
VAE
File save location
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-T2V-14B_fp8_e4m3fn.safetensors # Or the version you choose
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # Or the version you choose
│ └─── vae/
│ └── Wan2_1_VAE_bf16.safetensors # Or the version you choose1.3 Steps to Run the Workflow
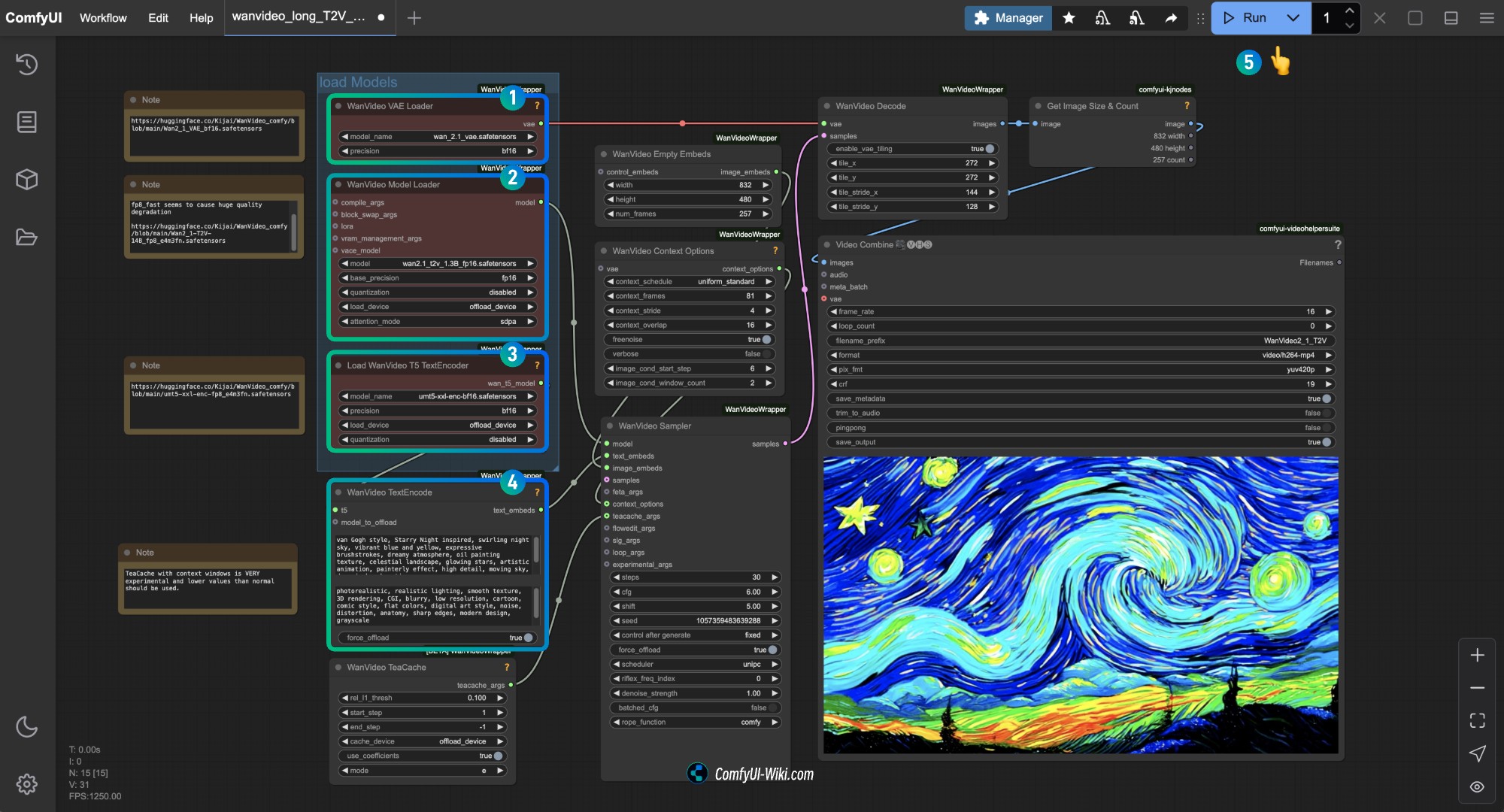
Ensure that the corresponding node has loaded the corresponding model, use the version you downloaded.
- Ensure the
WanVideo Vae Loadernode has loaded theWan2_1_VAE_bf16.safetensorsmodel - Ensure the
WanVideo Model Loadernode has loaded theWan2_1-T2V-14B_fp8_e4m3fn.safetensorsmodel - Ensure the
Load WanVideo T5 TextEncodernode has loaded theumt5-xxl-enc-bf16.safetensorsmodel - Input the content you want to generate in the
WanVideo TextEncodenode - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enter(Enter)to execute the video generation
You can modify the size in the WanVideo Empty Embeds node to modify the video size.
2. Kiai Wan2.1 Image-to-Video Workflow
2.1 Workflow File Download
Download the image below as the input image

2.2 Manual Model Download
Using the model in the example of the ComfyUI Native part is also possible, it seems that only the text_encoder cannot be used.
Diffusion models 720P version
480P version
Text encoders
VAE
CLIP Vision
File save location
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors # Or the version you choose
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # Or the version you choose
│ ├── vae/
│ │ └── Wan2_1_VAE_fp32.safetensors # Or the version you choose
│ └── clip_vision/
│ └── clip_vision_h.safetensors 2.3 Steps to Run the Workflow
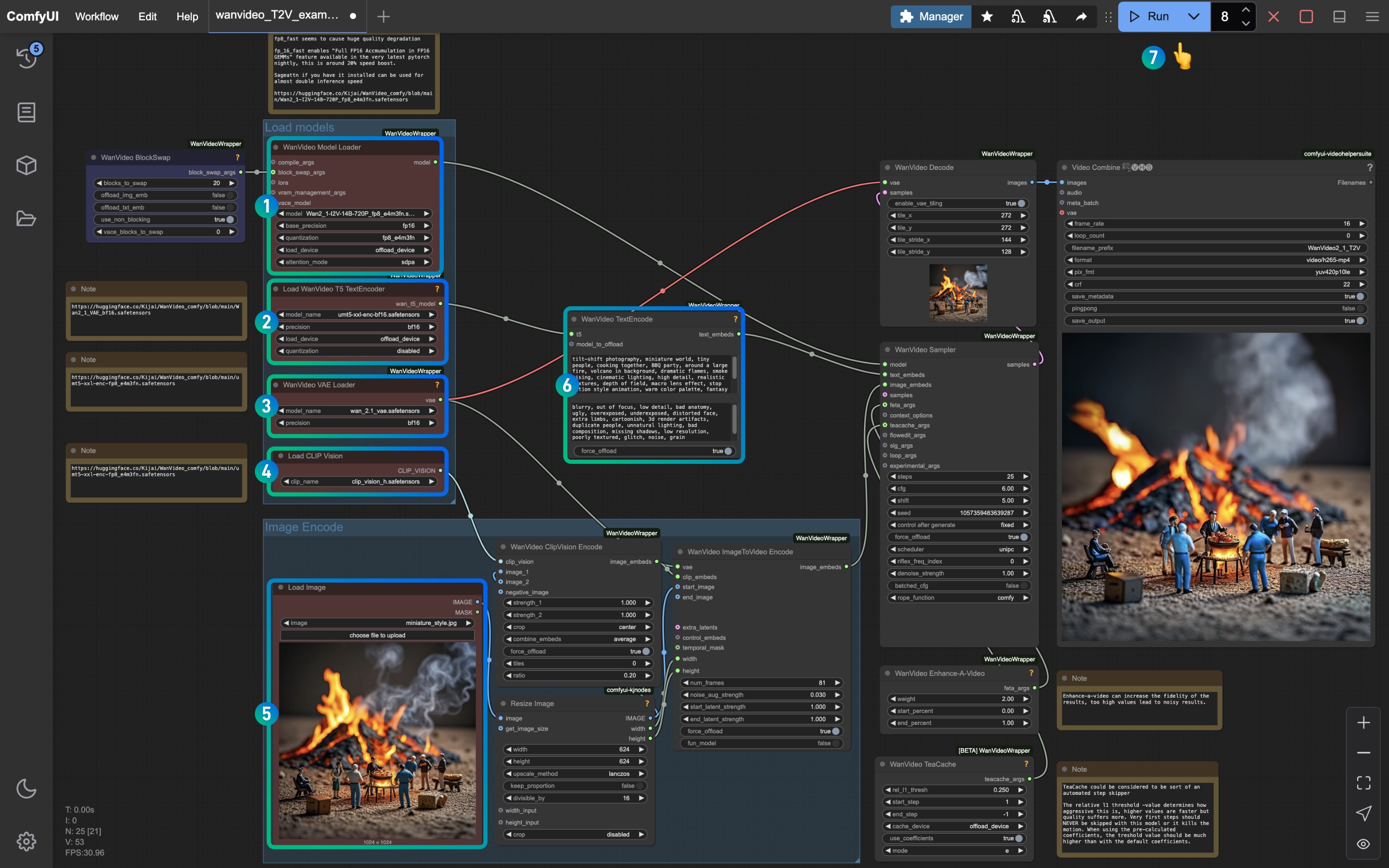
Please refer to the number in the picture to ensure that the corresponding node and model are loaded to ensure that the model can run normally
- Ensure the
WanVideo Model Loadernode has loaded theWan2_1-I2V-14B-720P_fp8_e4m3fn.safetensorsmodel - Ensure the
Load WanVideo T5 TextEncodernode has loaded theumt5-xxl-enc-bf16.safetensorsmodel - Ensure the
WanVideo Vae Loadernode has loaded theWan2_1_VAE_fp32.safetensorsmodel - Ensure the
Load CLIP Visionnode has loaded theclip_vision_h.safetensorsmodel - Load the input image in the
Load Imagenode - Save the default or modify the
WanVideo TextEncodeprompt to adjust the video effect - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enter(Enter)to execute the video generation
Wan2.1 GGUF Version Workflow
This part will use the GGUF version model to complete the video generation Model repository: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
We need ComfyUI-GGUF to load the corresponding model, please install the corresponding custom nodes before starting, you can refer to ComfyUI Custom Node Installation Tutorial for guidance.
This version workflow is basically the same as the ComfyUI Native version workflow, but we use the GGUF version and the corresponding GGUF model loading to complete the video generation, I will still provide a complete model list in this part to prevent some users from directly viewing the example of this part.
1. Wan2.1 GGUF Version Text-to-Video Workflow
1.1 Workflow File Download

1.2 Manual Model Download
Select a Diffusion models model file to download from the following list, city96 provides multiple different versions of models, please visit https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main to download a suitable version for you, generally the larger the file, the better the effect, but the higher the requirements for device performance.
Select a version from Text encoders to download,
VAE
File save location
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-t2v-14b-Q4_K_M.gguf # Or the version you choose
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # Or the version you choose
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 Steps to Run the Workflow
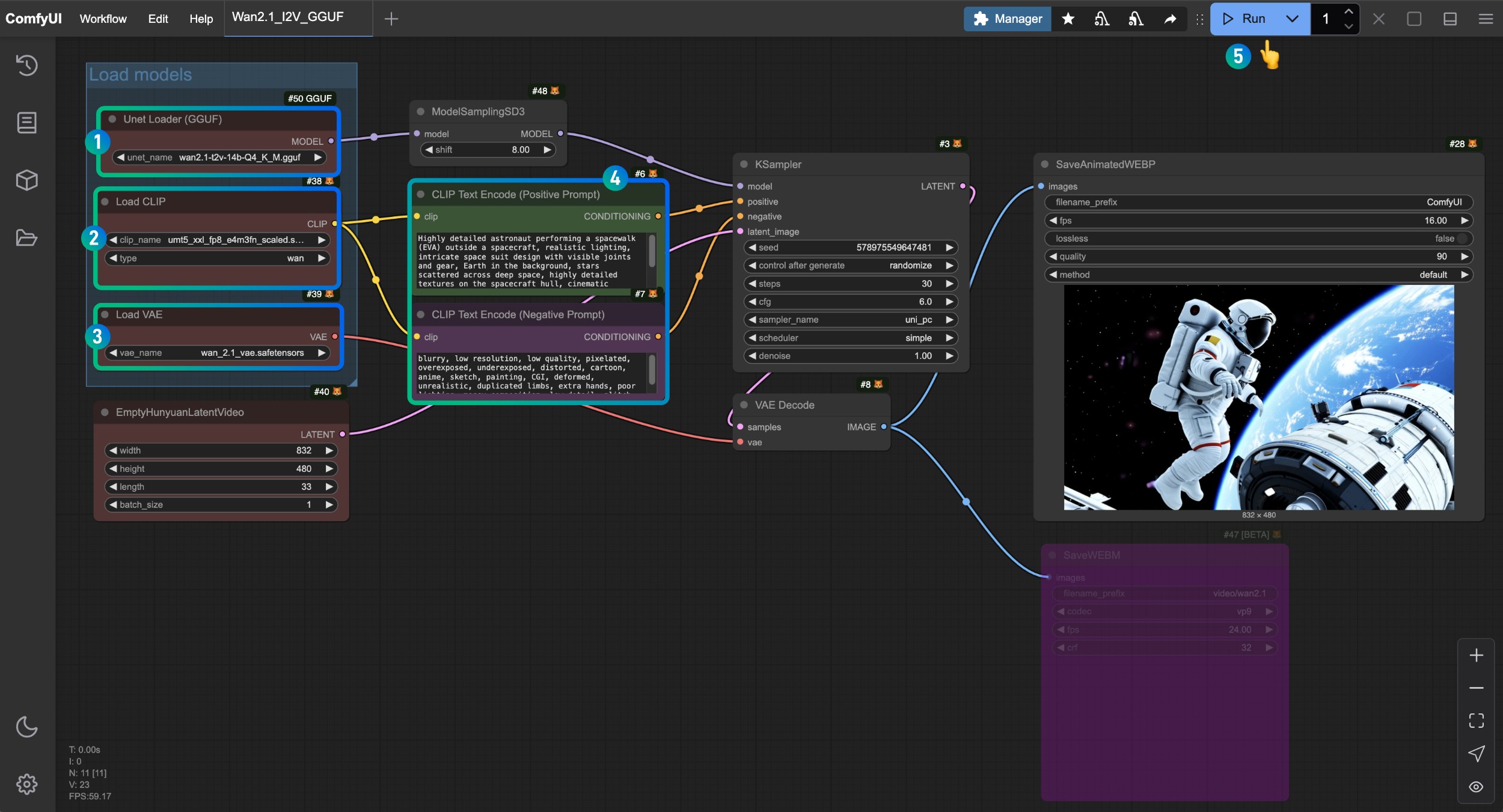
- 确保
Unet Loader(GGUF)节点加载了wan2.1-t2v-14b-Q4_K_M.gguf模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 可以在
CLIP Text Encoder节点中输入你想要生成的视频描述内容 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2. Wan2.1 GGUF Version Image-to-Video Workflow
2.1 Workflow File Download

2.2 Manual Model Download
Select a Diffusion models model file to download from the following list, city96 provides multiple different versions of models, please visit the corresponding repository to download a suitable version for you, generally the larger the file, the better the effect, but the higher the requirements for device performance.
Here I use the wan2.1-i2v-14b-Q4_K_M.gguf model to complete the example
Select a version from Text encoders to download,
VAE
File save location
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-i2v-14b-Q4_K_M.gguf # Or the version you choose
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # Or the version you choose
│ └── vae/
│ └── wan_2.1_vae.safetensors2.3 Steps to Run the Workflow
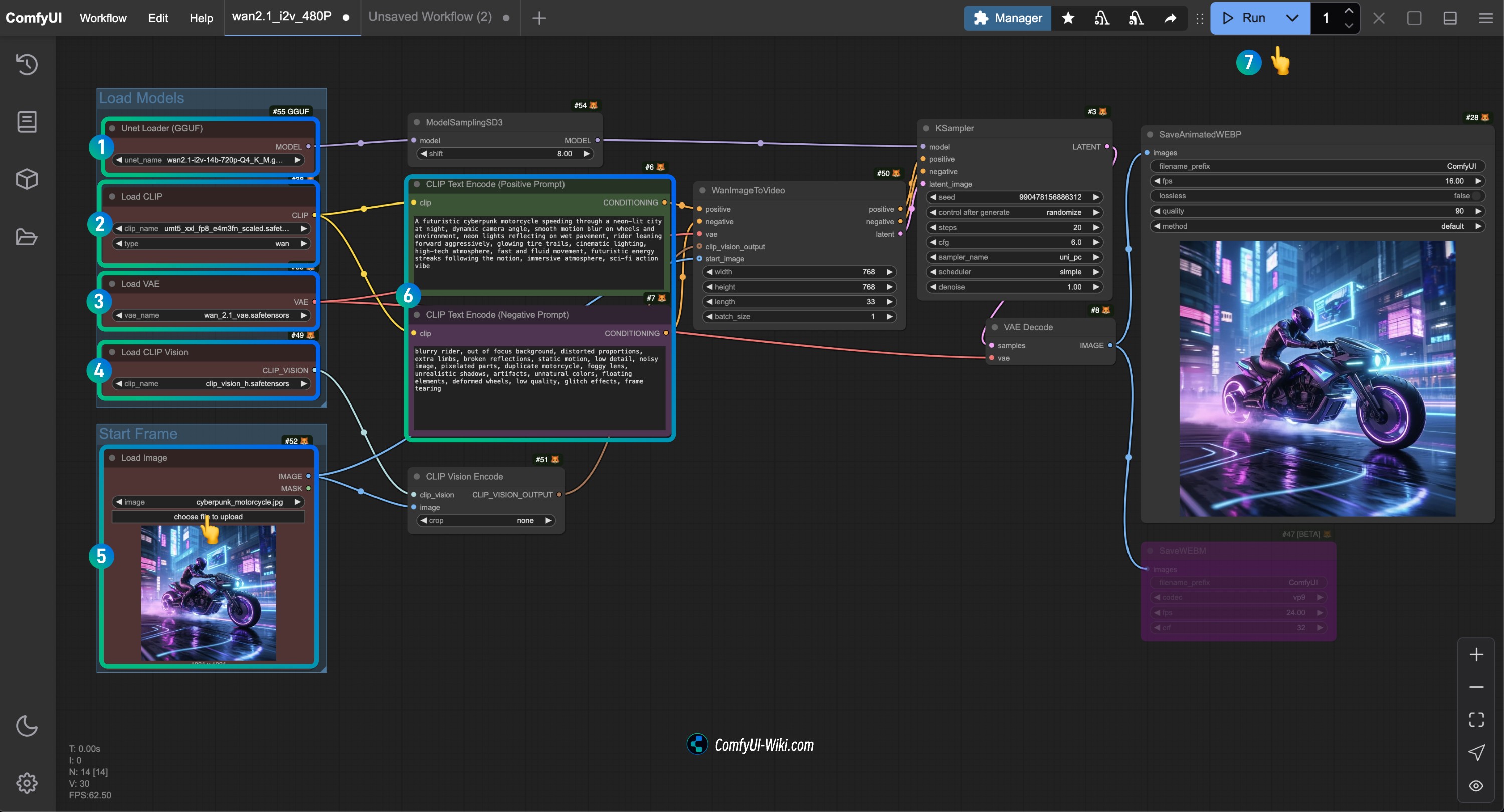
- Ensure the
Unet Loader(GGUF)node has loaded thewan2.1-i2v-14b-Q4_K_M.ggufmodel - Ensure the
Load CLIPnode has loaded theumt5_xxl_fp8_e4m3fn_scaled.safetensorsmodel - Ensure the
Load VAEnode has loaded thewan_2.1_vae.safetensorsmodel - Ensure the
Load CLIP Visionnode has loaded theclip_vision_h.safetensorsmodel - Load the input image in the
Load Imagenode - Input the content you want to generate in the
CLIP Text Encodernode, or use the example in the workflow - Click the
Runbutton, or use the shortcutCtrl(cmd) + Enter(Enter)to execute the video generation
Frequently Asked Questions
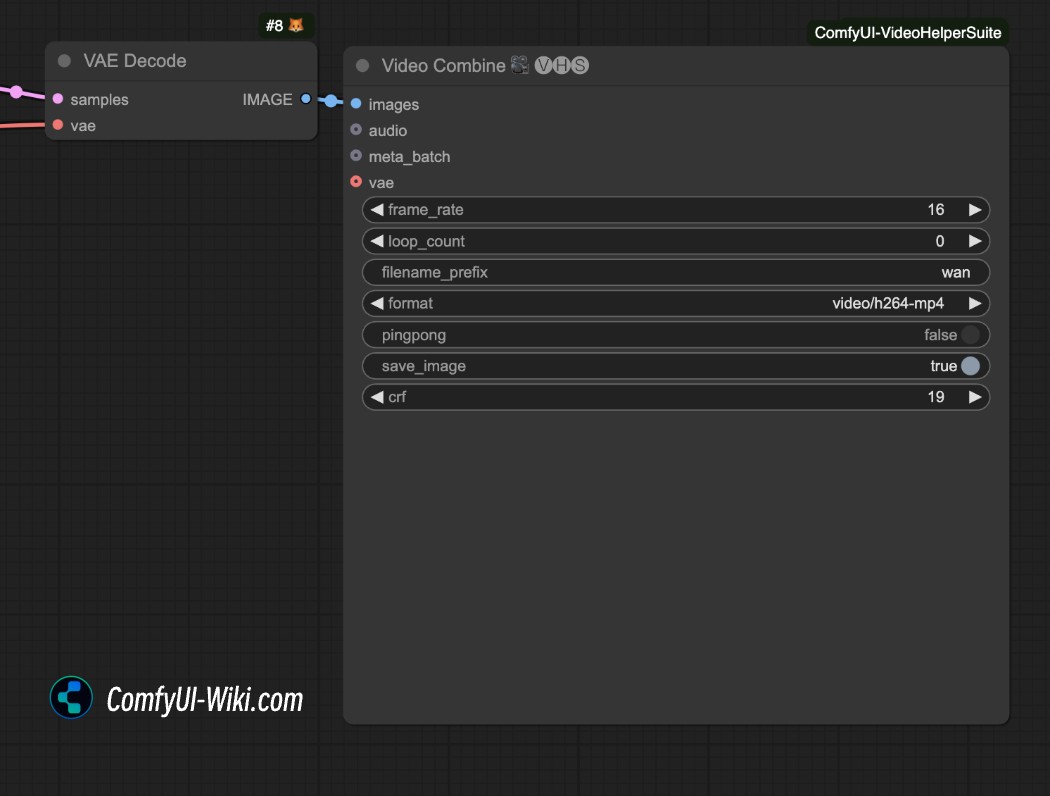
How to save as mp4 format video
The video generation workflow above defaults to generating videos in .webp format. If you want to save in other video formats, you can try using the video Combine node in the ComfyUI-VideoHelperSuite plugin to save as mp4 format video.
Related Resources
All models are now available for download on Hugging Face and ModelScope:
-
T2V-14B: Hugging Face | ModelScope
-
I2V-14B-720P: Hugging Face | ModelScope
-
T2V-1.3B: Hugging Face | ModelScope