HunyuanVideo Image-to-Video GGUF・FP8およびComfyUI Nativeワークフロー完全ガイドと実例
ComfyUIでテンセントのHunyuanVideoモデルを使用して画像から動画を生成する完全なチュートリアル。環境設定、モデルのインストール、ワークフローの使用方法を詳しく説明します
テンセントは2025年3月6日にHunyuanVideo画像から動画生成モデルを正式にリリースしました。現在、モデルはオープンソース化されており、HunyuanVideo-I2Vで入手できます。
以下はHunyuanVideoの全体アーキテクチャ図です
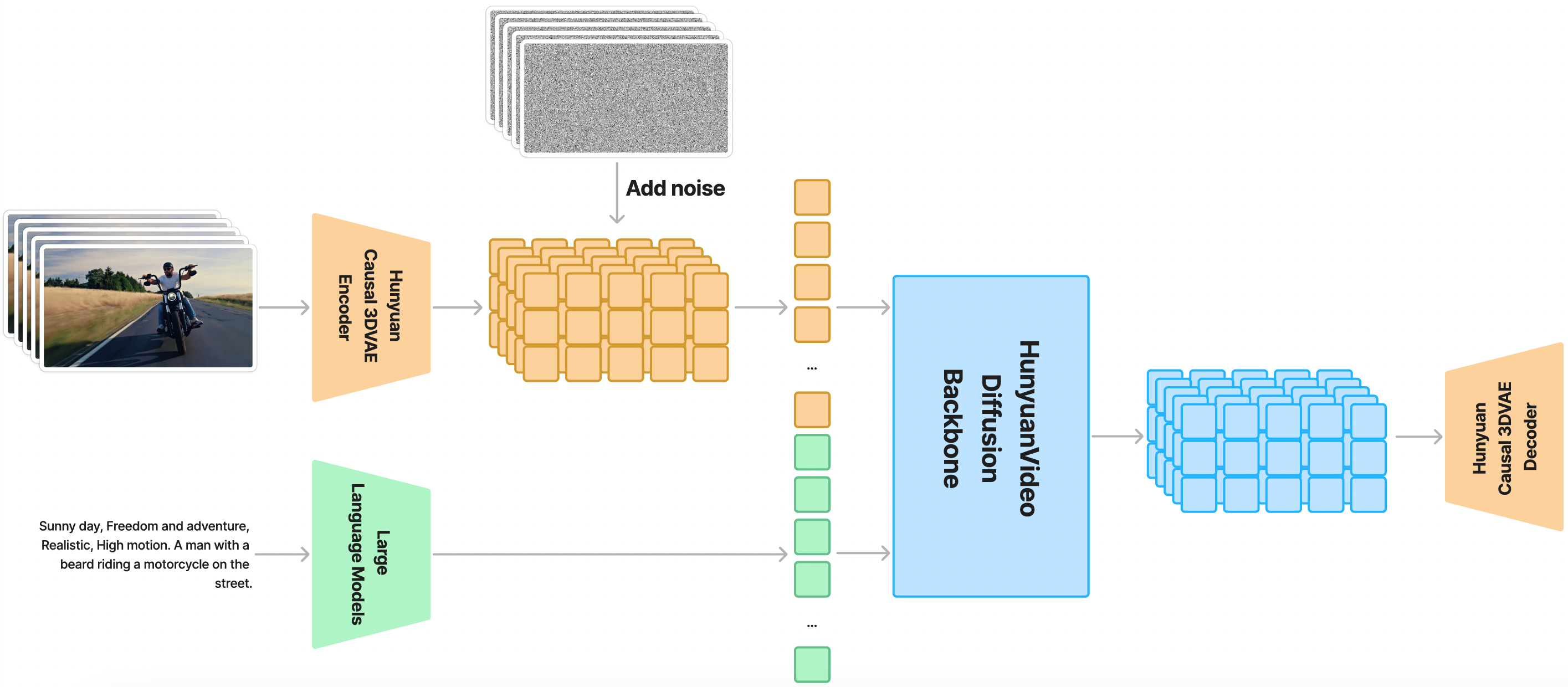
現在、ComfyUI公式がHunyuanVideo-I2Vモデルをネイティブサポートしており、コミュニティ開発者のkijaiとcity96のカスタムノードもHunyuanVideo-I2Vモデルのサポートを更新しています。
テンセント公式版以外に、ComfyUI Wikiで確認できる対応バージョンは以下の通りです:
- ComfyUI公式リパッケージ版(プラグイン不要):Comfy-Org/HunyuanVideo_repackaged
- Kijaiバージョン、ComfyUI-HunyuanVideoWrapperのインストールが必要:Kijai/HunyuanVideo_comfy
- city96パッケージ版、ComfyUI-GGUFのインストールが必要:city96/HunyuanVideo-I2V-gguf
本記事では、これらのバージョンに基づいて、それぞれの完全なモデルのインストールとワークフローの使用例の説明を提供します。
この記事では主に画像から動画生成のワークフローについて説明します。テンセントの混元テキストから動画生成ワークフローについては、テンセント混元テキストから動画生成ワークフローガイドと例を参照してください。
ComfyUI公式 HunyuanVideo I2Vワークフロー
このワークフローはComfyUI公式ドキュメントから取得しています。
このチュートリアルを始める前に、ComfyUIのアップデート方法を参照してComfyUIを最新バージョンに更新してください。これにより、Comfy_CoreのHunyuanVideo関連ノードの不足を防ぐことができます:
- HunyuanImageToVideo
- TextEncodeHunyuanVideo_ImageToVideo
1. HunyuanVideo I2V ワークフローファイル
以下のワークフローファイルをダウンロードし、ComfyUIにドラッグするか、メニューのWorkflows -> Open(ctrl+o)を使用してワークフローを読み込みます。

JSONフォーマットワークフローのダウンロード
2. HunyuanVideo I2V 関連モデルのダウンロード
以下のモデルはすべてComfy-Org/HunyuanVideo_repackagedから入手できます:
- llava_llama3_vision.safetensors
- clip_l.safetensors
- llava_llama3_fp16.safetensors
- llava_llama3_fp8_scaled.safetensors
- hunyuan_video_vae_bf16.safetensors
- hunyuan_video_image_to_video_720p_bf16.safetensors
ダウンロード後、以下のファイル構成に従ってComfyUI/modelsの対応するフォルダに保存してください:
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_image_to_video_720p_bf16.safetensors3. 入力画像
以下の画像を入力画像としてダウンロードしてください

HunyuanVideo I2V ワークフローノードの確認手順
画像を参照して対応するノードの内容を確認し、ワークフローが正常に動作することを確認してください
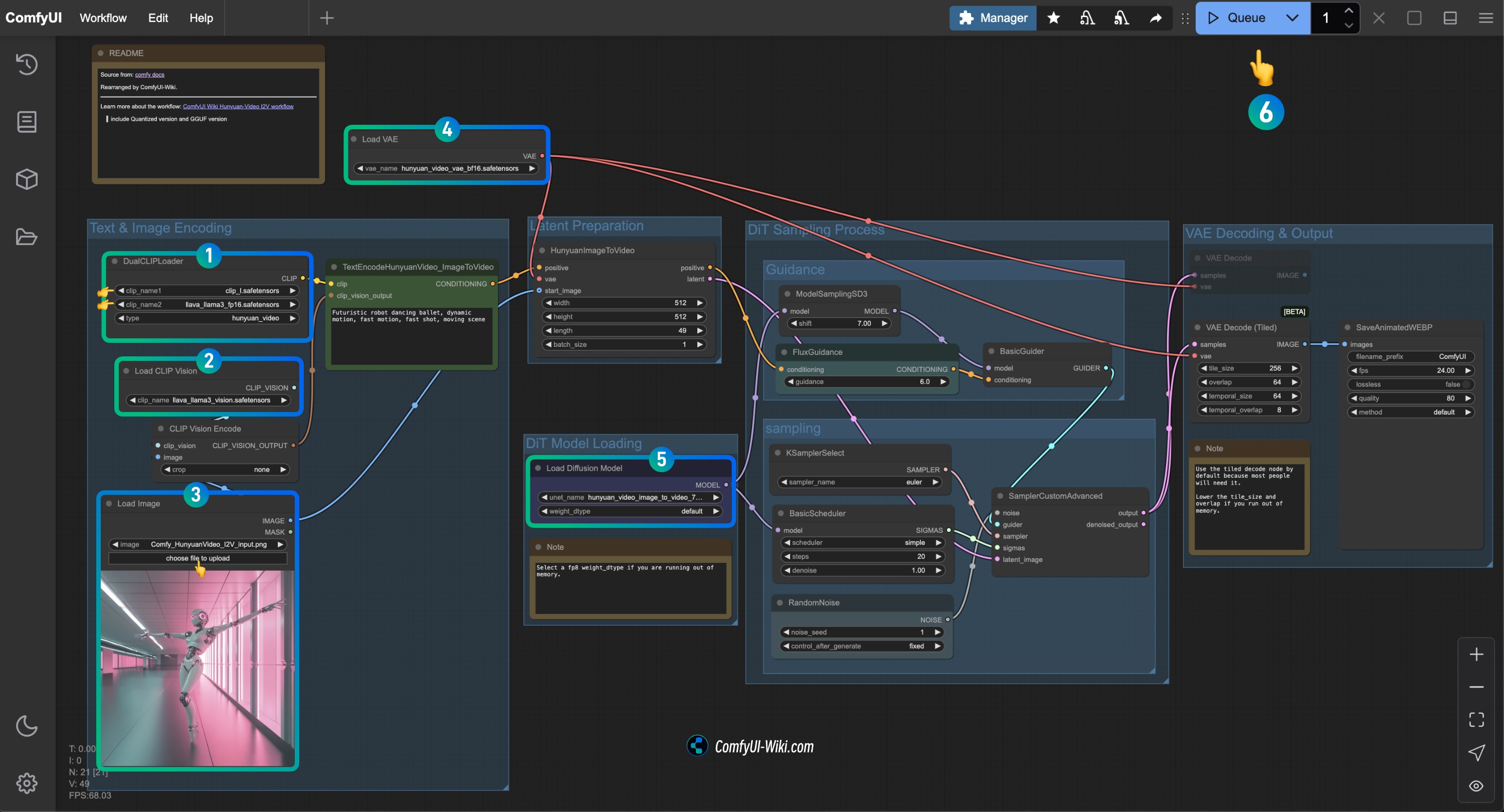
DualCLIPLoaderノードの確認:
clip_name1: clip_l.safetensorsが正しく読み込まれていることを確認clip_name2: llava_llama3_vision.safetensorsが正しく読み込まれていることを確認
Load CLIP Visionノードの確認: llava_llama3_vision.safetensorsが正しく読み込まれていることを確認Load Imageノードで、先ほど提供した入力画像をアップロードLoad VAEノードの確認: hunyuan_video_vae_bf16.safetensorsが正しく読み込まれていることを確認Load Diffusion Modelノードの確認: hunyuan_video_image_to_video_720p_bf16.safetensorsが正しく読み込まれていることを確認
- 実行中に
running out of memory.エラーが発生した場合は、weight_dtypeをfp8タイプに設定してみてください
Runボタンをクリックするか、ショートカットキーCtrl(cmd) + Enterを使用して動画生成を実行
Kijai HunyuanVideoWrapper バージョン
1. カスタムノードのインストール
以下のカスタムノードをインストールする必要があります:
カスタムノードのインストール方法がわからない場合は、ComfyUIカスタムノードインストールガイドを参照してください。
2. モデルのダウンロード
ダウンロード後、以下のファイル構成に従ってComfyUI/modelsの対応するフォルダに保存してください:
ComfyUI/
├── models/
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_I2V_fp8_e4m3fn.safetensors3. HunyuanVideo I2V ワークフローファイル
HunyuanVideo I2V ワークフローノードの確認手順 (Kijai)
画像を参照して対応するノードの内容を確認し、ワークフローが正常に動作することを確認してください
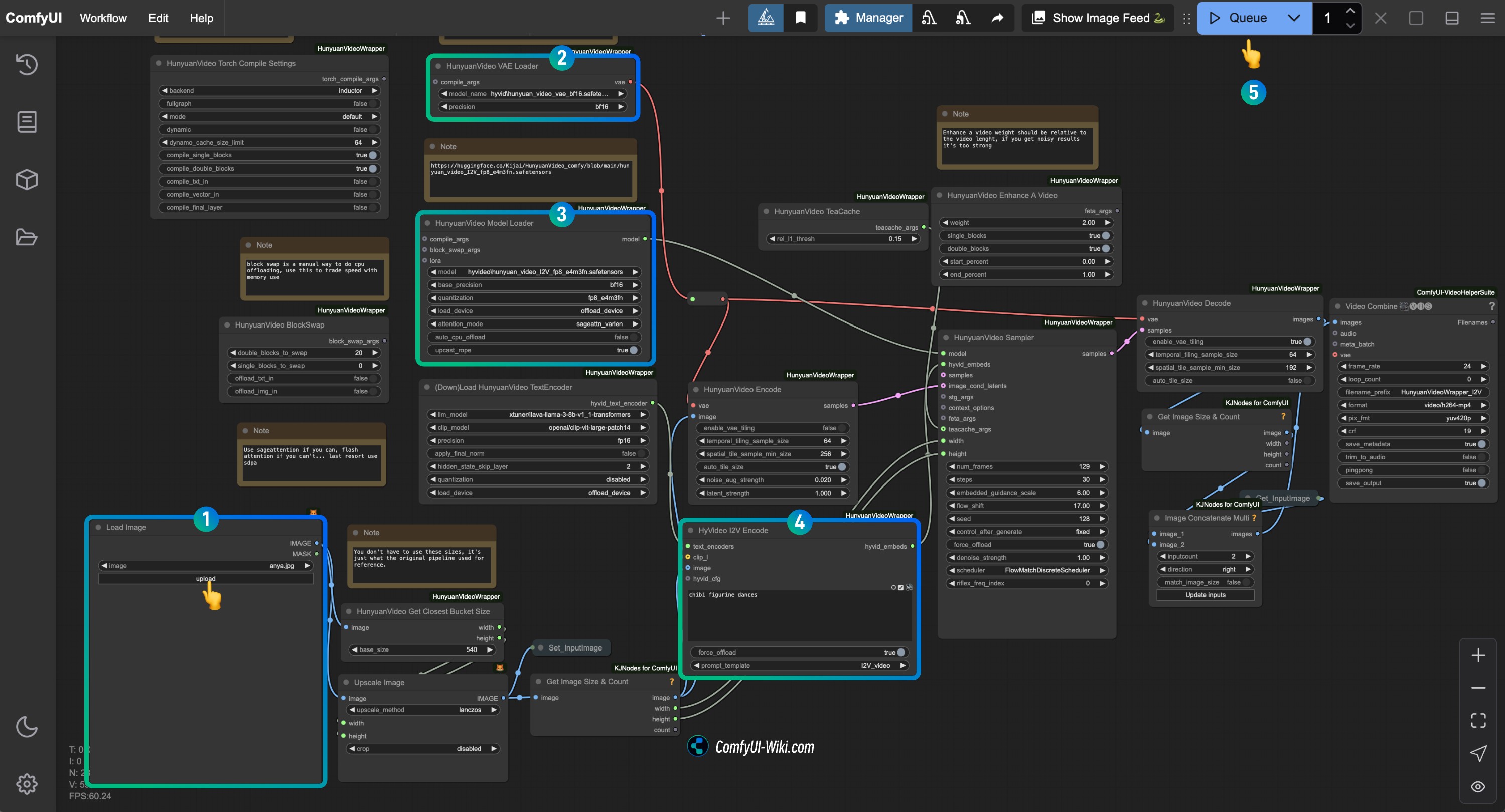
Load Imageノードで、画像から動画を生成したい画像をアップロードHunyuanVideo VAE Loaderノードで、hunyuan_video_vae_bf16.safetensorsが正しく読み込まれていることを確認HunyuanVideo Model Loaderノードで、hunyuan_video_I2V_fp8_e4m3fn.safetensorsが正しく読み込まれていることを確認HyVideo I2V Encodeノードのプロンプトテキストを修正し、生成したい動画の説明を入力Runボタンをクリックするか、ショートカットキーCtrl(cmd) + Enterを使用して動画生成を実行
city96 GGUF バージョン
1. カスタムノードのインストール (GGUF)
以下のカスタムノードをインストールする必要があります:
カスタムノードのインストール方法がわからない場合は、ComfyUIカスタムノードインストールガイドを参照してください。
2. モデルのダウンロード (GGUF)
このパートのモデルは、HunyuanVideoモデル以外は基本的にComfyUI公式版と同じです。対応するモデルについては、本記事のComfyUI公式版の部分を参照して手動でダウンロードしてください。
city96/HunyuanVideo-I2V-ggufにアクセスして必要なバージョンのモデルをダウンロードし、対応するggufモデルファイルをComfyUI/modelsフォルダに保存する必要があります。
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── unet/
│ └── hunyuan-video-i2v-720p-Q4_K_M.gguf // ダウンロードしたバージョンによって異なります3. HunyuanVideo I2V ワークフローファイル (GGUF)
HunyuanVideo I2V ワークフローノードの確認手順 (GGUF)
画像を参照して対応するノードの内容を確認し、ワークフローが正常に動作することを確認してください
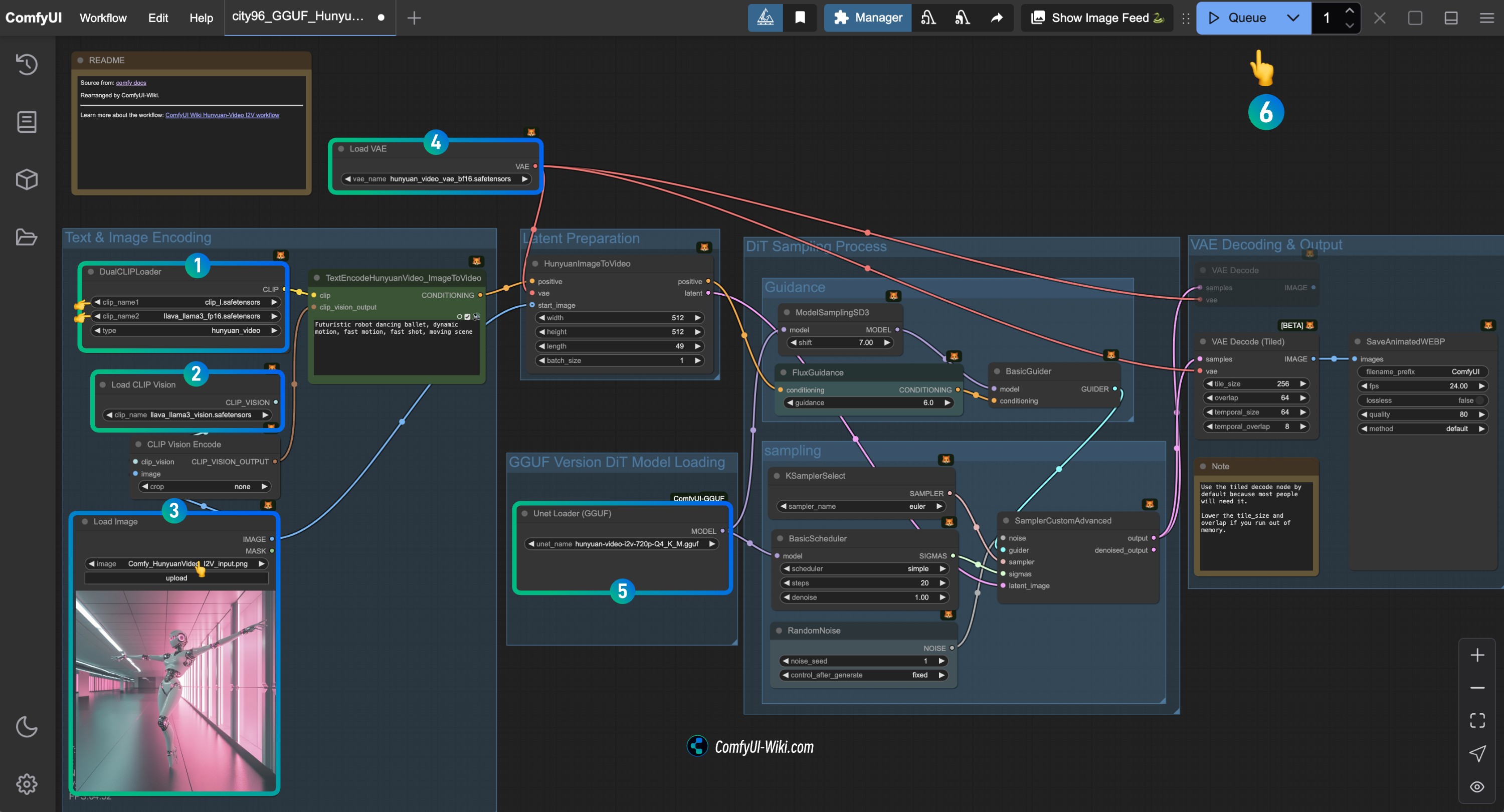
DualCLIPLoaderノードの確認:
clip_name1: clip_l.safetensorsが正しく読み込まれていることを確認clip_name2: llava_llama3_vision.safetensorsが正しく読み込まれていることを確認
Load CLIP Visionノードの確認: llava_llama3_vision.safetensorsが正しく読み込まれていることを確認Load Imageノードで、先ほど提供した入力画像をアップロードLoad VAEノードの確認: hunyuan_video_vae_bf16.safetensorsが正しく読み込まれていることを確認Load Diffusion Modelノードの確認: 対応するHunyuanVideo GGUFモデルが正しく読み込まれていることを確認Runボタンをクリックするか、ショートカットキーCtrl(cmd) + Enterを使用して動画生成を実行
コメント
GitHubでサインインしてディスカッションに参加しましょう。