Wan2.2 ComfyUI ワークフロー完全使用ガイド、公式+コミュニティ版(Kijai、GGUF)ワークフロー全攻略
最も包括的なWan2.2ビデオ ComfyUI チュートリアル:公式ネイティブ版、Kijai WanVideoWrapper、GGUF量子化版、Lightx2v高速生成など複数バージョンのワークフローを含む
チュートリアル概要
このチュートリアルでは、ComfyUIにおけるWan2.2ビデオ生成モデルの様々な実装方法と使用方法を全面的に紹介します。Wan2.2はアリババクラウドが発表した次世代マルチモーダル生成モデルで、革新的なMoE(Mixture of Experts)アーキテクチャを採用し、映画レベルの美学制御、大規模複雑動作生成、正確な意味遵守などの核心的特性を備えています。
本チュートリアルがカバーするバージョンと内容
完成済みバージョン:
- ✅ ComfyUI 公式ネイティブ版 - ComfyOrg公式が提供する完全ワークフロー
- ✅ Wan2.2 5B ハイブリッド版 - テキストから動画へと画像から動画へをサポートする軽量モデル
- ✅ Wan2.2 14B テキストから動画へ版 - テキストから動画への高品質な生成
- ✅ Wan2.2 14B 画像から動画へ版 - 静止画像から動画への生成
- ✅ Wan2.2 14B 先頭末尾フレームビデオ生成 - 開始と終了フレームに基づくビデオ生成
準備中のバージョン:
- 🔄 Kijai WanVideoWrapper 版
- 🔄 GGUF 量子化版 - 低スペックデバイス向けの最適化版
- 🔄 Lightx2v 4steps LoRA - 高速生成最適化ソリューション
Wan2.2 ビデオ生成モデルについて
Wan2.2は革新的なMoE(Mixture of Experts)アーキテクチャを採用し、高ノイズ専門モデルと低ノイズ専門モデルで構成され、デノイズタイムステップに応じて専門モデルを分割することで、より高品質なビデオコンテンツを生成できます。
核心的優位性:
- 映画レベルの美学制御:プロフェッショナルなレンズ言語、光影、色彩、構図など多次元視覚制御をサポート
- 大規模複雑運動:各種複雑運動をスムーズに再現、運動制御性と自然度を強化
- 正確な意味遵守:複雑シーン理解、複数オブジェクト生成、クリエイティブ意図をより良く再現
- 高効率圧縮技術:5B版高圧縮比VAE、メモリ最適化、ハイブリッドトレーニングをサポート
Wan2.2シリーズモデルはApache2.0オープンソースライセンスに基づき、商業利用をサポートします。Apache2.0ライセンスでは、商用利用を含め、これらのモデルを自由に使用、変更、配布できます。元の著作権表示とライセンステキストを保持するだけでOKです。
Wan2.2 オープンソースモデルバージョン概要
| モデルタイプ | モデル名 | パラメータ数 | 主要機能 | モデルリポジトリ |
|---|---|---|---|---|
| ハイブリッドモデル | Wan2.2-TI2V-5B | 5B | テキスト生成ビデオと画像生成ビデオのハイブリッド版、単一モデルで2つの核心タスク要件を満たす | 🤗 Wan2.2-TI2V-5B |
| 画像toビデオ | Wan2.2-I2V-A14B | 14B | 静止画像を動画に変換、コンテンツ一貫性とスムーズな動的プロセスを維持 | 🤗 Wan2.2-I2V-A14B |
| テキストtoビデオ | Wan2.2-T2V-A14B | 14B | テキスト記述から高品質ビデオを生成、映画レベルの美学制御と正確な意味遵守を備える | 🤗 Wan2.2-T2V-A14B |
Wan2.2 プロンプトガイド - Wanが提供する詳細なプロンプト作成ガイド
ComfyUI 公式リソース
ComfyOrg 公式ライブ配信リプレイ
ComfyOrgのYouTubeでは、Wan2.2のComfyUIでの使用について詳細に解説しています:
Wan2.2 ComfyUI 公式ネイティブ版ワークフロー使用ガイド
バージョン説明
ComfyUI公式ネイティブ版はComfyOrgチームが提供し、🤗 Comfy-Org/Wan_2.2_ComfyUI_Repackagedで再パッケージされたモデルファイルを使用し、ComfyUIとの最適な互換性を確保します。
1. Wan2.2 TI2V 5B ハイブリッド版ワークフロー
ワークフロー取得方法
ComfyUIを最新版に更新し、メニューのワークフロー -> テンプレートを閲覧 -> ビデオから"Wan2.2 5B video generation"を見つけてワークフローをロードしてください
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_5B_t2v.mp4"
<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/video_wan2_2_5B_ti2v.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>JSON形式ワークフローをダウンロード
モデルファイルダウンロード
拡散モデル
VAE
テキストエンコーダー
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ └───wan2.2_ti2v_5B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan2.2_vae.safetensors操作手順詳細
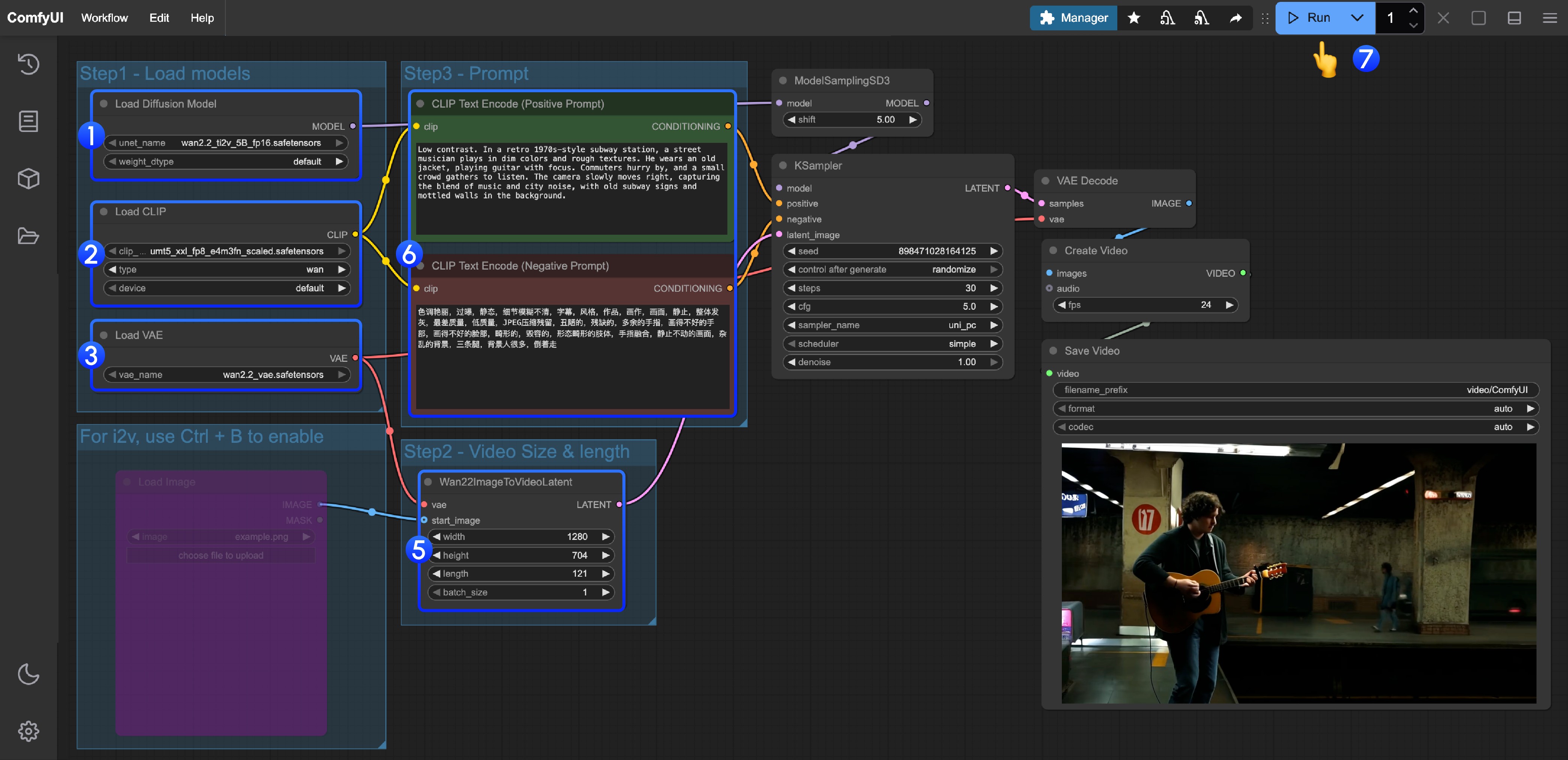
Load Diffusion Modelノードがwan2.2_ti2v_5B_fp16.safetensorsモデルをロードしていることを確認Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルをロードしていることを確認Load VAEノードがwan2.2_vae.safetensorsモデルをロードしていることを確認- (任意)画像toビデオを行う場合、ショートカットキーCtrl+Bで
Load imageノードを有効化して画像をアップロード - (任意)
Wan22ImageToVideoLatentでサイズ設定調整、およびビデオ総フレーム数length調整が可能 - (任意)プロンプト(ポジティブおよびネガティブ)を変更する場合、番号
5のCLIP Text Encoderノードで変更 Runボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でビデオ生成を実行
2. Wan2.2 14B T2V テキストtoビデオワークフロー
ワークフロー取得方法
ComfyUIを最新版に更新し、メニューのワークフロー -> テンプレートを閲覧 -> ビデオから"Wan2.2 14B T2V"を見つけてください
またはComfyUIを最新版に更新後、以下のワークフローをダウンロードしてComfyUIにドラッグしてワークフローをロード
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_14B_t2v.mp4"
モデルファイルダウンロード
拡散モデル
VAE
テキストエンコーダー
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors操作手順詳細
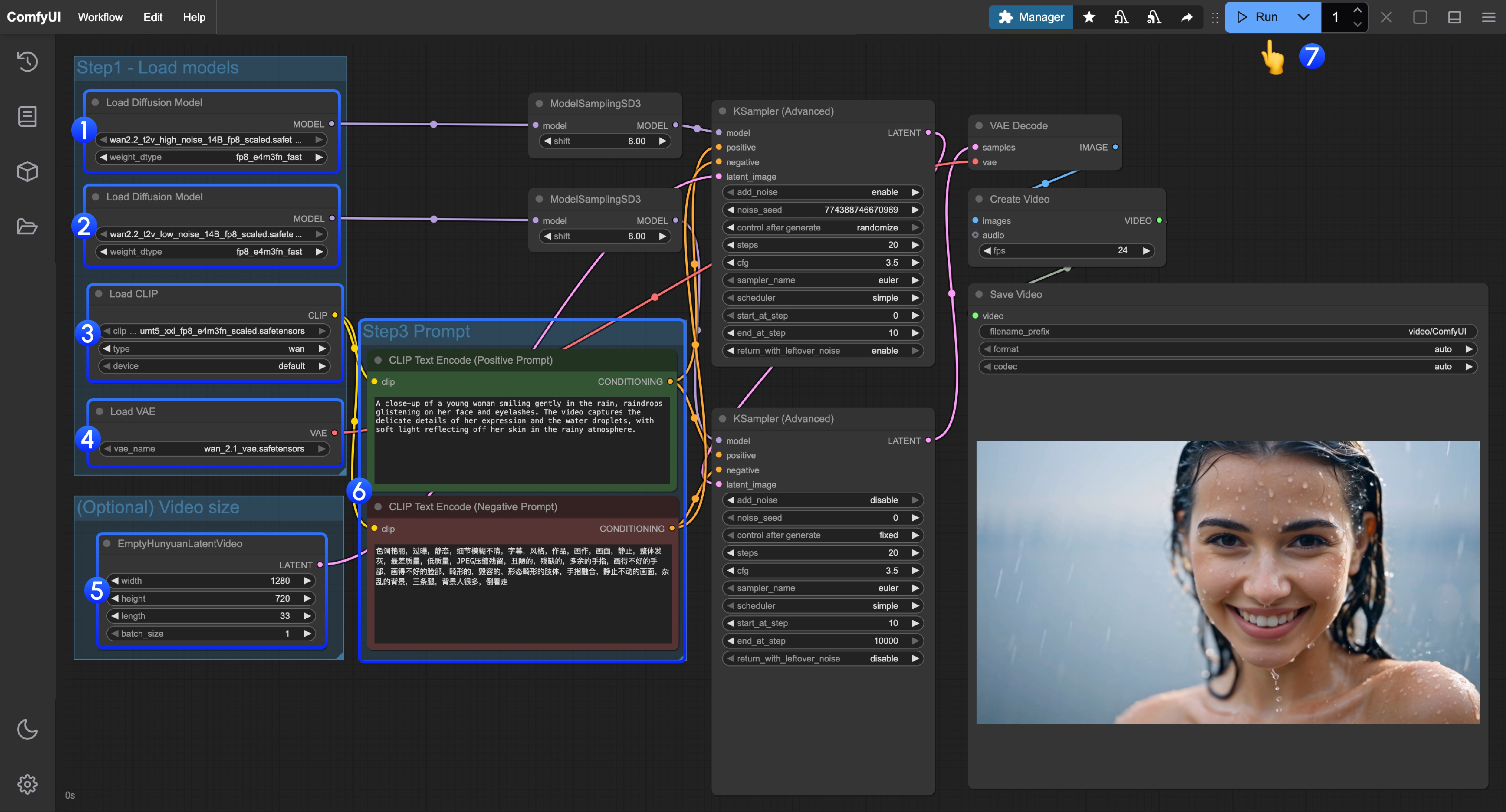
- 最初の
Load Diffusion Modelノードがwan2.2_t2v_high_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認 - 2番目の
Load Diffusion Modelノードがwan2.2_t2v_low_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認 Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルをロードしていることを確認Load VAEノードがwan_2.1_vae.safetensorsモデルをロードしていることを確認- (任意)
EmptyHunyuanLatentVideoでサイズ設定調整、およびビデオ総フレーム数length調整が可能 - プロンプト(ポジティブおよびネガティブ)を変更する場合、番号
6のCLIP Text Encoderノードで変更 Runボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でビデオ生成を実行
3. Wan2.2 14B I2V 画像toビデオワークフロー
ワークフロー取得方法
ComfyUIを最新版に更新し、メニューのワークフロー -> テンプレートを閲覧 -> ビデオから"Wan2.2 14B I2V"を見つけてワークフローをロード
またはComfyUIを最新版に更新後、以下のワークフローをダウンロードしてComfyUIにドラッグしてワークフローをロード
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_14B_i2v.mp4"
以下の画像を入力として使用できます

モデルファイルダウンロード
拡散モデル
VAE
テキストエンコーダー
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_i2v_low_noise_14B_fp16.safetensors
│ │ └─── wan2.2_i2v_high_noise_14B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors操作手順詳細
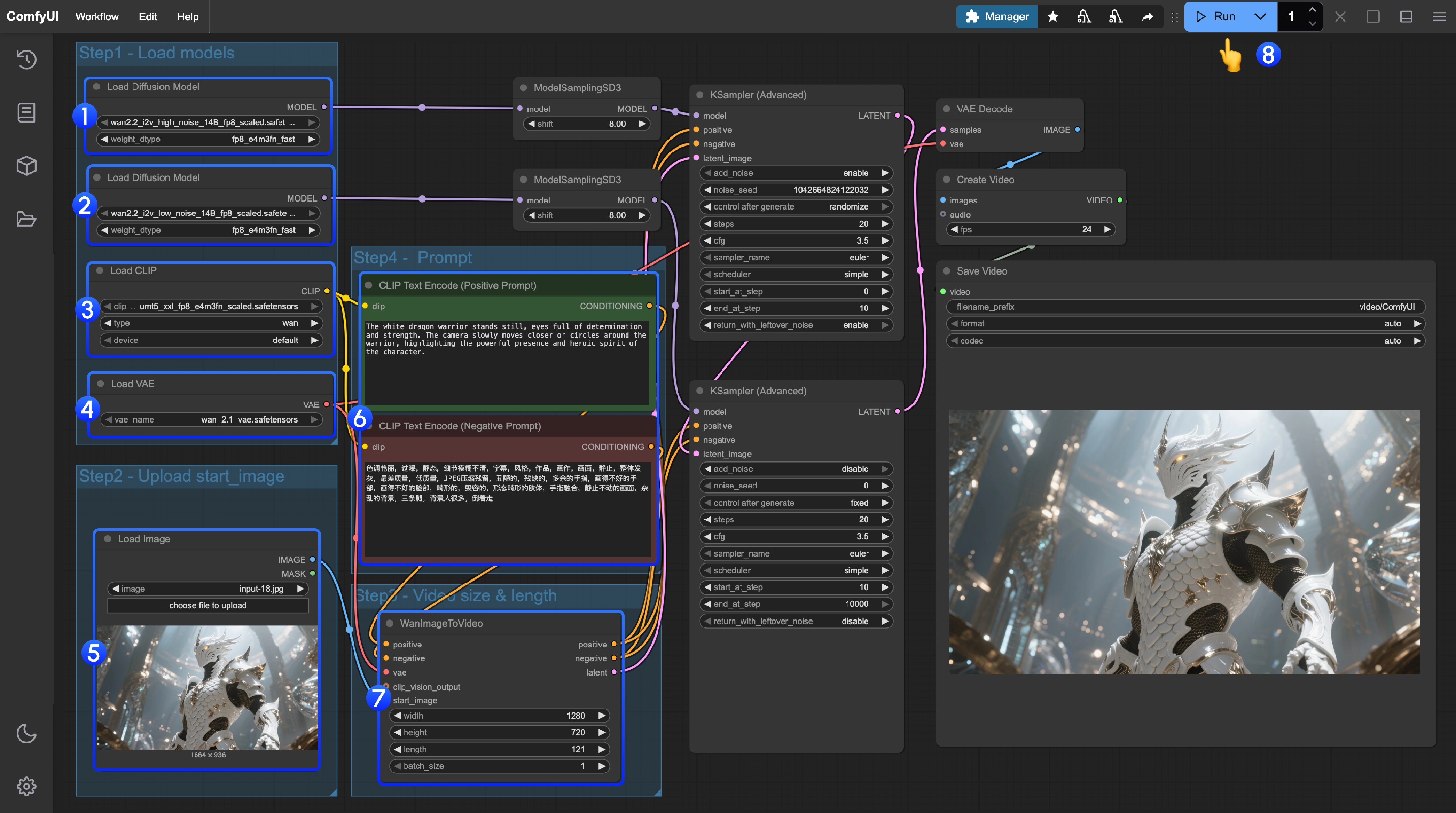
- 最初の
Load Diffusion Modelノードがwan2.2_t2v_high_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認 - 2番目の
Load Diffusion Modelノードがwan2.2_t2v_low_noise_14B_fp8_scaled.safetensorsモデルをロードしていることを確認 Load CLIPノードがumt5_xxl_fp8_e4m3fn_scaled.safetensorsモデルをロードしていることを確認Load VAEノードがwan_2.1_vae.safetensorsモデルをロードしていることを確認Load Imageノードで開始フレームとして画像をアップロード- プロンプト(ポジティブおよびネガティブ)を変更する場合、番号
6のCLIP Text Encoderノードで変更 - (任意)
EmptyHunyuanLatentVideoでサイズ設定調整、およびビデオ総フレーム数length調整が可能 Runボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でビデオ生成を実行
4. Wan2.2 14B FLF2V 先頭末尾フレームビデオ生成ワークフロー
先頭末尾フレームワークフローはI2V部分と完全に同じモデル位置を使用
ワークフローおよび素材取得
以下のビデオまたはJSON形式ワークフローをダウンロードしてComfyUIで開いてください <video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan22_14B_flf2v.mp4"
以下の素材を入力としてダウンロード


操作手順詳細
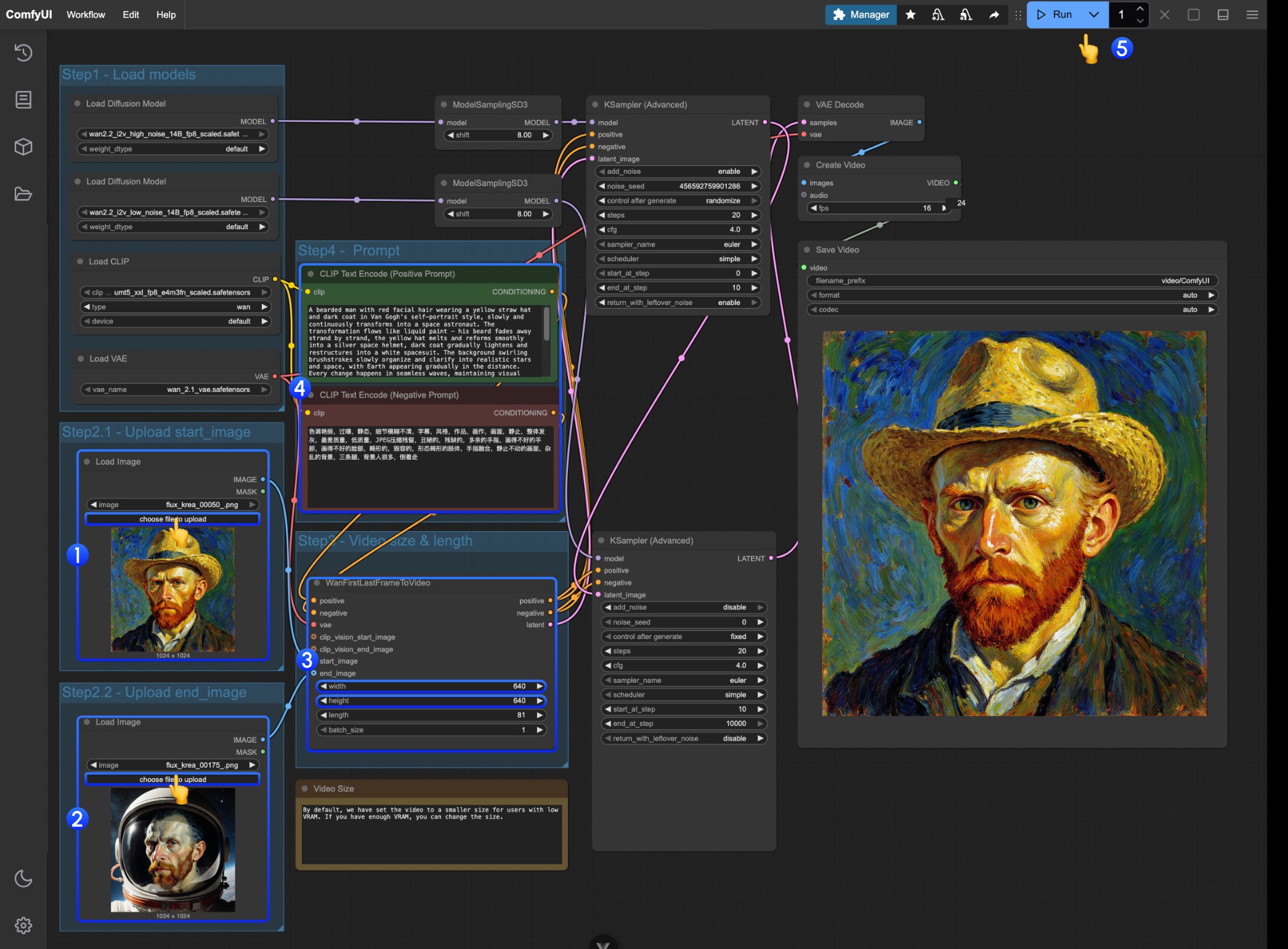
- 最初の
Load Imageノードで開始フレームとして画像をアップロード - 2番目の
Load Imageノードで開始フレームとして画像をアップロード WanFirstLastFrameToVideoでサイズ設定を変更- ワークフローは低VRAMユーザーがリソースを過剰に消費しないように、比較的小さなサイズをデフォルト設定
- 十分なVRAMがある場合、720P程度のサイズを試すことができます
- 先頭末尾フレームに応じた適切なプロンプトを作成
Runボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でビデオ生成を実行
Wan2.2 Kijai WanVideoWrapper ComfyUI ワークフロー
このチュートリアルの一部では、Kijai/ComfyUI-WanVideoWrapperの便利な方法を紹介します。
関連モデルリポジトリ:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Wan2.2 GGUF 量子化版 ComfyUI ワークフロー
GGUF版はVRAMが限られたユーザー向けで、以下のリソースを提供:
関連カスタムノード: City96/ComfyUI-GGUF
Lightx2v 4steps LoRA 使用説明
Lightx2vは高速生成最適化ソリューションを提供:
コメント
GitHubでサインインしてディスカッションに参加しましょう。