Wan2.2-S2V 音声駆動型ビデオ生成 ComfyUI ワークフローとチュートリアル
Wan2.2-S2VでComfyUI上に自然なリップシンクのトーキングアバター動画を作成。モデル設定、S2Vパイプライン、ワークフロー構成例をカバー。
Wan2.2-S2V は、静止画像と音声入力から動的ビデオコンテンツを作成できる AI ビデオ生成技術の大きな進歩を表しています。この革新的なモデルは、自然なリップシンクと表現を持つ同期ビデオを生成するのに優れており、対話シーン、音楽パフォーマンス、キャラクター主導の物語に取り組むコンテンツクリエイターにとって特に価値があります。
モデルのハイライト
- 音声駆動型ビデオ生成: 静止画像と音声を、自然なリップシンクと表現を持つ同期ビデオに変換
- 映画品質: 本物の表情、身体の動き、カメラ言語で映画品質のビデオを生成
- 分単位の生成: 1 回の生成で分単位の長尺ビデオ作成をサポート
- マルチフォーマット対応: 実写人物、アニメ、動物、デジタル人間に対応し、ポートレート、半身、全身フォーマットをサポート
- 強化されたモーション制御: AdaIN と CrossAttention 制御メカニズムでテキスト命令からアクションと環境を生成
- 高性能メトリクス: 優れたビデオ品質とアイデンティティ一貫性のため、FID 15.66、CSIM 0.677、SSIM 0.734 を達成
Wan2.2 S2V ComfyUI ネイティブワークフロー
1. ワークフローファイルのダウンロード
以下のワークフローファイルをダウンロードし、ComfyUI にドラッグしてワークフローをロードします。
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/wan2.2_s2v/wan2.2-s2v.mp4"
入力として以下の画像と音声をダウンロードしてください:

2. モデルリンク
モデルは 当社のリポジトリ で見つけることができます
diffusion_models
audio_encoders
vae
text_encoders
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_s2v_14B_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 audio_encoders/ # このフォルダが見つからない場合は作成してください
│ │ └─── wav2vec2_large_english_fp16.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors3. ワークフロー説明
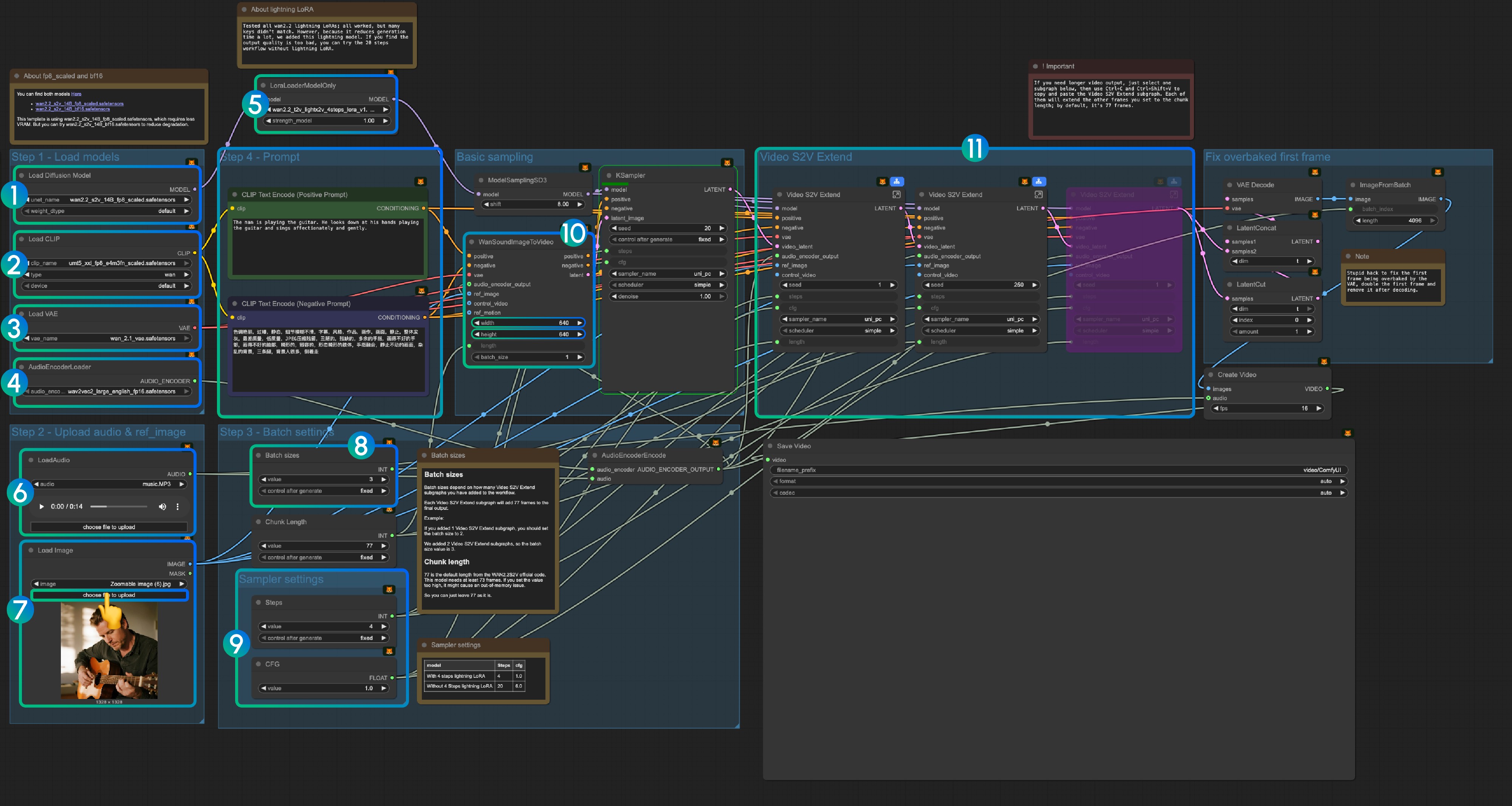
3.1 Lightning LoRA(オプション、高速化用)
Lightning LoRA は生成時間を 20 ステップから 4 ステップに短縮しますが、品質に影響する可能性があります。クイックプレビュー用に使用し、最終出力では無効にしてください。
3.1.1 音声前処理のヒント
より良い結果のためのボーカル分離: ComfyUI コアにはボーカル分離ノードが含まれていないため、処理前に外部ツールを使用してボーカルと BGM を分離することをお勧めします。これは、特にダイアログやリップシンク生成において重要で、クリーンなボーカルトラックは、BGM やノイズを含むミックスされた音声よりもはるかに良い結果を生み出します。
3.2 fp8_scaled と bf16 モデルについて
両方のモデルは こちら で見つけることができます:
テンプレートは VRAM 使用量を減らすために wan2.2_s2v_14B_fp8_scaled.safetensors を使用しています。より良い品質を得るために wan2.2_s2v_14B_bf16.safetensors を試してください。
3.3 ステップバイステップ操作説明
ステップ 1: モデルのロード
- 拡散モデルのロード:
wan2.2_s2v_14B_fp8_scaled.safetensorsまたはwan2.2_s2v_14B_bf16.safetensorsをロード- ワークフローは VRAM 要件を減らすために
wan2.2_s2v_14B_fp8_scaled.safetensorsを使用 - より良い品質の出力のために
wan2.2_s2v_14B_bf16.safetensorsを使用
- ワークフローは VRAM 要件を減らすために
- CLIP のロード:
umt5_xxl_fp8_e4m3fn_scaled.safetensorsをロード - VAE のロード:
wan_2.1_vae.safetensorsをロード - AudioEncoderLoader:
wav2vec2_large_english_fp16.safetensorsをロード - LoraLoaderModelOnly:
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensorsをロード (Lightning LoRA)- この LoRA は生成時間を短縮しますが、品質に影響する可能性があります
- 出力品質が不十分な場合は無効にしてください
- LoadAudio: 提供された音声ファイルまたは独自の音声をアップロード
- Load Image: 参照画像をアップロード
- バッチサイズ: Video S2V Extend サブグラフノードの数に応じて設定
- 各 Video S2V Extend サブグラフは出力に 77 フレームを追加
- 例: Video S2V Extend サブグラフ 2 個 = バッチサイズ 3
- チャンク長: デフォルト値 77 を保持
- サンプラー設定: Lightning LoRA の使用に応じて選択
- 4 ステップ Lightning LoRA 使用時: steps: 4, cfg: 1.0
- Lightning LoRA 非使用時: steps: 20, cfg: 6.0
- サイズ設定: 出力ビデオの寸法を設定
- Video S2V Extend: ビデオ拡張サブグラフノード
- 各拡張は 77 / 16 = 4.8125 秒のビデオを生成
- 必要なノードの計算: 音声長(秒)× 16 ÷ 77
- 例: 14 秒音声 = 224 フレーム ÷ 77 = 拡張ノード 3 個
- Ctrl-Enter を使用するか、実行ボタンをクリックしてワークフローを実行
関連リンク
- Wan2.2 S2V コード: GitHub
- Wan2.2 S2V モデル: Hugging Face
コメント
GitHubでサインインしてディスカッションに参加しましょう。