ComfyUI Frame Packワークフロー完全ステップバイステップチュートリアル
このチュートリアルでは、ComfyUIでFrame Packワークフローを使用する方法について、詳細なステップバイステップの手順を提供します。
FramePackは、ControlNetの作者であるスタンフォード大学のLvmin Zhang博士のチームによって開発されたAIビデオ生成技術です。その主な特徴は以下の通りです:
- 動的コンテキスト圧縮:ビデオフレームを重要性に基づいて分類し、キーフレームは1536の特徴マーカーを保持する一方、遷移フレームは192に簡略化されます。
- ドリフト耐性サンプリング:双方向メモリ法と逆生成技術を利用して、画像のドリフトを回避し、アクションの連続性を確保します。
- VRAM要件の削減:ビデオ生成のためのVRAMしきい値をプロフェッショナルグレードのハードウェア(12GB+)から消費者レベル(わずか6GB VRAM)に下げ、一般ユーザーがRTX 3060ラップトップで最大60秒の高品質ビデオを生成できるようにします。
- オープンソースと統合:FramePackは現在オープンソース化され、テンセントのHunyuanビデオモデルに統合されており、マルチモーダル入力(テキスト+画像+音声)とリアルタイムインタラクティブ生成をサポートしています。
Frame Packに関連する元のリンク
- オリジナルリポジトリ:https://github.com/lllyasviel/FramePack/
- ComfyUIなしでWindowsにワンクリックで実行する統合パッケージ:https://github.com/lllyasviel/FramePack/releases/tag/windows
対応するプロンプト
lllyasvielは対応するリポジトリでビデオ生成用のGPTプロンプトを提供しています。Frame Packワークフローを使用する際にプロンプトの書き方が分からない場合は、以下を試してみてください:
- 以下のプロンプトをコピーしてGPTに送信します。
- GPTが要件を理解したら、対応する画像を提供すると、適切なプロンプトが得られます。
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.
## ComfyUIにおけるFrame Packの現在の実装
現在、ComfyUIでFrame Pack機能を実装したカスタムノード作者は3人います:
- Kijai:[ComfyUI-FramePackWrapper](https://github.com/kijai/ComfyUI-FramePackWrapper)
- HM-RunningHub:[ComfyUI_RH_FramePack](https://github.com/HM-RunningHub/ComfyUI_RH_FramePack)
- TTPlanetPig:[TTP_Comfyui_FramePack_SE](https://github.com/TTPlanetPig/TTP_Comfyui_FramePack_SE)
### これらのカスタムノードの違い
以下では、これらのカスタムノードで実装されたワークフローの違いを説明します。
### Kijaiのカスタムプラグイン
Kijaiは対応するモデルを再パッケージ化しており、Kijaiの関連カスタムノードを使用したことがあると思いますが、彼のおかげでこのような迅速な更新が実現しています!
KijaiのバージョンはComfyUI Managerに登録されていないようなので、現在はManagerのカスタムノードマネージャーを通じてインストールすることはできません。ManagerのGitを介して、または手動でインストールする必要があります。
**特徴**:
- 最初と最後のフレームによるビデオ生成をサポート
- Gitを介したインストールまたは手動インストールが必要
- モデルが再利用可能
### HM-RunningHubとTTPlanetPigのカスタムプラグイン
これら2つのカスタムノードは同じコードに基づいた修正バージョンで、元々はHM-RunningHubによって作成され、その後TTPlanetPigが対応するプラグインのソースコードに基づいて最初と最後のフレームによるビデオ生成を実装しました。この[PR](https://github.com/lllyasviel/FramePack/pull/167)を確認できます。
これら2つのカスタムノードで使用されるモデルのフォルダ構造は一貫しており、どちらも再パッケージ化されていないオリジナルリポジトリのモデルファイルを使用しています。そのため、これらのモデルファイルはこのフォルダ構造をサポートしない他のカスタムノードでは使用できず、ディスク容量の使用量が大きくなります。
**特徴**:
- 最初と最後のフレームによるビデオ生成をサポート
- ダウンロードしたモデルファイルは他のノードやワークフローでは再利用できない場合がある
- モデルファイルが再パッケージ化されていないため、より多くのディスク容量を占有
- 依存関係に関するいくつかの互換性問題
<div data-mdx="Callout" data-p="%7B%7D">
さらに、操作中にエラーが発生し、現在これらの互換性の問題を解決できません。そのため、この記事は関連情報のみを提供しています。ただし、最初と最後のフレームはKijaiのバージョンでも実装できるため、これら2つのプラグインは補足情報にすぎません。Kijaiのバージョンを第一選択として使用することをお勧めします。
</div>
## Kijai ComfyUI-FramePackWrapper FLF2V ComfyUIワークフロー
### 1. プラグインのインストール
- [ComfyUI-KJNodes](https://github.com/kijai/ComfyUI-KJNodes)
- [ComfyUI-VideoHelperSuite](https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite)
- [ComfyUI_essentials](https://github.com/cubiq/ComfyUI_essentials)
- [ComfyUI-FramePackWrapper](https://github.com/kijai/ComfyUI-FramePackWrapper)
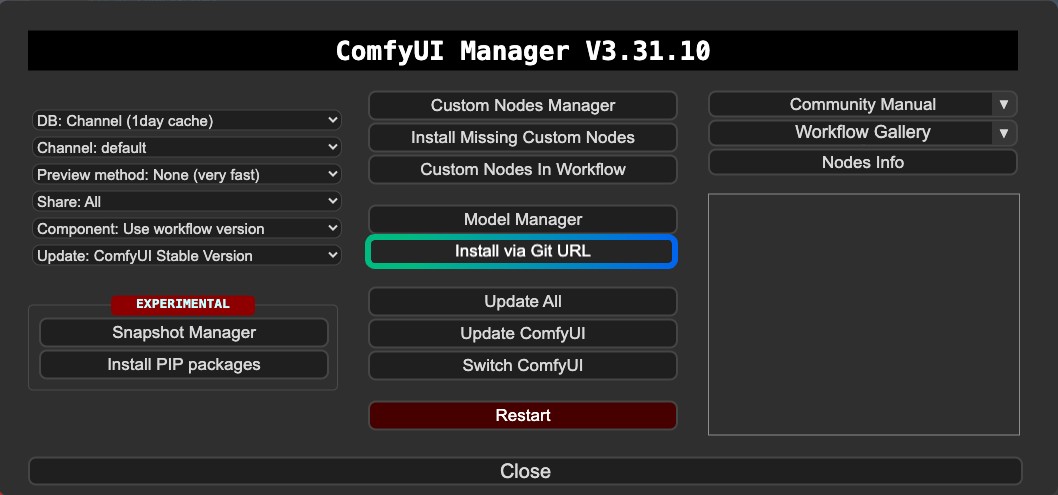
`ComfyUI-FramePackWrapper`については、マネージャーのGitを使用してインストールする必要があるかもしれません:
以下の記事が役立つかもしれません:
- [カスタムノードのインストール方法](/ja/install/install-custom-nodes)
- [「このアクションはこのセキュリティレベル構成では許可されていません」問題の解決](/ja/faq/fix-comfyui-manager-security-level-error)
### 2. ワークフローファイルのダウンロード
以下のビデオファイルをダウンロードし、ComfyUIにドラッグして対応するワークフローをロードします。ファイルにモデル情報を追加したので、モデルのダウンロードを促します。
<div data-mdx="DownloadJson" data-p="%7B%22file%22%3A%22https%3A%2F%2Fraw.githubusercontent.com%2Fcomfyui-wiki%2FComfyUI-Wiki-Workflows%2Fmain%2Fworkflows%2Fvideo%2Fframepack%2FKijai_FLF2V_framepack.json%22%2C%22text%22%3A%22Kijai%E3%81%AE%E6%9C%80%E5%88%9D%E3%81%A8%E6%9C%80%E5%BE%8C%E3%81%AE%E3%83%95%E3%83%AC%E3%83%BC%E3%83%A0FramePack%E3%83%93%E3%83%87%E3%82%AA%E7%94%9F%E6%88%90%E3%83%AF%E3%83%BC%E3%82%AF%E3%83%95%E3%83%AD%E3%83%BC%E3%82%92%E3%83%80%E3%82%A6%E3%83%B3%E3%83%AD%E3%83%BC%E3%83%89%E3%81%99%E3%82%8B%E3%81%AB%E3%81%AF%E3%82%AF%E3%83%AA%E3%83%83%E3%82%AF%22%7D"></div>
<div data-mdx="Callout" data-p="%7B%7D">
ComfyUIフロントエンドの最近の更新により、フロントエンドのバージョンが1.16.9以降であることを確認してください。そうでない場合、このワークフローはロード後にウィジェットの損失問題に遭遇する可能性があります。
詳細については、こちらをご覧ください:<a href="/ja/faq/widget-input-lost">ComfyUIワークフローをインポートした後にウィジェットが消え、設定や調整ができなくなる</a>
</div>
**ビデオプレビュー**
<video controls>
<source src="https://raw.githubusercontent.com/comfyui-wiki/ComfyUI-Wiki-Workflows/main/workflows/video/framepack/Kijai_FLF2V_framepack.mp4" type="video/mp4"/>
</video>
以下の画像をダウンロードして、画像入力として使用します。


### 3. モデルの手動インストール
ワークフローでモデルを正常にダウンロードできない場合は、以下のモデルをダウンロードして対応する場所に保存してください。
**CLIP Vision**
- [sigclip_vision_patch14_384.safetensors](https://huggingface.co/Comfy-Org/sigclip_vision_384/resolve/main/sigclip_vision_patch14_384.safetensors?download=true)
**VAE**
- [hunyuan_video_vae_bf16.safetensors](https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/resolve/main/split_files/vae/hunyuan_video_vae_bf16.safetensors?download=true)
**テキストエンコーダー**
- [clip_l.safetensors](https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/resolve/main/split_files/text_encoders/clip_l.safetensors?download=true)
- [llava_llama3_fp16.safetensors](https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/resolve/main/split_files/text_encoders/llava_llama3_fp16.safetensors?download=true)
**ディフュージョンモデル** Kijaiは異なる精度で2つのバージョンを提供しています。グラフィックカードのパフォーマンスに基づいて1つを選んでダウンロードできます。
| ファイル名 | 精度 | サイズ | ダウンロードリンク | グラフィックカード要件 |
|----------------------------------------|-------|-------|-------------------------------------------------------------------------------------------------------------------|---------------------|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | [ダウンロードリンク](https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/FramePackI2V_HY_bf16.safetensors) | 高 |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | [ダウンロードリンク](https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/FramePackI2V_HY_fp8_e4m3fn.safetensors) | 低 |
**ファイル保存場所**📂 ComfyUI/ ├──📂 models/ │ ├──📂 diffusion_models/ │ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # または bf16精度 │ ├──📂 text_encoders/ │ │ ├─── clip_l.safetensors │ │ └─── llava_llama3_fp16.safetensors │ ├──📂 clip_vision/ │ │ └── sigclip_vision_patch14_384.safetensors │ └──📂 vae/ │ └── hunyuan_video_vae_bf16.safetensors
### 4. 対応するワークフローをステップバイステップで完了
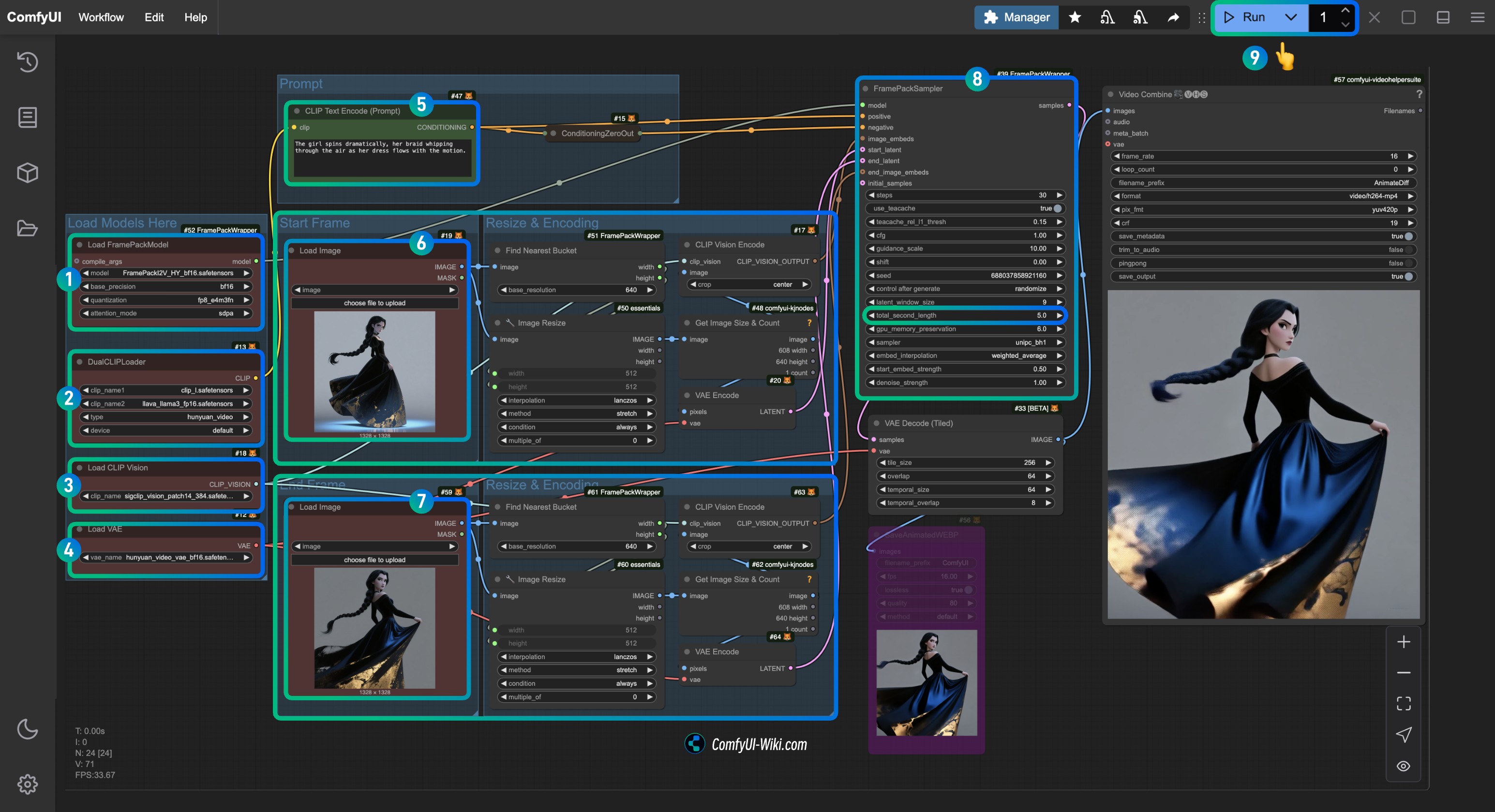
1. `Load FramePackModel`ノードが`FramePackI2V_HY_fp8_e4m3fn.safetensors`モデルをロードしていることを確認します。
2. `DualCLIPLoader`ノードが以下をロードしていることを確認します:
- `clip_l.safetensors`モデル
- `llava_llama3_fp16.safetensors`モデル
3. `Load CLIP Vision`ノードが`sigclip_vision_patch14_384.safetensors`モデルをロードしていることを確認します。
4. `Load VAE`ノードに`hunyuan_video_vae_bf16.safetensors`モデルをロードできます。
5. (オプション、私の入力画像を使用している場合)`CLIP Text Encoder`ノードの`Prompt`パラメータを変更して、生成したいビデオの説明を入力します。
6. `Load Image`ノードで、`first_frame`の入力処理に関連する`first_frame.jpg`をロードします。
7. `Load Image`ノードで、`last_frame`の入力処理に関連する`last_frame.jpg`をロードします(最後のフレームが必要ない場合は、削除するかBypassを使用して無効にできます)。
8. `FramePackSampler`ノードで、`total_second_length`パラメータを変更してビデオの長さを変更できます。私のワークフローでは`5`秒に設定されており、必要に応じて調整できます。
9. `Run`ボタンをクリックするか、ショートカット`Ctrl(cmd) + Enter`を使用してビデオ生成を実行します。
最後のフレームが必要ない場合は、`last_frame`に関連する入力処理全体をバイパスしてください。