Lumina Image 2.0 ComfyUI ワークフロー例
Lumina Image 2.0 モデルの ComfyUI での使用方法について、モデルのインストール、ワークフロー設定、パラメータ最適化のヒントを含む詳細なガイドです。
 Lumina-Image-2.0 は、Alpha-VLLM チームが 2025 年の旧正月期間中にオープンソース化したテキストから画像へ生成するモデルです。パラメータ数は 2.6B で、DiT アーキテクチャに基づいており、画質、構図、プロンプト理解において優れたパフォーマンスを示します。
Lumina-Image-2.0 は、Alpha-VLLM チームが 2025 年の旧正月期間中にオープンソース化したテキストから画像へ生成するモデルです。パラメータ数は 2.6B で、DiT アーキテクチャに基づいており、画質、構図、プロンプト理解において優れたパフォーマンスを示します。
Lumina-Image-2.0 Github: https://github.com/Alpha-VLLM/Lumina-Image-2.0 Lumina-Image-2.0 huggingface: https://huggingface.co/Alpha-VLLM/Lumina-Image-2.0 オンラインデモ 1 (中国語): https://magic-animation.intern-ai.org.cn/image/create オンラインデモ (Gradio): http://47.100.29.251:10010/
本記事では ComfyUI Example に基づいて例を説明します。
Lumina Image 2.0 ワークフロー例
1. Lumina Image 2.0 モデルのダウンロードとインストール
| 名称 | サイズ | インストール場所 | ダウンロードリンク |
|---|---|---|---|
| Lumina Image 2.0 | 10.6GB | ComfyUI/models/checkpoints | ダウンロード |
📁ComfyUI
└── 📁models
└── 📁checkpoints
└── lumina_2.safetensors // このファイルの場所にモデルを保存してください2. Lumina Image 2.0 ComfyUI ワークフロー
下のボタンをクリックして、対応する ComfyUI ワークフローをダウンロードし、ComfyUI で開いてください
Lumina Image 2.0 ワークフローの説明
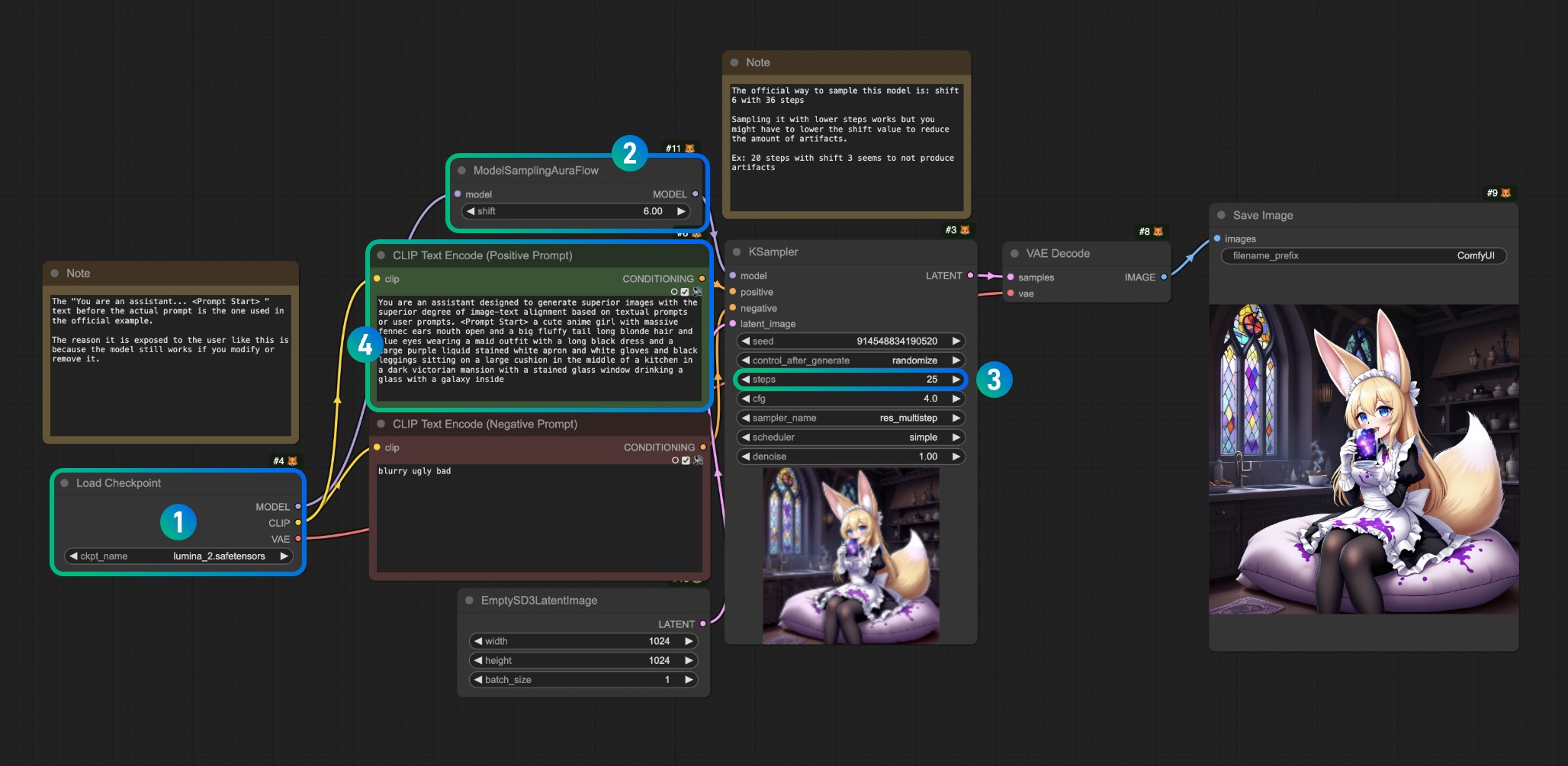
画像を参照し、各番号に対応する操作を実行してください
- Load Checkpoint で
lumina_2.safetensorsモデルが正しく読み込まれていることを確認してください。対応するモデルが見つからない場合は、モデルの場所を確認するか、ComfyUI を更新または再起動してください
対応するモデルを読み込んだ後、Queue またはショートカットキー Ctrl(Command)+Enter を使用してワークフローを実行し、画像を生成します
番号 3 のサンプリングステップ数を変更する場合、番号 2 のシフト値を比例的に調整できます
例:
- ステップ 36 はシフト 6 に対応
- ステップ 20 はシフト 3 に対応
コメント
GitHubでサインインしてディスカッションに参加しましょう。