CLIP Text Encode SDXL
ComfyUIのCLIP Text Encode SDXLノードについて学びます。このノードは、SDXLアーキテクチャに特化したCLIPモデルを使用してテキスト入力をエンコードし、画像生成や操作タスクに適した形式にテキスト記述を変換します。
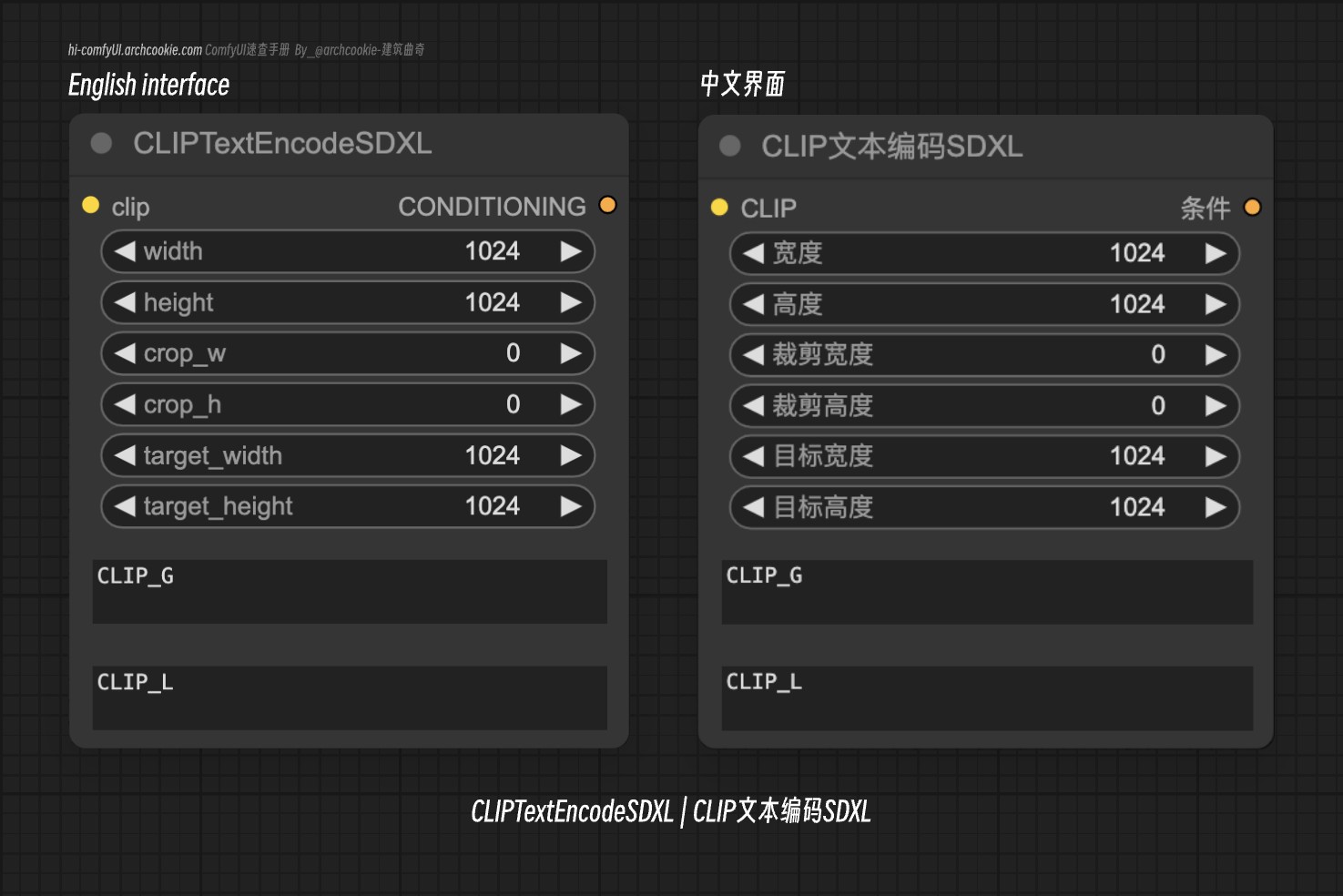 ## ドキュメンテーション
- クラス名: `CLIPTextEncodeSDXL`
- カテゴリ: `advanced/conditioning`
- 出力ノード: `False`
## ドキュメンテーション
- クラス名: `CLIPTextEncodeSDXL`
- カテゴリ: `advanced/conditioning`
- 出力ノード: `False`
このノードは、SDXLアーキテクチャに特化したCLIPモデルを使用してテキスト入力をエンコードするように設計されています。テキスト記述を画像生成や操作に効果的に利用できる形式に変換することに重点を置いており、視覚コンテンツの文脈でテキストを理解し処理するためのCLIPモデルの能力を活用します。
CLIPTextEncodeSDXL 入力タイプ
| パラメータ | Comfy dtype | 説明 |
|---|---|---|
clip | CLIP | テキストをエンコードするために使用されるCLIPモデルインスタンスです。テキスト入力を処理し、画像生成や操作タスクに適した形式に変換する上で重要な役割を果たします。 |
width | INT | 画像の幅をピクセル単位で指定します。生成または操作された出力画像の寸法を決定します。 |
height | INT | 画像の高さをピクセル単位で指定します。生成または操作された出力画像の寸法を決定します。 |
crop_w | INT | ピクセル単位でのクロップ領域の幅を定義します。このパラメータは、処理前に画像を特定の幅にクロップするために使用されます。 |
crop_h | INT | ピクセル単位でのクロップ領域の高さを定義します。このパラメータは、処理前に画像を特定の高さにクロップするために使用されます。 |
target_width | INT | 処理後の出力画像の目標幅です。画像を希望の幅にリサイズすることができます。 |
target_height | INT | 処理後の出力画像の目標高さです。画像を希望の高さにリサイズすることができます。 |
text_g | STRING | エンコードされるグローバルなテキスト記述です。この入力は、対応する視覚表現を生成し、記述された内容を理解するために重要です。 |
text_l | STRING | エンコードされるローカルなテキスト記述です。この入力は、グローバルな記述に追加の詳細や文脈を提供し、生成または操作された画像の特異性を高めます。 |
CLIPTextEncodeSDXL 出力タイプ
| パラメータ | Comfy dtype | 説明 |
|---|---|---|
conditioning | CONDITIONING | ノードの出力であり、エンコードされたテキストと画像生成や操作タスクに必要な追加情報を含みます。 |
コメント
GitHubでサインインしてディスカッションに参加しましょう。