Qwen-Image ComfyUI ネイティブ、GGUF、ナンチャク ワークフロー完全使用ガイド
Qwen-Image は Apache 2.0 ライセンスの下でオープンソース化された 20B パラメータの MMDiT(マルチモーダル拡散変換器)モデルです。
Qwen-Image はアリババの通義千問チームが開発した画像生成基礎モデルで、20B パラメータの MMDiT(マルチモーダル拡散変換器)アーキテクチャを採用し、Apache 2.0 ライセンスの下でオープンソースとして公開されています。このモデルは画像生成分野で独自の技術的優位性を示しており、特にテキストレンダリングと画像編集で優れた性能を発揮します。
主な特徴:
- 多言語テキストレンダリング能力:英語、中国語、韓国語、日本語など複数の言語を含む画像を正確に生成でき、テキストは明確で読みやすく、画像スタイルと調和します
- 豊富なアートスタイル対応:リアリスティックスタイルからアート創作、アニメスタイルからモダンデザインまで、プロンプトに応じて柔軟に異なるビジュアルスタイルを切り替えることができます
- 精密な画像編集機能:既存画像の部分的修正、スタイル変換、コンテンツ追加等の操作をサポートし、全体の視覚的一貫性を維持します
関連リソース:
Qwen-Image ComfyUI ネイティブワークフローガイド
本ドキュメントに付属のワークフローで使用される異なるモデルは以下の3種類です:
- Qwen-Image オリジナルモデル fp8_e4m3fn
- 8ステップ高速版:Qwen-Image オリジナルモデル fp8_e4m3fn に lightx2v 8ステップ LoRA を使用
- 蒸留版:Qwen-Image 蒸留版モデル fp8_e4m3fn
VRAM使用量参考 GPU: RTX4090D 24GB
| 使用モデル | VRAM使用量 | 初回生成 | 2回目生成 |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn に lightx2v 8ステップ LoRA 使用 | 86% | ≈ 55s | ≈ 34s |
| 蒸留版 fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. ワークフローファイル
ComfyUI を更新後、テンプレートからワークフローファイルを見つけることができます。または、以下のワークフローを ComfyUI にドラッグして読み込んでください。

<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/image_qwen_image.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>公式版 JSON 形式ワークフローをダウンロード
蒸留版
2. モデルダウンロード
ComfyOrg リポジトリで見つけられるバージョン
- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- 蒸留版 (非公式、15ステップのみ)
すべてのモデルは Huggingface または 魔搭 で見つけることができます。
拡散モデル
Qwen_image_distill
LoRA
テキストエンコーダー
VAE
モデル保存場所
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ ├── qwen_image_fp8_e4m3fn.safetensors
│ │ └── qwen_image_distill_full_fp8_e4m3fn.safetensors ## 蒸留版
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-8steps-V1.0.safetensors ## 8ステップ高速 LoRA モデル
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors3. ステップバイステップでのワークフロー完成
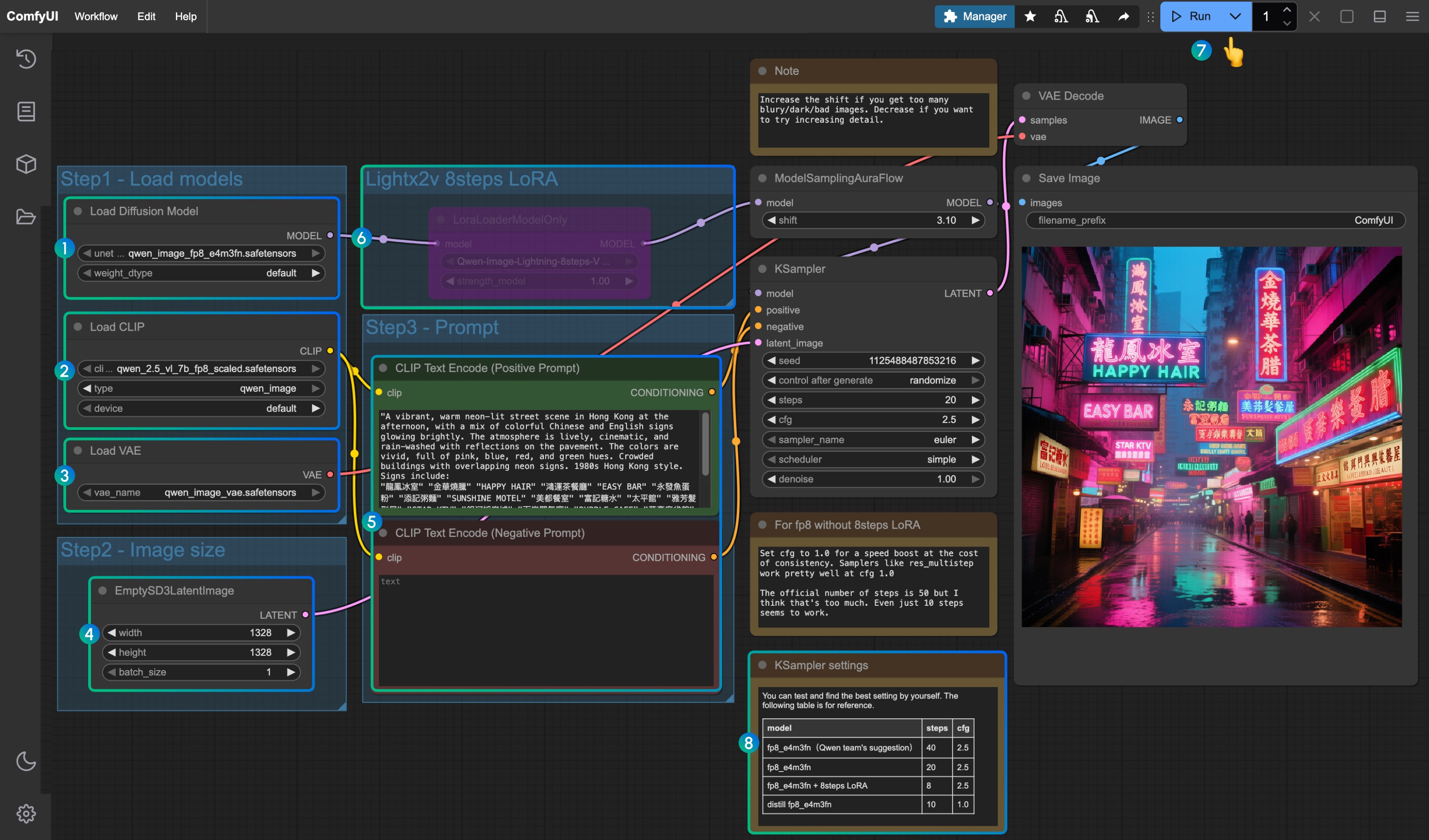
Load Diffusion Modelノードがqwen_image_fp8_e4m3fn.safetensorsを読み込んでいることを確認Load CLIPノードがqwen_2.5_vl_7b_fp8_scaled.safetensorsを読み込んでいることを確認Load VAEノードがqwen_image_vae.safetensorsを読み込んでいることを確認EmptySD3LatentImageノードで画像サイズが正しく設定されていることを確認CLIP Text Encoderノードにプロンプトを設定してください。現在のテストでは、少なくとも英語、中国語、韓国語、日本語、イタリア語等に対応していることを確認しています- lightx2v の 8ステップ高速 LoRA を有効にする場合、選択後に
Ctrl + Bでノードを有効化し、番号8の位置の設定パラメータに従って Ksampler の設定を変更してください Queueボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でワークフローを実行- モデルとワークフローのバージョンに対応する KSampler のパラメータ設定
Qwen-Image GGUF 版 ComfyUI ワークフロー
GGUF 版は低 VRAM ユーザーに優しく、特定の重みの場合、8GB 程度の VRAM で Qwen-Image を実行できます。
VRAM 使用量参考:
| ワークフロー | VRAM 使用量 | 初回生成 | 以降の生成 |
|---|---|---|---|
| qwen-image-Q4_K_S.gguf | 56% | ≈ 135s | ≈ 77s |
| 8steps LoRA 付き | 56% | ≈ 100s | ≈ 45s |
モデルアドレス:Qwen-Image-gguf
1. カスタムノードの更新またはインストール
GGUF 版を使用するには、ComfyUI-GGUF プラグインをインストールまたは更新する必要があります。
詳細はComfyUI カスタムノードのインストール方法を参照するか、Manager から検索してインストールしてください。
2. ワークフローダウンロード

3. モデルダウンロード
GGUF 版で使用されるモデルは拡散モデルのみが他と異なります。
https://huggingface.co/city96/Qwen-Image-gguf にアクセスして任意の重みをダウンロードしてください。通常、ファイルサイズが大きいほど品質が良く、より高い VRAM を要求します。本チュートリアルでは以下のバージョンを使用します:
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen-image-Q4_K_S.gguf # または選択した他のバージョン3. GGUFワークフローをステップバイステップで完成
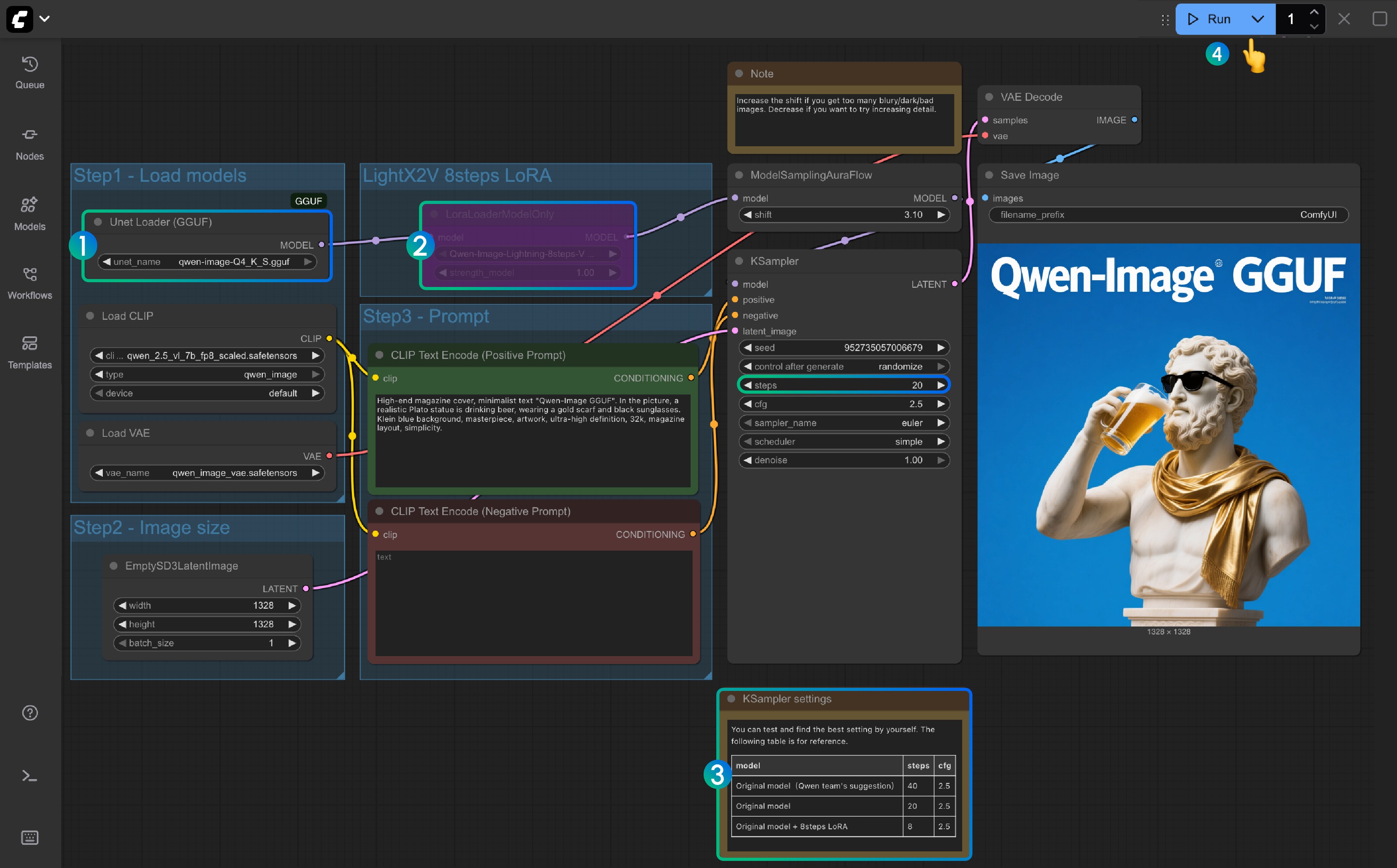
Unet Loader(GGUF)ノードがqwen-image-Q4_K_S.ggufまたはダウンロードした他のバージョンを読み込んでいることを確認- ComfyUI-GGUF がインストールされ、更新されていることを確認してください
LightX2V 8Steps LoRAはデフォルトでは有効になっておらず、選択後に Ctrl+B でノードを有効化できます- 8ステップ LoRA が有効でない場合、デフォルトのステップ数は 20 です。8ステップ LoRA を有効にする場合は 8 に設定してください
- こちらが対応するステップ数設定の参考です
Queueボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でワークフローを実行
Qwen-Image ナンチャク版ワークフロー
モデルアドレス:nunchaku-qwen-image カスタムノードアドレス:https://github.com/nunchaku-tech/ComfyUI-nunchaku
Qwen Image ControlNet
Qwen Image ControlNet DiffSynth-ControlNets Model Patches ワークフロー
このモデルは実際にはcontrolnetではなく、canny、depth、inpaintの3つの異なる制御モードをサポートするModel patchです。
オリジナルモデルアドレス:DiffSynth-Studio/Qwen-Image ControlNet Comfy Org リホストアドレス:Qwen-Image-DiffSynth-ControlNets/model_patches
1. ワークフローと入力画像
下の画像をダウンロードしてComfyUIにドラッグして対応するワークフローを読み込みます

下の画像を入力画像としてダウンロードしてください:

2. モデルリンク
他のモデルはQwen-Image基本ワークフローと一致します。以下のモデルをダウンロードしてComfyUI/models/model_patchesフォルダに保存してください:
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. ワークフロー使用説明
現在、diffsynthには3つのpatchモデルがあります:Canny、Depth、Inpaintモデルです。
ControlNet関連のワークフローを初めて使用する場合、制御に使用される画像は、モデルで使用・認識される前に、サポートされている画像形式に前処理する必要があることを理解する必要があります。

- Canny:処理されたcanny、線画の輪郭
- Depth:前処理された深度マップ、空間関係を表現
- Inpaint:再描画が必要な部分をマークするためにマスクを使用する必要があります
このpatchモデルは3つの異なるモデルに分かれているため、入力時に正しい前処理タイプを選択して、画像の正しい前処理を確保する必要があります。
CannyモデルControlNet使用説明
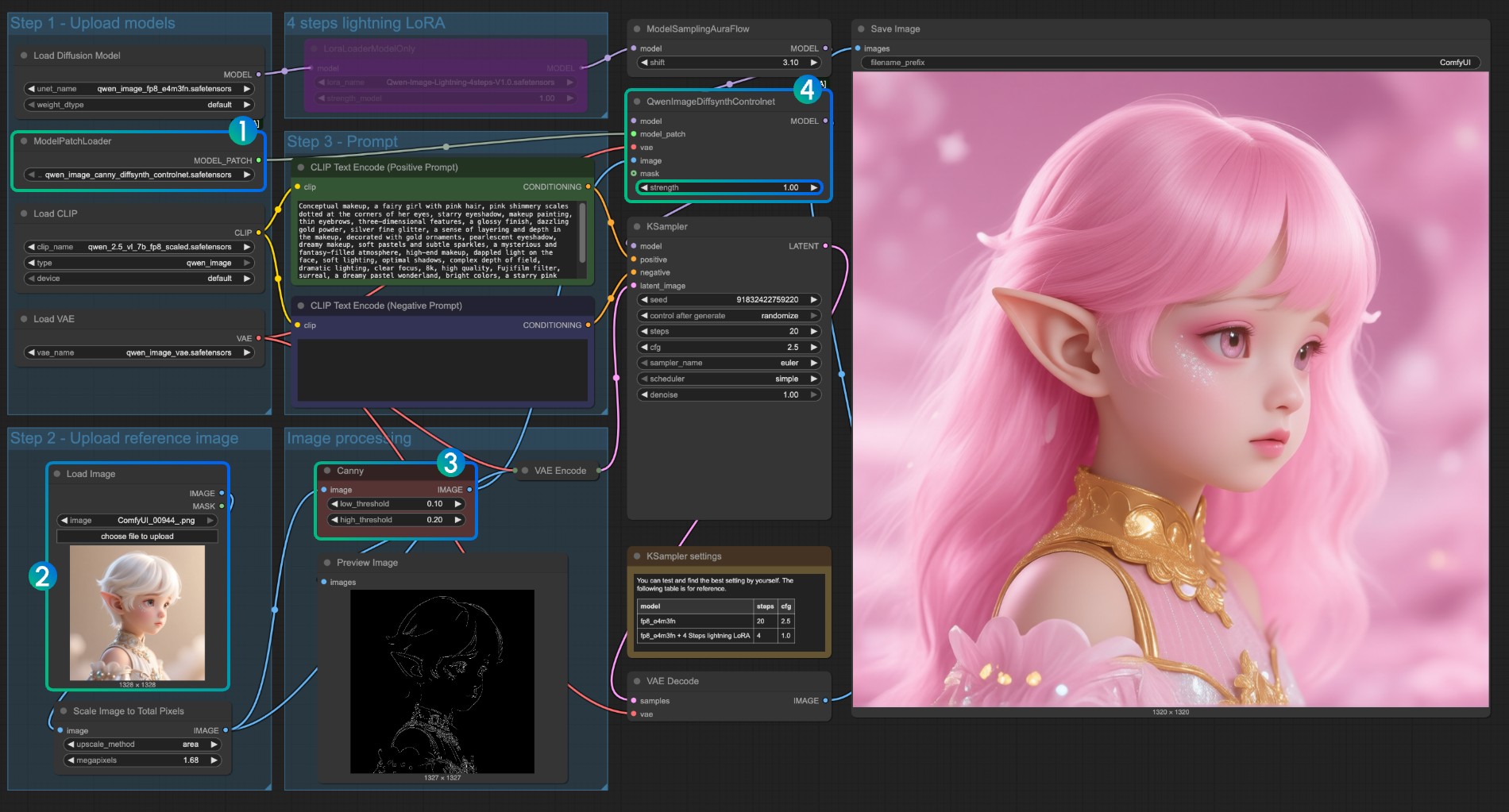
qwen_image_canny_diffsynth_controlnet.safetensorsが読み込まれていることを確認- 後続の処理のために入力画像をアップロード
- Cannyノードはネイティブの前処理ノードで、設定したパラメータに従って入力画像を前処理し、生成を制御します
- 必要に応じて、
QwenImageDiffsynthControlnetノードのstrengthパラメータを変更して線画制御の強度を制御できます Runボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でワークフローを実行
qwen_image_depth_diffsynth_controlnet.safetensorsを使用するには、画像を深度マップに前処理し、
image processing部分を置き換える必要があります。この使用方法については、このドキュメントのInstantX処理方法を参照してください。他の部分はCannyモデルの使用と同様です。
InpaintモデルControlNet使用説明
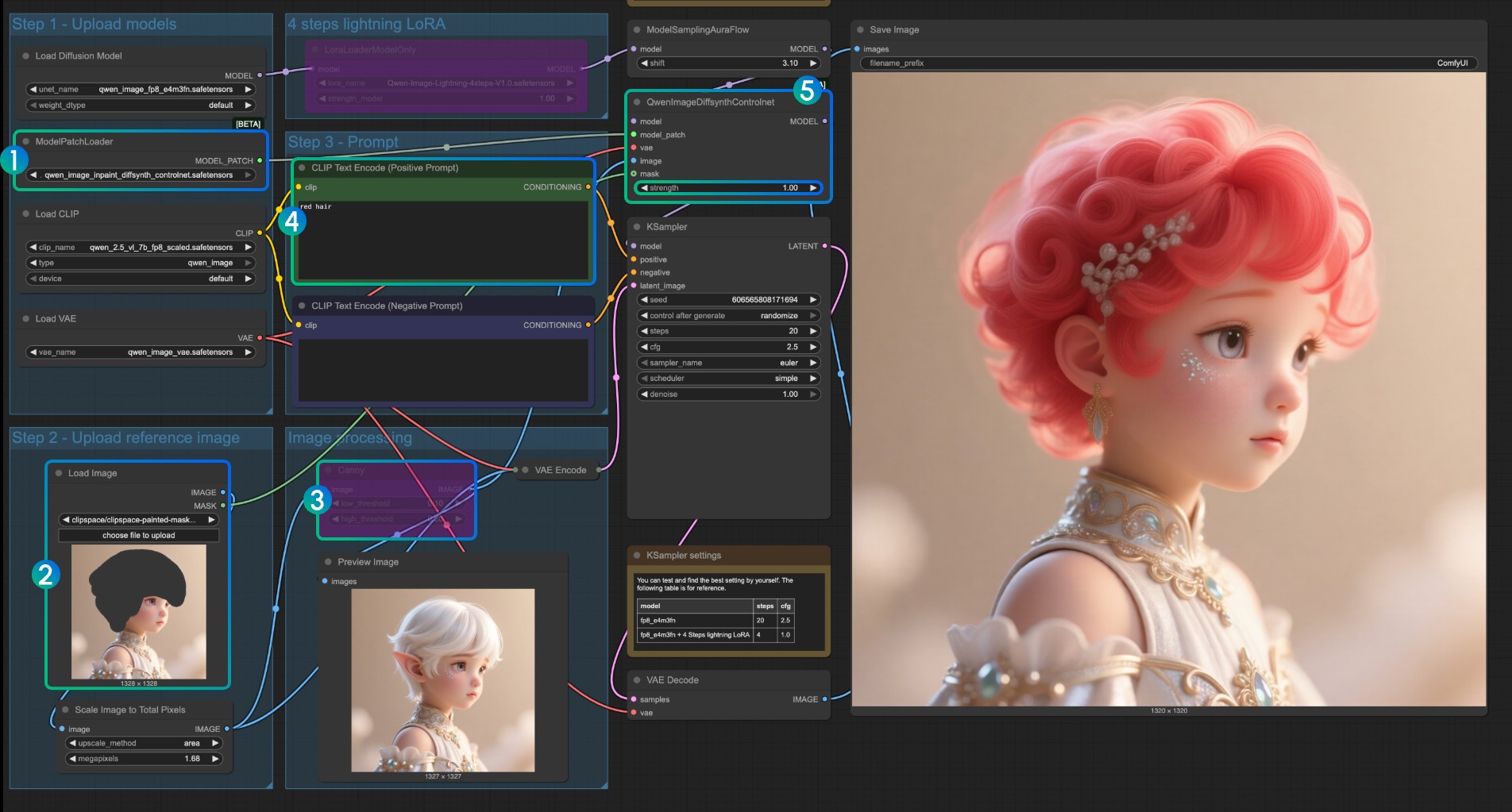
Inpaintモデルでは、マスクエディターを使用してマスクを描画し、入力制御条件として使用する必要があります。
ModelPatchLoaderがqwen_image_inpaint_diffsynth_controlnet.safetensorsモデルを読み込んでいることを確認- 画像をアップロードし、マスクエディターを使用してマスクを描画します。対応する
Load Imageノードのmask出力をQwenImageDiffsynthControlnetのmask入力に接続して、対応するマスクが読み込まれるようにする必要があります Ctrl-Bショートカットキーを使用して、元のワークフロー内のCannyをバイパスモードに設定し、対応するCannyノード処理が有効にならないようにしますCLIP Text Encoderで、マスクされた部分を変更したいスタイルを入力します- 必要に応じて、
QwenImageDiffsynthControlnetノードのstrengthパラメータを変更して、対応する制御強度を制御できます Runボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でワークフローを実行
Qwen Image Union ControlNet LoRA ワークフロー
オリジナルモデルアドレス:DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Comfy Org リホストアドレス:qwen_image_union_diffsynth_lora.safetensors:canny、depth、pose、lineart、softedge、normal、openposeをサポートする画像構造制御LoRA
1. ワークフローと入力画像
下の画像をダウンロードしてComfyUIにドラッグしてワークフローを読み込みます

下の画像を入力画像としてダウンロードしてください:

2. モデルリンク
以下のモデルをダウンロードしてください。これはLoRAモデルなので、ComfyUI/models/loras/フォルダに保存する必要があります:
- qwen_image_union_diffsynth_lora.safetensors:canny、depth、pose、lineart、softedge、normal、openposeをサポートする画像構造制御LoRA
3. ワークフロー説明
このモデルは、canny、depth、pose、lineart、softedge、normal、openposeなどの制御をサポートする統合制御LoRAです。多くのネイティブ画像前処理ノードが完全にサポートされていないため、comfyui_controlnet_auxのようなものを使用して他の画像前処理を完了する必要がある場合があります。
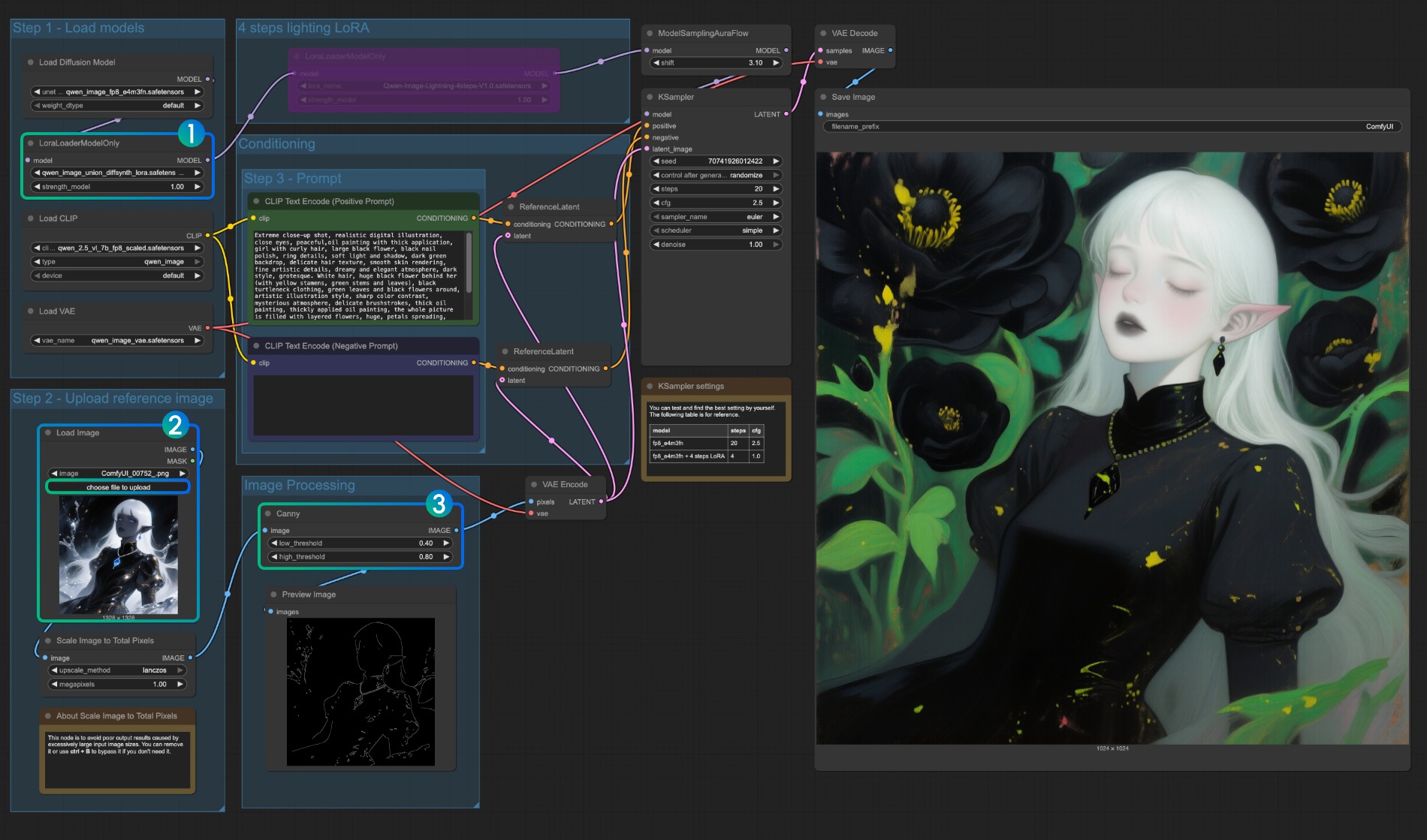
LoraLoaderModelOnlyがqwen_image_union_diffsynth_lora.safetensorsモデルを正しく読み込んでいることを確認- 入力画像をアップロード
- 必要に応じて、
Cannyノードのパラメータを調整できます。異なる入力画像は、より良い画像前処理結果を得るために異なるパラメータ設定を必要とするため、対応するパラメータ値を調整してより多くの/より少ない詳細を取得できます Runボタンをクリック、またはショートカットキーCtrl(cmd) + Enter(リターン)でワークフローを実行
他のタイプの制御についても、画像処理部分を置き換える必要があります。
コメント
GitHubでサインインしてディスカッションに参加しましょう。