ComfyUI unCLIPモデルの例
None。
unCLIPモデルは、SDモデルのバージョンで、テキストプロンプトに加えて画像のコンセプトを入力として受け取るように特別に調整されています。これらのモデルに付属するCLIPVisionを使用して画像がエンコードされ、そこから抽出されたコンセプトがサンプリング時にメインモデルに渡されます。
基本的に、プロンプトで画像を使用することができます。
ComfyUIでの使用方法は以下の通りです(これをComfyUIにドラッグしてワークフローを取得できます):
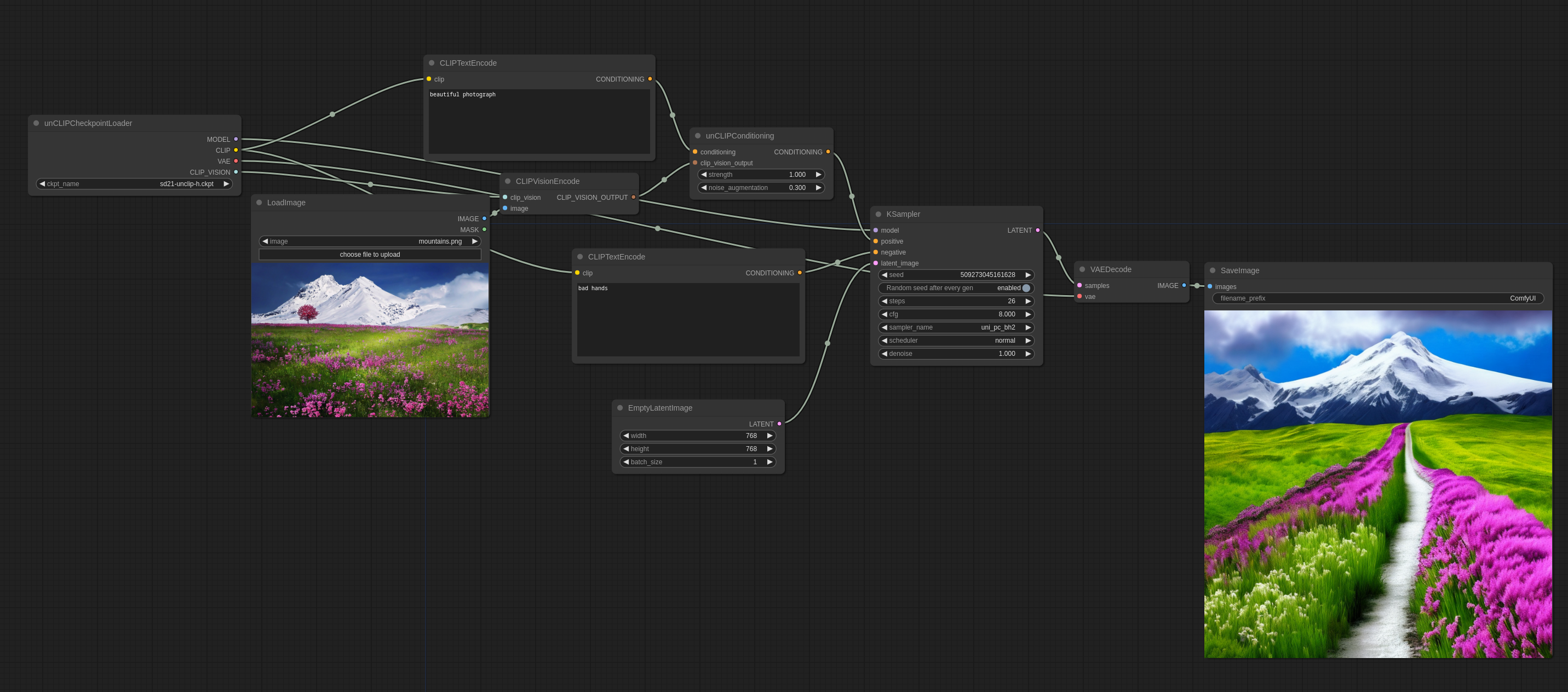
noise_augmentationは、モデルが画像のコンセプトにどれだけ忠実に従おうとするかを制御します。値が低いほど、コンセプトに従います。
strengthは、画像にどれだけ強く影響を与えるかを示します。
複数の画像を以下のように使用できます:
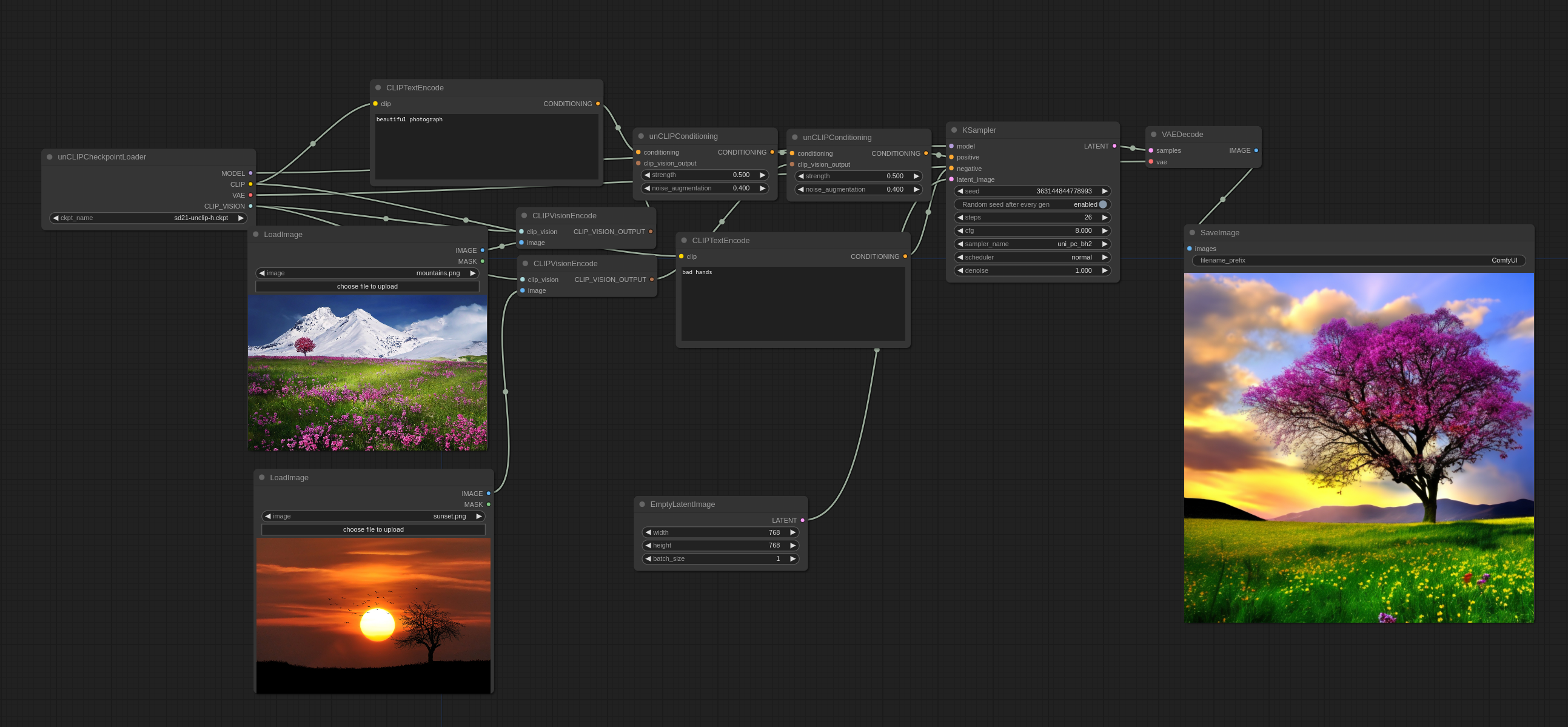
従来の意味で画像をブレンドするのではなく、両方の画像からいくつかのコンセプトを選び、整合性のある画像を作成することに気付くでしょう。
入力画像:


公式のunCLIPチェックポイントはこちらで見つけることができます。
既存の768-vチェックポイントからいくつかの巧妙なマージを行ったunCLIPチェックポイントはこちら(WD1.5 beta 2に基づく)とこちら(illuminati Diffusionに基づく)で見つけることができます。
より高度なワークフロー
unCLIPチェックポイントを使用する良い方法は、2パスワークフローの最初のパスで使用し、2番目のパスで1.xモデルに切り替えることです。以下の画像はこの方法で生成されました。(これをComfyUIにロードしてワークフローを取得できます):

コメント
GitHubでサインインしてディスカッションに参加しましょう。