Tencent Hunyuanチーム、人間の嗜好アライメント訓練効率を向上させるMixGRPOフレームワークをオープンソース化
Tencent Hunyuanチームが、GRPOにスライディングウィンドウ混合ODE-SDEサンプリングを統合した初のフレームワークMixGRPOをオープンソース公開。拡散モデルとフローモデルの人間嗜好アライメントで最大71%の訓練高速化を実現。
Tencent Hunyuanチームが正式にMixGRPOフレームワークをオープンソース公開しました!これは、GRPO(Generalized Reward-based Policy Optimization)にスライディングウィンドウ混合ODE-SDEサンプリングを統合した初のフレームワークで、AIモデルの人間嗜好アライメント効率を向上させるために特別に設計されています。
このフレームワークは、優れた性能を維持しながら訓練オーバーヘッドを大幅に削減します。MixGRPO-Flashバリエーションは最大71%の訓練高速化を実現し、DanceGRPOなど従来手法を上回る性能を示しています。
 異なるデノイジングステップ数最適化の性能比較。DanceGRPOの性能向上はより多くの最適化ステップに依存するが、MixGRPOはわずか4ステップで最適性能を実現
異なるデノイジングステップ数最適化の性能比較。DanceGRPOの性能向上はより多くの最適化ステップに依存するが、MixGRPOはわずか4ステップで最適性能を実現
MixGRPOフレームワークの特徴
核となる技術革新
- スライディングウィンドウ混合サンプリング: GRPOにスライディングウィンドウ混合ODE-SDEサンプリングを統合した初のフレームワーク
- 大幅な効率向上: MixGRPO-Flashは最大71%の訓練高速化を実現
- 高次ソルバーサポート: さらなる加速のための高次ODEソルバーをサポート
- 汎用互換性: 拡散モデルとフローモデルの両方に適用可能
 MixGRPOの技術アーキテクチャ図。スライディングウィンドウメカニズムの動作原理を示す
MixGRPOの技術アーキテクチャ図。スライディングウィンドウメカニズムの動作原理を示す
性能の優位性
- 訓練オーバーヘッドの大幅削減: 従来手法と比較して計算リソース消費を大幅に削減
- 従来手法を上回る性能: DanceGRPOなど従来手法を効果と効率の両面で上回る
- 高速収束: わずかな反復ステップでモデルの潜在能力を実現
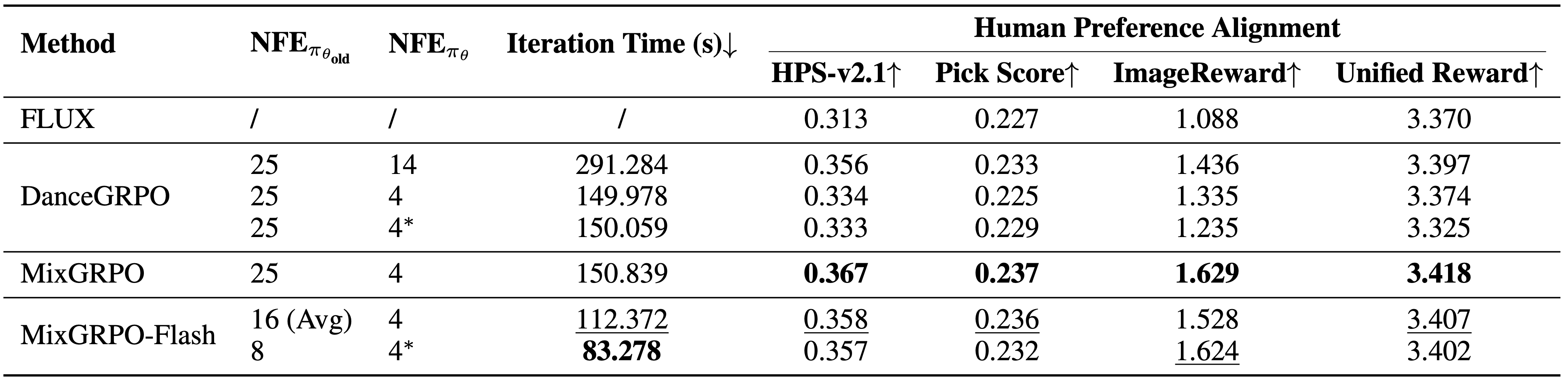 オーバーヘッドと性能の比較結果。MixGRPOは複数指標で最高性能を達成し、MixGRPO-FlashはDanceGRPOを上回りながらサンプリング時間を大幅に短縮
オーバーヘッドと性能の比較結果。MixGRPOは複数指標で最高性能を達成し、MixGRPO-FlashはDanceGRPOを上回りながらサンプリング時間を大幅に短縮
技術適用シナリオ
MixGRPOフレームワークは主に人間嗜好アライメントタスクに使用されます。これはAI分野の重要な研究方向です。このフレームワークを通じて、研究者は以下が可能になります:
- 人間の嗜好により良く合致する画像生成モデルをより効率的に訓練
- 大規模モデル訓練の計算コストを削減
- モデル品質を維持しながら実験反復を加速
この技術は、AI生成コンテンツの品質とユーザー満足度の向上、特に画像生成やコンテンツ作成アプリケーションにおいて重要な意義を持ちます。
実験結果
 定性比較結果。MixGRPOはセマンティクスと美学の両面で優れた性能を実現
定性比較結果。MixGRPOはセマンティクスと美学の両面で優れた性能を実現
 異なる訓練時サンプリングステップでの定性比較。MixGRPOの性能はオーバーヘッド削減に伴って大幅に低下することはない
異なる訓練時サンプリングステップでの定性比較。MixGRPOの性能はオーバーヘッド削減に伴って大幅に低下することはない
 異なる戦略でサンプリングされた画像のt-SNE可視化。デノイジングプロセスの初期段階でSDEサンプリングを使用することで、より離散的なデータ分布が得られる
異なる戦略でサンプリングされた画像のt-SNE可視化。デノイジングプロセスの初期段階でSDEサンプリングを使用することで、より離散的なデータ分布が得られる
オープンソースリソース
MixGRPOフレームワークは現在完全にオープンソース化されています。研究者と開発者は以下のチャンネルから関連リソースにアクセスできます:
関連リンク
- プロジェクトページ: https://tulvgengenr.github.io/MixGRPO-Project-Page/
- コードリポジトリ: https://github.com/Tencent-Hunyuan/MixGRPO
- 研究論文: https://arxiv.org/abs/2507.21802
MixGRPOのオープンソース化により、AI研究コミュニティに強力なツールサポートが提供され、人間嗜好アライメント技術のさらなる発展と応用が促進されます。
コメント
GitHubでサインインしてディスカッションに参加しましょう。