ComfyUI サーバー構成の説明
現在のバージョン: ComfyUI Desktop v0.4.5
サーバー構成は ComfyUI Desktop のサーバー側(ホスト側)で行われ、ComfyUI の LAN アクセス設定、各種精度設定、キャッシュ設定などを構成できます。LAN の他のデバイスからアクセスする場合、これらの設定を変更することはできません。
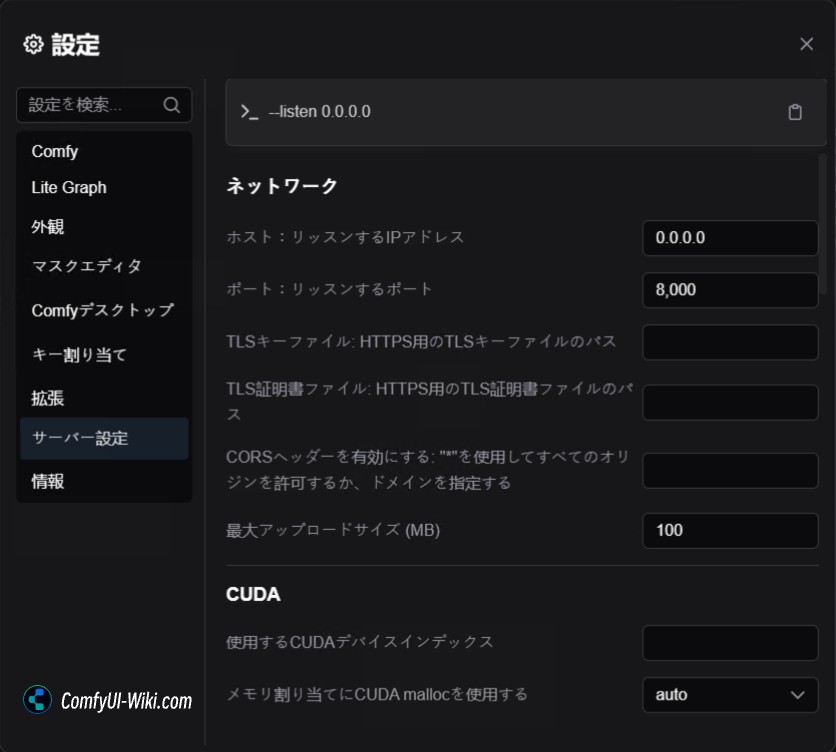
ネットワーク
ComfyUI はネットワーク経由のサーバーアクセスをブロックしていませんが、デスクトップアプリをサーバーとして実行することは想定されていません。Electron はこのような用途には適していません。
-
ホスト (listen)
- 機能: サーバーがリッスンする IP アドレスの設定
- デフォルト値:
127.0.0.1(ローカルホストのみアクセス可能)
-
ポート (port)
- 機能: サーバーがリッスンするポート番号の設定
- デフォルト値:
8000(ソフトウェアの競合がある場合のみ変更が必要)
-
TLS キーファイル (tls-keyfile) および TLS 証明書ファイル (tls-certfile)
- 機能: HTTPS セキュア接続の設定用。HTTPS が不要な場合は無視可能
-
CORS ヘッダーを有効にする (enable-cors-header)
- 機能: 他のウェブサイトからのサーバーアクセスを許可。”*“を使用してすべてのオリジンを許可
-
最大アップロードサイズ (max-upload-size)
- 機能: ファイルアップロードの最大サイズ制限 (MB 単位)
- デフォルト値:
100
CUDA 設定
-
CUDA デバイス (cuda-device)
- 機能: 使用する GPU の選択
- オプション:
- 0: 最初の GPU
- 1: 2番目の GPU (存在する場合)
- null: 自動選択
- 推奨: 単一 GPU ユーザーはデフォルト値を維持
-
CUDA malloc を使用 (cuda-malloc)
- 機能: GPU メモリ割り当て方式の決定
- オプション:
オプション 説明 使用ケース 自動 システムが最適な方法を決定 初心者向け推奨 有効 積極的なメモリ割り当てを使用 VRAM がより必要な場合 無効 保守的なメモリ割り当てを使用 VRAM の問題が発生した場合
推論
-
グローバル浮動小数点精度 (global-precision)
- 機能: 全体の演算精度の制御
- オプション:
オプション 説明 使用ケース AUTO 最適な精度を自動選択 ほとんどの場合に適切 FP32 最高精度モード 最高の画質が必要な場合 FP16 低精度、より高速 高速生成が必要な場合
-
UNET 精度 (unet-precision)
- 機能: AI 画像生成の中核部分の精度制御
- オプション:
オプション 説明 使用ケース AUTO 自動選択、初心者向け推奨 ほとんどの場合に適切 FP32 最高品質、速度は遅い 最高品質が必要な場合 FP16 バランスモード、中程度の速度と品質 日常的な使用 BF16 特別なバランスモード 特定の新しい GPU 向け
-
VAE 精度 (vae-precision)
- 機能: 最終画像の詳細処理の制御
- オプション:
オプション 説明 使用ケース AUTO 適切な精度を自動選択 初心者向け推奨 FP16 高速だが詳細は少なめ 高速生成が必要な場合 FP32 最高品質、速度は遅い 最高品質が必要な場合 BF16 FP16 と FP32 の中間 特定の新しい GPU 向け
-
CPU で VAE を実行 (cpu-vae)
- 機能: CPU が最終画像処理を実行
- 使用ケース:
- GPU メモリが不足している場合
- 非常に大きな画像を処理する場合
- GPU 性能が不足している場合
-
テキストエンコーダー精度 (text-encoder-precision)
- 機能: AI のテキスト理解精度の制御
- オプション:
オプション 説明 使用ケース AUTO 最適な精度を自動選択 初心者向け推奨 FP32 最も正確な理解、速度は遅い 正確なプロンプト解釈が必要な場合 FP16 高速な理解、若干の偏差の可能性 高速な処理が必要な場合 BF16 両者のバランス 特定の GPU 最適化用
メモリ
-
チャネルを最後に強制するメモリ形式 (force-channels-last)
- 機能: メモリ内の画像データ配列方式の変更
- 推奨: 影響を理解できない場合はデフォルト値を維持
-
DirectML デバイス (directml)
- 機能: DirectML デバイスの選択
- 使用ケース: AMD GPU ユーザー向け
-
IPEX 最適化を無効にする (disable-ipex-optimize)
- 機能: IPEX 最適化の無効化
- デフォルト値:
false
プレビュー設定
-
プレビュー方法 (preview-method)
- 機能: 生成過程のプレビュー方式の制御
- オプション:
オプション 説明 使用ケース NoPreviews プレビューなし 最高速度が必要な場合 Latent ぼやけた生成過程を表示 進行状況の確認時 Taesd より鮮明な生成過程を表示 明確な進行状況が必要な場合
-
プレビュー画像のサイズ (preview-size)
- 機能: プレビューウィンドウのサイズ設定
- 推奨値:
- 通常使用: 512
- 性能不足時: 256
- 性能十分時: より大きく設定可能
キャッシュ
-
クラシックキャッシュシステムを使用 (cache-classic)
- 機能: 従来のキャッシュ管理方式を使用
- 使用ケース:
- システムメモリが十分な場合
- 安定した性能が必要な場合
-
LRU キャッシングを使用 (cache-lru)
- 機能: 最近使用されたデータのキャッシュ量を設定
- 推奨値:
- 8GB RAM: 2-3
- 16GB RAM: 4-6
- 32GB+ RAM: 8-12
アテンション設定
-
クロスアテンションメソッド (cross-attention-method)
- 機能: AI のテキスト理解と画像変換方式の制御
- オプション:
オプション 説明 使用ケース auto 最適な方法を自動選択 初心者向け推奨 split VRAM 節約、速度は遅い VRAM が不足している場合 quad 従来の方式、安定的 安定した効果が必要な場合 pytorch PyTorch ネイティブ方式 互換性の問題がある場合
-
アテンションのアップキャストを強制 (force-attention-upcast)
- 機能: アテンションメカニズムでより高い精度を強制使用
- 使用ケース: 画像の詳細が理想的でない場合
-
アテンションのアップキャストを防ぐ (dont-upcast-attention)
- 機能: アテンションメカニズムの高精度使用を防止
- 使用ケース: 高速な生成速度が必要な場合
VRAM 管理
-
VRAM 管理モード (vram-management)
- 機能: GPU メモリの使用方式の制御
- オプション:
オプション 説明 使用ケース Auto 自動管理 初心者向け推奨 Full すべての利用可能な空間を使用 VRAM が十分な場合 Low 空間を節約 VRAM が不足している場合
-
予約済み VRAM (reserve-vram)
- 機能: 他のプログラム用の GPU メモリ予約
- 推奨値: 他のプログラムの必要に応じて 2-4GB
一般
-
xFormers 最適化を無効にする (disable-xformers)
- 機能: xFormers 加速化最適化の無効化
- 推奨: 問題がない限り有効を維持
-
デフォルトハッシュ関数 (default-hashing-function)
- 機能: モデルファイルの整合性チェック方法の選択
- オプション:
オプション 説明 sha256 最も一般的で安全なチェック方法
-
決定論的アルゴリズムを使用
- 機能: より安定的だが遅いランダムアルゴリズムを使用
- 推奨: 通常は有効化不要
-
未テストの最適化を有効にする
- 機能: テストされていない最適化方法を使用
- 推奨: 安定した効果を求める場合は非推奨
-
サーバー出力をコンソールに表示しない
- 機能: バックエンド実行ログを表示しない
- 推奨: 問題解決時は無効化
-
プロンプトメタデータを保存しない
- 機能: 生成された画像ファイルにプロンプト情報を保存しない
- 使用ケース: プロンプトを非公開にしたい場合
-
すべてのカスタムノードの読み込みを無効にする
- 機能: すべてのカスタム機能モジュールの読み込みを防止
- 使用ケース: 最も基本的な安定した体験が必要な場合
-
ログの冗長性レベル (log-level)
- 機能: システムログの詳細レベルを設定
- オプション:
オプション 説明 使用ケース DEBUG すべての詳細情報を表示 開発者またはトラブルシューティング時 INFO 一般情報を表示 日常的な使用に推奨 WARNING 警告とエラーのみ表示 問題の通知のみ必要な場合 ERROR エラーのみ表示 深刻な問題のみ関心がある場合 CRITICAL 致命的なエラーのみ表示 最も深刻な問題のみ必要な場合
ディレクトリ設定
-
入力ディレクトリ (input-directory)
- 機能: 入力ファイル用のディレクトリ設定
- デフォルト値: 空文字列
-
出力ディレクトリ (output-directory)
- 機能: 出力ファイル用のディレクトリ設定
- デフォルト値: 空文字列