HunyuanVideo 图生视频GGUF、FP8及ComfyUI Native 工作流完整指南及示例
详细介绍如何在 ComfyUI 中使用腾讯混元 HunyuanVideo 模型进行图生视频生成的完整教程,包括环境配置、模型安装和工作流使用说明
腾讯于2025年3月6日正式发布了 HunyuanVideo 图生视频模型,目前模型已开源,你可以在 HunyuanVideo-I2V 找到模型。
下面是 HunyuanVideo 的整体架构图
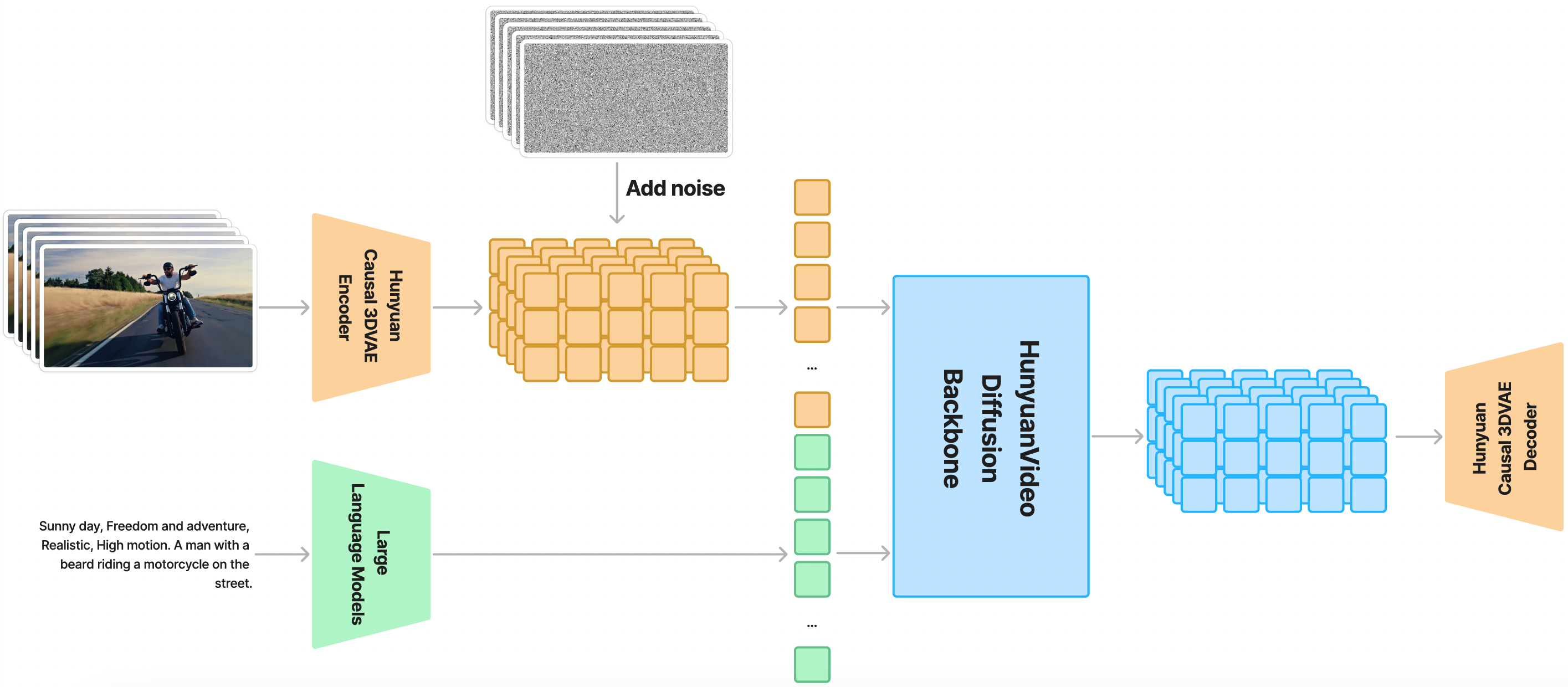
目前 ComfyUI 官方已原生支持 HunyuanVideo-I2V 模型,社区作者 kijai 和 city96 的自定义节点目前已更新支持 HunyuanVideo-I2V 模型。
目前对应模型除了腾讯官方之外,下面是目前 ComfyUI Wiki 搜索整理到的对应版本
- ComfyUI 官方重新打包版本,无需插件:Comfy-Org/HunyuanVideo_repackaged
- Kijai 版本,需安装ComfyUI-HunyuanVideoWrapper :Kijai/HunyuanVideo_comfy
- city96 打包版本,需安装ComfyUI-GGUF:city96/HunyuanVideo-I2V-gguf
在本文里,我们将会基于这些版本分别提供对应的完整模型安装和工作流示例使用说明。
本文主要讲解图生视频工作流,如果你想要了解腾讯混元文生视频工作流,可以参考腾讯混元文生视频工作流指南及示例
Comfy 官方 HunyuanVideo I2V工作流
相应工作流来自 ComfyUI 官方文档
请在开始本教程前请参考如何更新 ComfyUI部分更新你的 ComfyUI 到最新版本,防止出现 Comfy_Core 针对 HunyuanVideo 的相关节点缺失
- HunyuanImageToVideo
- TextEncodeHunyuanVideo_ImageToVideo
1. HunyuanVideo I2V 工作流文件
下载下面的工作流文件,然后拖入 ComfyUI, 或者使用菜单 Workflows -> Open(ctrl+o) 打开以加载工作流

JSON 格式工作流下载
2. HunyuanVideo I2V 相关模型下载
以下模型均来自Comfy-Org/HunyuanVideo_repackaged,请下载对应的模型:
- llava_llama3_vision.safetensors
- clip_l.safetensors
- llava_llama3_fp16.safetensors
- llava_llama3_fp8_scaled.safetensors
- hunyuan_video_vae_bf16.safetensors
- hunyuan_video_image_to_video_720p_bf16.safetensors
下载后请按照下面的文件组织,将他们保存到 ComfyUI/models 的对应文件夹下
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_image_to_video_720p_bf16.safetensors3. 输入图片
下载下面的图片作为输入图片

按步骤完成对应 HunyuanVideo I2V 工作流节点的检查
参照图片完成对应节点内容的检查,确保工作流正常运行
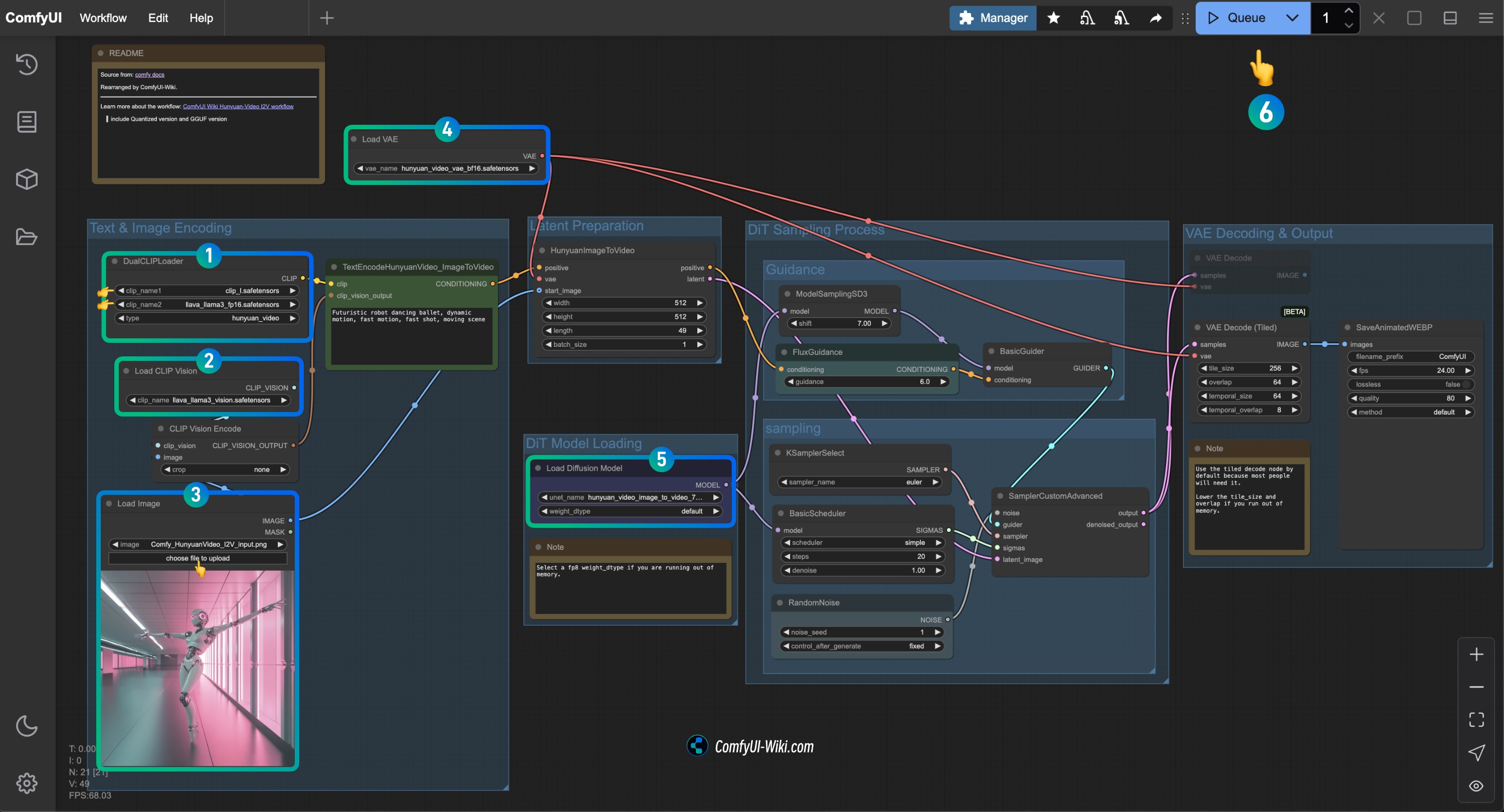
- 检查
DualCLIPLoader节点:
- 确保
clip_name1: clip_l.safetensors 正确加载 - 确保
clip_name2: llava_llama3_vision.safetensors 正确加载
- 检查
Load CLIP Vision节点: 确保 llava_llama3_vision.safetensors 正确加载 - 在
Load Image节点中,上传之前提供的输入图片 - 检查
Load VAE节点: 确保 hunyuan_video_vae_bf16.safetensors 正确加载 - 检查
Load Diffusion Model节点: 确保 hunyuan_video_image_to_video_720p_bf16.safetensors 正确加载
- 如果运行过程中遇到
running out of memory.错误,可以试着把weight_dtype设置为fp8类型的
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Kijai HunyuanVideoWrapper 版本
1. 自定义节点安装
你需要安装以下自定义节点:
如果你不知道如何安装自定义节点,请参考ComfyUI 自定义节点安装指南
2. 模型下载
下载后请按照下面的文件组织,将他们保存到 ComfyUI/models 的对应文件夹下
ComfyUI/
├── models/
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_I2V_fp8_e4m3fn.safetensors3. HunyuanVideo I2V 工作流文件
按步骤完成对应 HunyuanVideo I2V 工作流节点的检查 (Kijai)
参照图片完成对应节点内容的检查,确保工作流正常运行
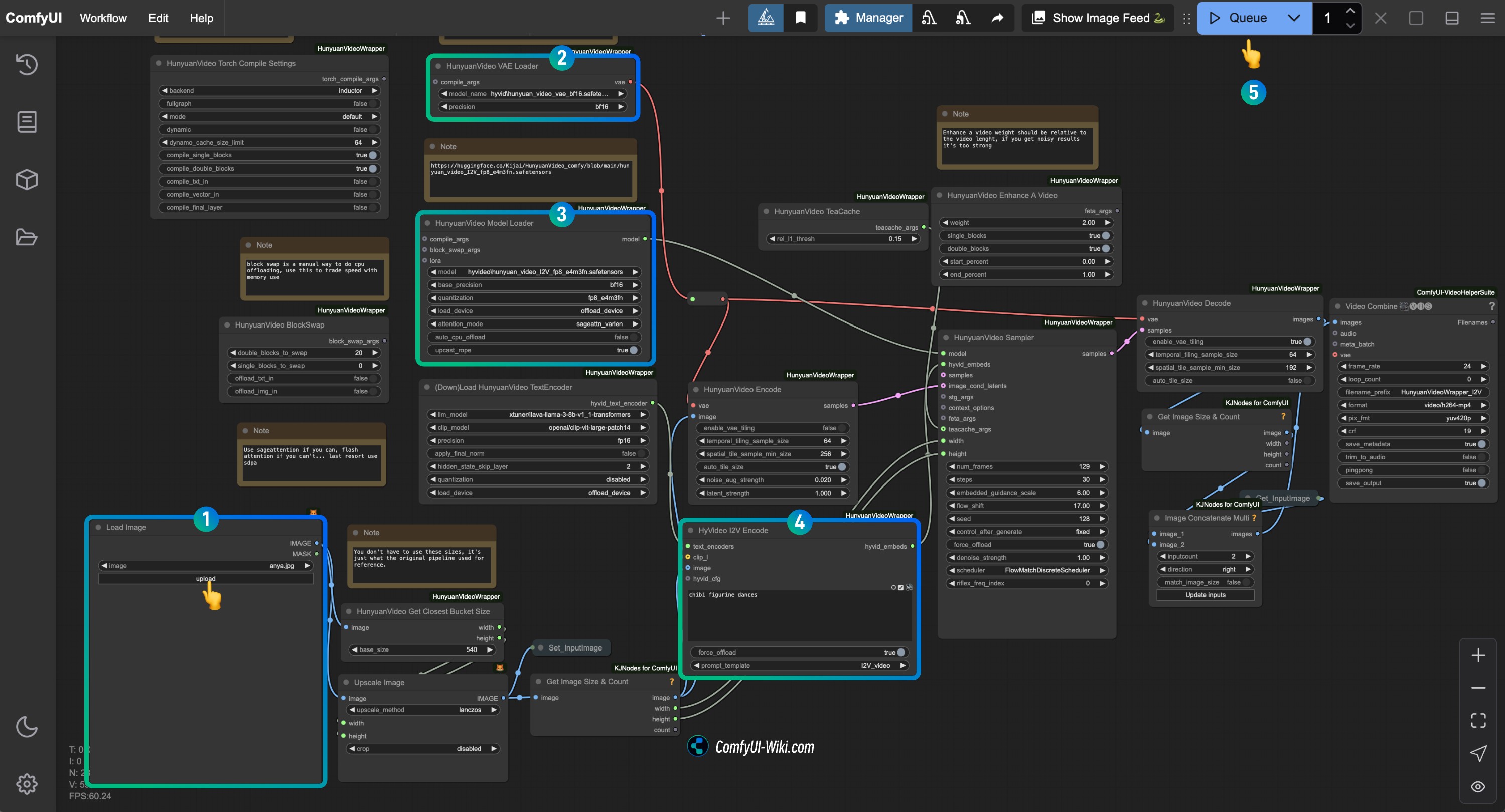
- 在
Load Image节点中,上传你要用于图生视频的图片 - 在
HunyuanVideo VAE Loader节点中,确保hunyuan_video_vae_bf16.safetensors正确加载 - 在
HunyuanVideo Model Loader节点中,确保hunyuan_video_I2V_fp8_e4m3fn.safetensors正确加载 - 修改
HyVideo I2V Encode节点中的 prompt 文本,输入你想要生成的视频描述 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
city96 GGUF 版本
1. 自定义节点安装 (GGUF)
你需要安装以下自定义节点:
如果你不知道如何安装自定义节点,请参考ComfyUI 自定义节点安装指南
2. 模型下载 (GGUF)
这部分的模型除了 HunyuanVideo 模型之外,基本和 Comfy 官方版本一致, 对应模型请参考本文 Comfy 官方版本部分进行手动下载
你需要访问 city96/HunyuanVideo-I2V-gguf 下载你需要版本的模型,并保存对应的 gguf 模型文件到 ComfyUI/models 文件夹下
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── unet/
│ └── hunyuan-video-i2v-720p-Q4_K_M.gguf // 取决于你下载到的版本3. HunyuanVideo I2V 工作流文件 (GGUF)
按步骤完成对应 HunyuanVideo I2V 工作流节点的检查 (GGUF)
参照图片完成对应节点内容的检查,确保工作流正常运行
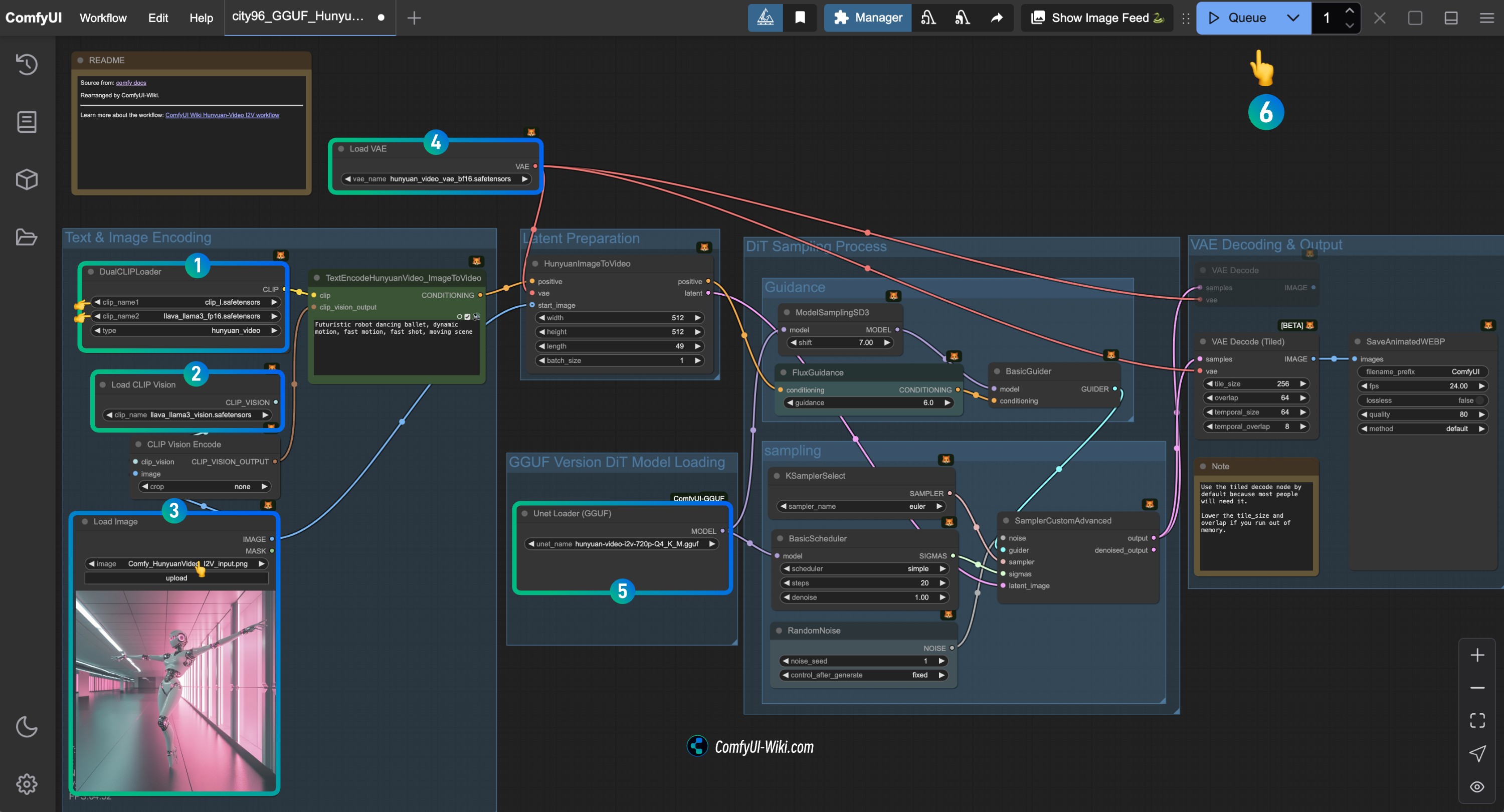
- 检查
DualCLIPLoader节点:
- 确保
clip_name1: clip_l.safetensors 正确加载 - 确保
clip_name2: llava_llama3_vision.safetensors 正确加载
- 检查
Load CLIP Vision节点: 确保 llava_llama3_vision.safetensors 正确加载 - 在
Load Image节点中,上传之前提供的输入图片 - 检查
Load VAE节点: 确保 hunyuan_video_vae_bf16.safetensors 正确加载 - 检查
Load Diffusion Model** 节点: 确保对应的 HunyuanVideo GGUF 模型 正确加载** - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
评论
使用 GitHub 登录后即可参与讨论。