Wan2.2-S2V 音频驱动视频生成 ComfyUI 工作流和教程
使用 Wan2.2-S2V 在 ComfyUI 中创建自然口型同步的虚拟数字人视频。涵盖模型设置、S2V 管道和工作流配置。
Wan2.2-S2V 代表了 AI 视频生成技术的重大进步,能够从静态图像和音频输入创建动态视频内容。这一创新模型擅长生成具有自然唇同步的同步视频,对于处理对话场景、音乐表演和角色驱动叙事的内容创作者特别有价值。
模型亮点
- 音频驱动视频生成:将静态图像和音频转换为具有自然唇同步和表情的同步视频
- 电影级质量:生成具有真实面部表情、身体动作和镜头语言的电影质量视频
- 分钟级生成:支持单次生成长达分钟级的长格式视频创作
- 多格式支持:适用于真人、卡通、动物、数字人,并支持肖像、半身和全身格式
- 增强的动作控制:通过 AdaIN 和 CrossAttention 控制机制从文本指令生成动作和环境
- 高性能指标:实现 FID 15.66、CSIM 0.677 和 SSIM 0.734,提供卓越的视频质量和身份一致性
Wan2.2 S2V ComfyUI 原生工作流
1. 下载工作流文件
下载以下工作流文件并将其拖入 ComfyUI 以加载工作流。
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/wan2.2_s2v/wan2.2-s2v.mp4"
下载以下图像和音频作为输入:

2. 模型链接
您可以在 我们的仓库 中找到这些模型
diffusion_models
audio_encoders
vae
text_encoders
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_s2v_14B_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 audio_encoders/ # 如果找不到此文件夹请创建一个
│ │ └─── wav2vec2_large_english_fp16.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors3. 工作流说明
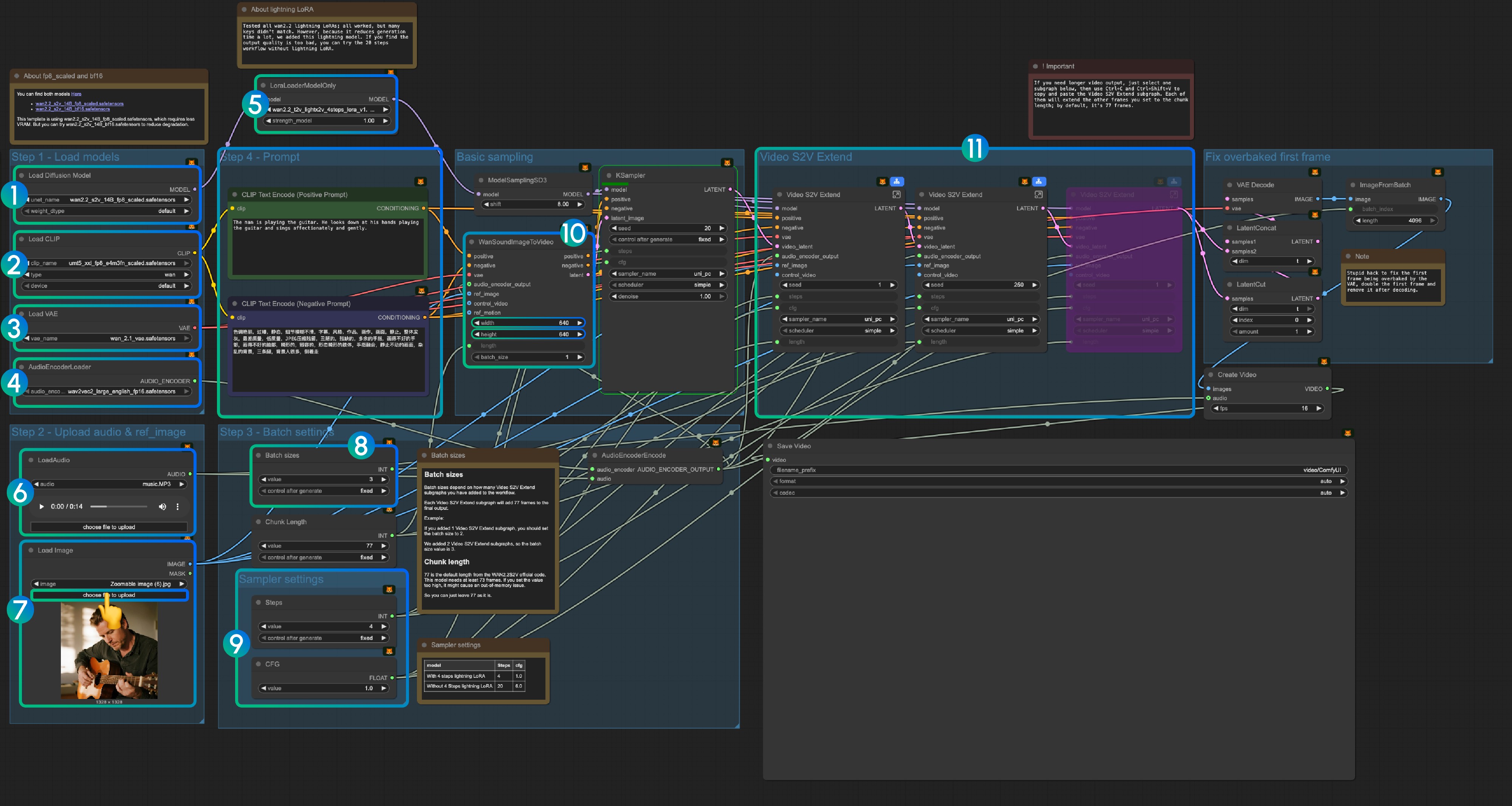
3.1 Lightning LoRA(可选,用于加速)
Lightning LoRA 将生成时间从 20 步减少到 4 步,但可能影响质量。用于快速预览,最终输出时禁用。
3.1.1 音频预处理提示
人声分离以获得更好效果:由于 ComfyUI 核心不包含人声分离节点,我们建议在处理前使用外部工具将人声与背景音乐分离。这对于对话和唇同步生成尤为重要,因为干净的人声轨道比混合了背景音乐或噪音的音频能产生明显更好的结果。
3.2 关于 fp8_scaled 和 bf16 模型
您可以在此处找到两个模型 here:
模板使用 wan2.2_s2v_14B_fp8_scaled.safetensors 以降低 VRAM 使用。尝试 wan2.2_s2v_14B_bf16.safetensors 以获得更好质量。
3.3 逐步操作说明
步骤 1: 加载模型
- 加载扩散模型:加载
wan2.2_s2v_14B_fp8_scaled.safetensors或wan2.2_s2v_14B_bf16.safetensors- 工作流使用
wan2.2_s2v_14B_fp8_scaled.safetensors以降低 VRAM 需求 - 使用
wan2.2_s2v_14B_bf16.safetensors以获得更好质量的输出
- 工作流使用
- 加载 CLIP:加载
umt5_xxl_fp8_e4m3fn_scaled.safetensors - 加载 VAE:加载
wan_2.1_vae.safetensors - AudioEncoderLoader:加载
wav2vec2_large_english_fp16.safetensors - LoraLoaderModelOnly:加载
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)- 此 LoRA 可减少生成时间但可能影响质量
- 如果输出质量不足请禁用
- LoadAudio:上传提供的音频文件或您自己的音频
- Load Image:上传参考图像
- 批处理大小:根据 Video S2V Extend 子图节点数量设置
- 每个 Video S2V Extend 子图添加 77 帧到输出
- 示例:2 个 Video S2V Extend 子图 = 批处理大小 3
- 块长度:保持默认值 77
- 采样器设置:根据 Lightning LoRA 使用情况选择
- 使用 4 步 Lightning LoRA:steps: 4, cfg: 1.0
- 不使用 Lightning LoRA:steps: 20, cfg: 6.0
- 尺寸设置:设置输出视频尺寸
- Video S2V Extend:视频扩展子图节点
- 每个扩展生成 77 / 16 = 4.8125 秒视频
- 计算所需节点:音频长度(秒)× 16 ÷ 77
- 示例:14 秒音频 = 224 帧 ÷ 77 = 3 个扩展节点
- 使用 Ctrl-Enter 或点击运行按钮执行工作流
相关链接
- Wan2.2 S2V 代码:GitHub
- Wan2.2 S2V 模型:Hugging Face
评论
使用 GitHub 登录后即可参与讨论。