Wan2.2 ComfyUI 工作流完整使用指南,官方+社区版本(Kijai, GGUF)工作流全攻略
最全面的Wan2.2视频 ComfyUI 使用教程:包含官方原生版本、Kijai WanVideoWrapper、GGUF量化版、Lightx2v快速生成等多个版本的工作流
教程总览
本教程将全面介绍 Wan2.2 视频生成模型在 ComfyUI 中的各种实现方式和使用方法。Wan2.2 是阿里云推出的新一代多模态生成模型,采用创新的 MoE(Mixture of Experts)架构,具备影视级美学控制、大规模复杂运动生成和精准语义遵循等核心特性。
本教程涵盖的版本和内容
已完成的版本:
- ✅ ComfyUI 官方原生版本 - 由 ComfyOrg 官方提供的完整工作流
- ✅ Wan2.2 5B 混合版本 - 支持文生视频和图生视频的轻量级模型
- ✅ Wan2.2 14B 文生视频版本 - 高质量文本到视频生成
- ✅ Wan2.2 14B 图生视频版本 - 静态图像转动态视频
- ✅ Wan2.2 14B 首尾帧视频生成 - 基于起始和结束帧的视频生成
正在准备中的版本:
- 🔄 Kijai WanVideoWrapper 版本
- 🔄 GGUF 量化版本 - 适用于低配置设备的优化版本
- 🔄 Lightx2v 4steps LoRA - 快速生成优化方案
关于 Wan2.2 视频生成模型
Wan2.2 采用创新的 MoE(Mixture of Experts)架构,由高噪专家模型和低噪专家模型组成,能够根据去噪时间步进行专家模型划分,从而生成更高质量的视频内容。
核心优势:
- 影视级美学控制:专业镜头语言,支持光影、色彩、构图等多维度视觉控制
- 大规模复杂运动:流畅还原各类复杂运动,强化运动可控性和自然度
- 精准语义遵循:复杂场景理解,多对象生成,更好还原创意意图
- 高效压缩技术:5B版本高压缩比VAE,显存优化,支持混合训练
Wan2.2 系列模型基于 Apache2.0 开源协议,支持商业使用。Apache2.0 许可证允许您自由使用、修改和分发这些模型,包括商业用途,只需保留原始版权声明和许可证文本。
Wan2.2 开源模型版本概览
| 模型类型 | 模型名称 | 参数量 | 主要功能 | 模型仓库 |
|---|---|---|---|---|
| 混合模型 | Wan2.2-TI2V-5B | 5B | 支持文本生成视频和图像生成视频的混合版本,单一模型满足两大核心任务需求 | 🤗 Wan2.2-TI2V-5B |
| 图生视频 | Wan2.2-I2V-A14B | 14B | 将静态图像转换为动态视频,保持内容一致性和流畅的动态过程 | 🤗 Wan2.2-I2V-A14B |
| 文生视频 | Wan2.2-T2V-A14B | 14B | 从文本描述生成高质量视频,具备影视级美学控制和精准语义遵循 | 🤗 Wan2.2-T2V-A14B |
Wan2.2 提示词指南 - Wan 提供的详细提示词编写指南
ComfyUI 官方资源
ComfyOrg 官方直播回放
ComfyOrg 的 Youtube 有对 Wan2.2 在 ComfyUI 中的使用进行了详细讲解:
Wan2.2 ComfyUI 官方原生版本工作流使用指南
版本说明
ComfyUI 官方原生版本由 ComfyOrg 团队提供,使用 🤗 Comfy-Org/Wan_2.2_ComfyUI_Repackaged 重新打包的模型文件,确保与 ComfyUI 的最佳兼容性。
1. Wan2.2 TI2V 5B 混合版本工作流
工作流获取方式
请更新你的 ComfyUI 到最新版本,并通过菜单 工作流 -> 浏览模板 -> 视频 找到 "Wan2.2 5B video generation" 以加载工作流
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_5B_t2v.mp4"
<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/video_wan2_2_5B_ti2v.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>下载 JSON 格式工作流
模型文件下载
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ └───wan2.2_ti2v_5B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan2.2_vae.safetensors操作步骤详解
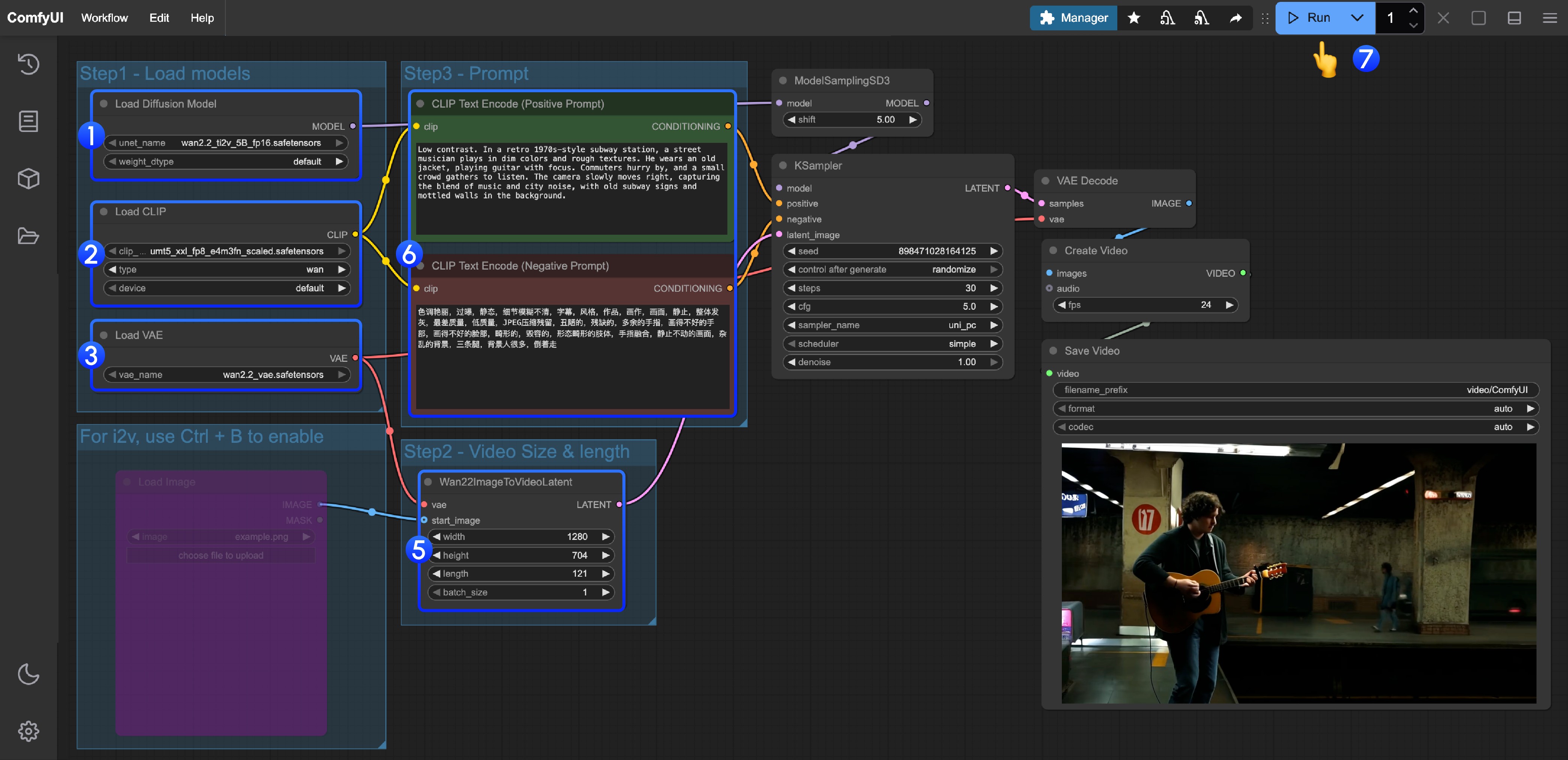
- 确保
Load Diffusion Model节点加载了wan2.2_ti2v_5B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan2.2_vae.safetensors模型 - (可选)如果你需要进行图生视频,可以使用快捷键 Ctrl+B 来启用
Load image节点来上传图片 - (可选)在
Wan22ImageToVideoLatent你可以进行尺寸的设置调整,和视频总帧数length调整 - (可选)如果你需要修改提示词(正向及负向)请在序号
5的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2. Wan2.2 14B T2V 文生视频工作流
工作流获取方式
请更新你的 ComfyUI 到最新版本,并通过菜单 工作流 -> 浏览模板 -> 视频 找到 "Wan2.2 14B T2V"
或者更新你的 ComfyUI 到最新版本后,下载下面的工作流并拖入 ComfyUI 以加载工作流
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_14B_t2v.mp4"
模型文件下载
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors操作步骤详解
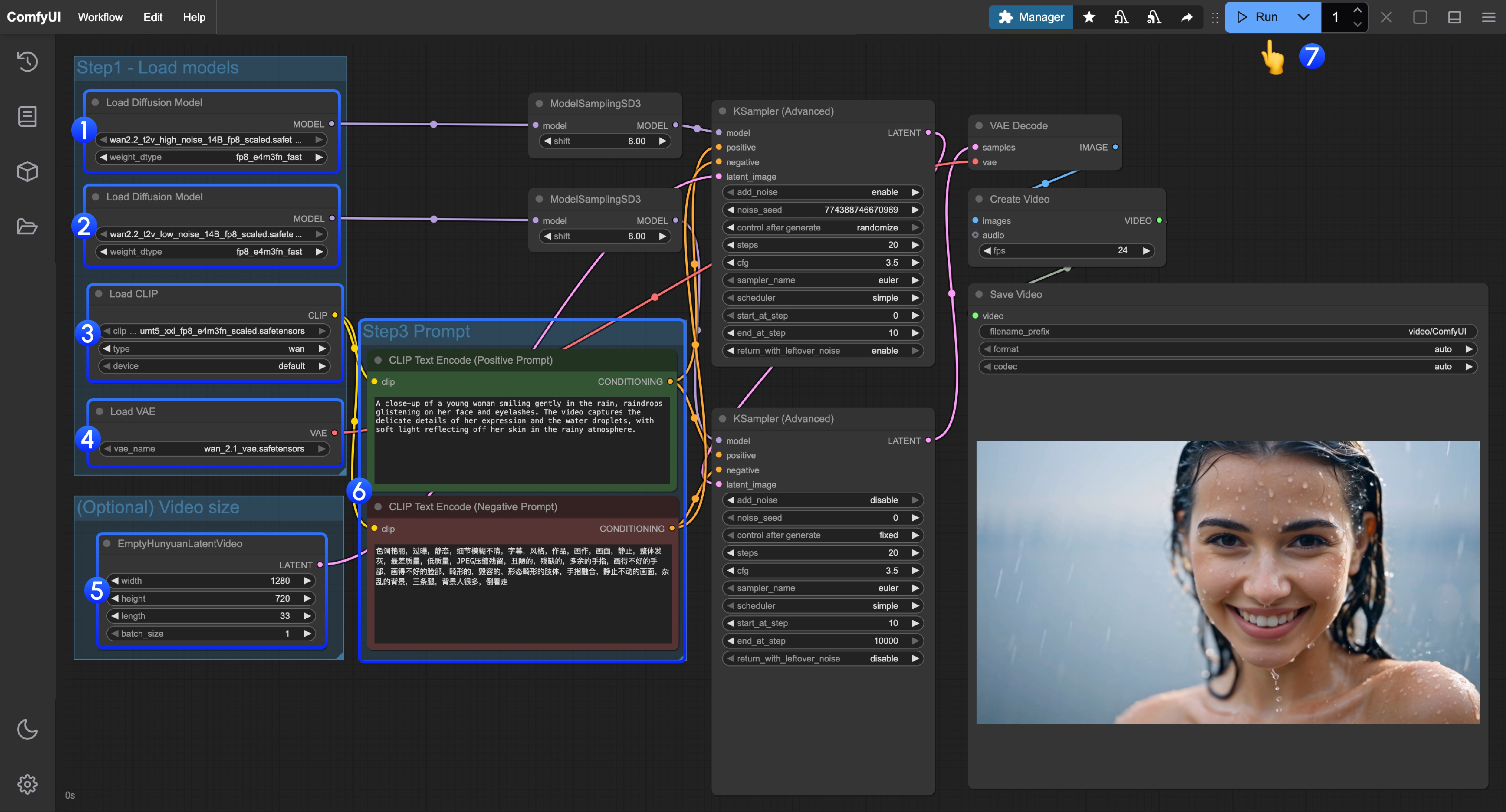
- 确保第一个
Load Diffusion Model节点加载了wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors模型 - 确保第二个
Load Diffusion Model节点加载了wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - (可选)在
EmptyHunyuanLatentVideo你可以进行尺寸的设置调整,和视频总帧数length调整 - 如果你需要修改提示词(正向及负向)请在序号
6的CLIP Text Encoder节点中进行修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
3. Wan2.2 14B I2V 图生视频工作流
工作流获取方式
请更新你的 ComfyUI 到最新版本,并通过菜单 工作流 -> 浏览模板 -> 视频 找到 "Wan2.2 14B I2V" 以加载工作流
或者更新你的 ComfyUI 到最新版本后,下载下面的工作流并拖入 ComfyUI 以加载工作流
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan_2_2_14B_i2v.mp4"
你可以使用下面的图片作为输入

模型文件下载
Diffusion Model
VAE
Text Encoder
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_i2v_low_noise_14B_fp16.safetensors
│ │ └─── wan2.2_i2v_high_noise_14B_fp16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors操作步骤详解
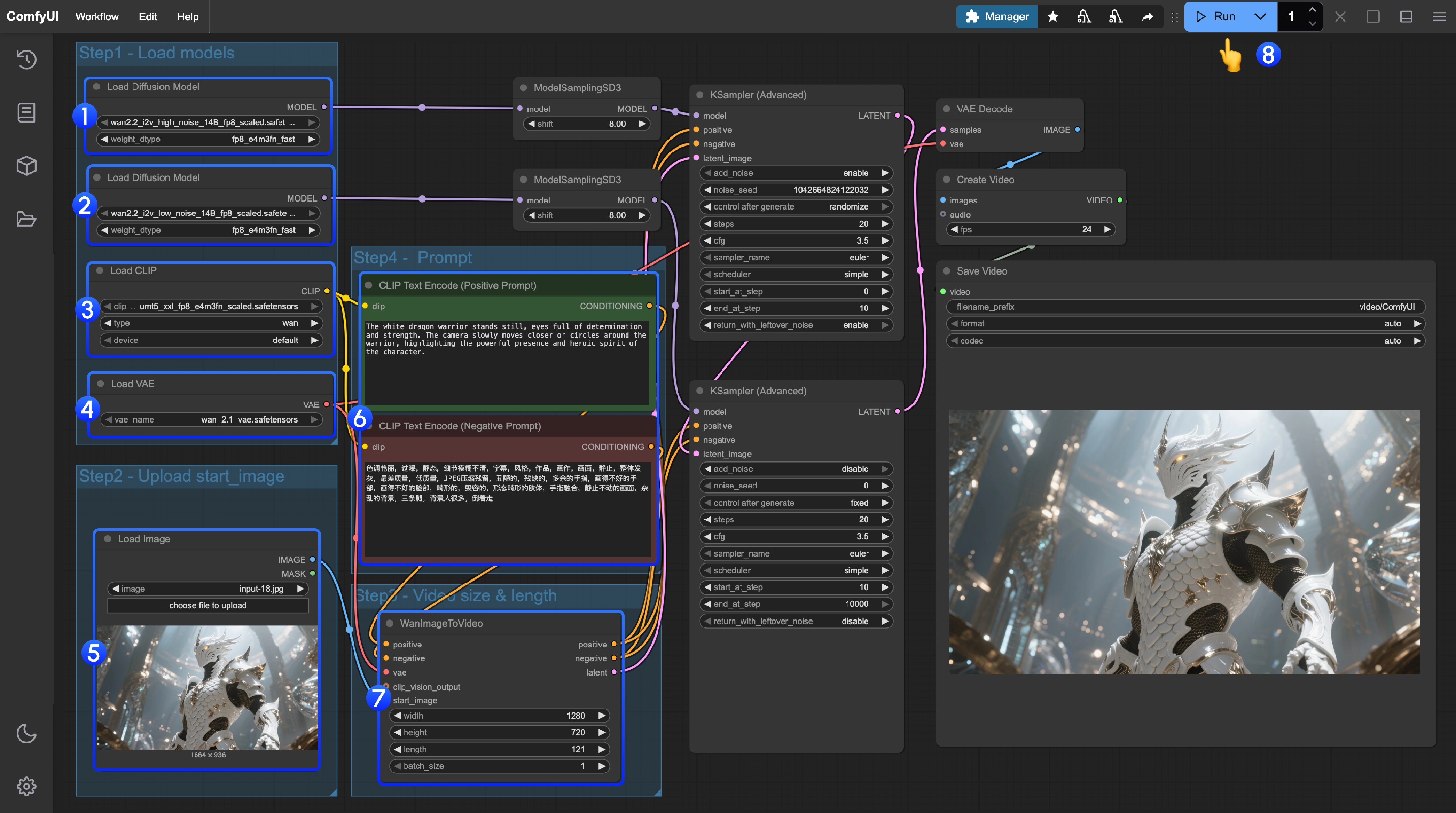
- 确保第一个
Load Diffusion Model节点加载了wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors模型 - 确保第二个
Load Diffusion Model节点加载了wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 在
Load Image节点上传作为起始帧的图像 - 如果你需要修改提示词(正向及负向)请在序号
6的CLIP Text Encoder节点中进行修改 - 可选)在
EmptyHunyuanLatentVideo你可以进行尺寸的设置调整,和视频总帧数length调整 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
4. Wan2.2 14B FLF2V 首尾帧视频生成工作流
首尾帧工作流使用模型位置与 I2V 部分完全一致
工作流及素材获取
下载下面的视频或者 JSON 格式工作流在 ComfyUI 中打开 <video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/2.2/wan22_14B_flf2v.mp4"
下载下面的素材作为输入


操作步骤详解
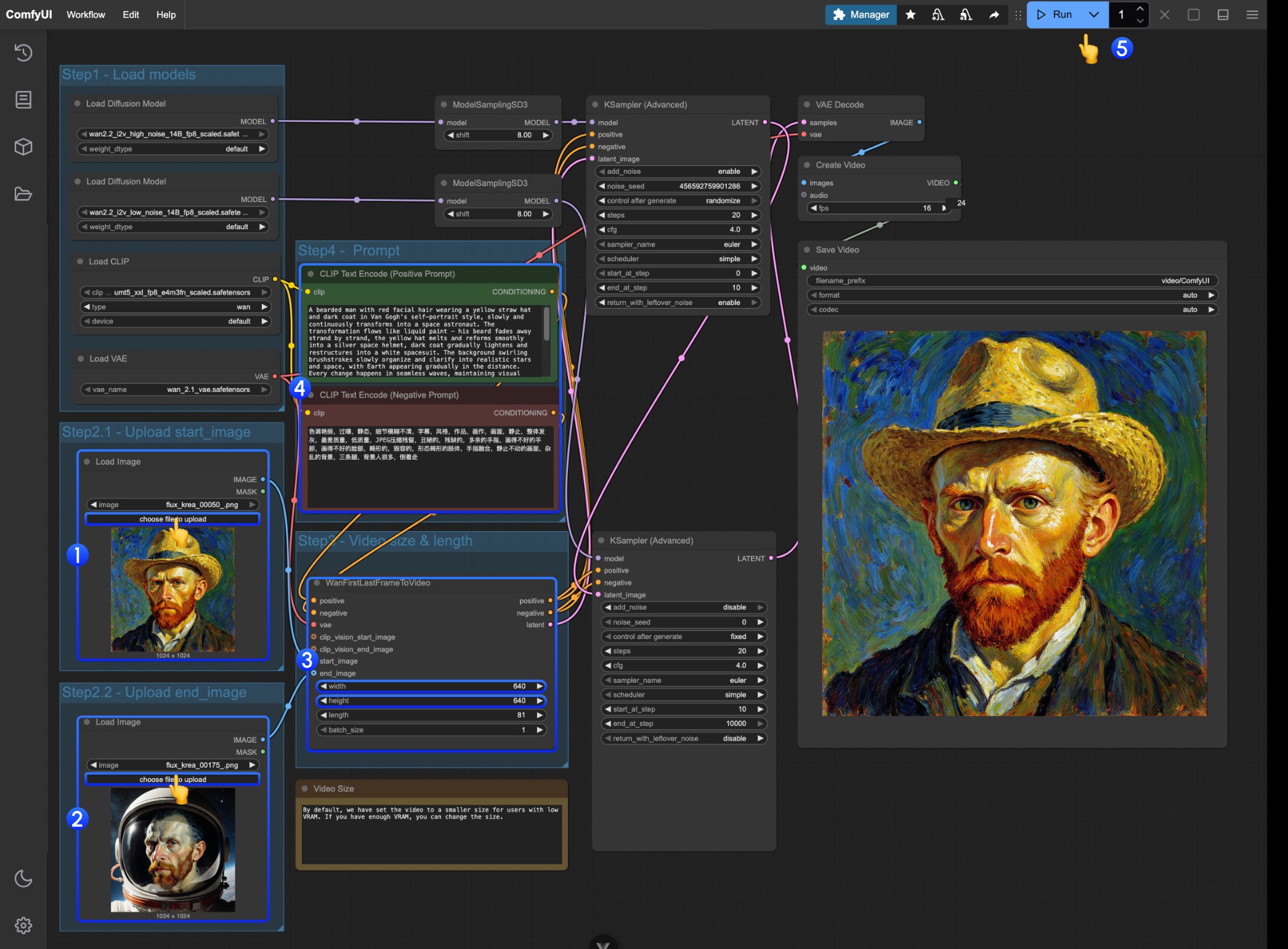
- 在第一个
Load Image节点上传作为起始帧的图像 - 在第二个
Load Image节点上传作为起始帧的图像 - 在
WanFirstLastFrameToVideo上修改尺寸设置- 工作流默认设置了一个比较小的尺寸,防止低显存用户运行占用过多资源
- 如果你有足够的显存,可以尝试 720P 左右尺寸
- 根据你的首尾帧撰写合适的提示词
- 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.2 Kijai WanVideoWrapper ComfyUI 工作流
这部分教程将介绍使用 Kijai/ComfyUI-WanVideoWrapper 的便捷方式。
相关模型仓库:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled
Wan2.2 GGUF 量化版 ComfyUI 工作流
GGUF 版本适用于显存有限的用户,提供以下资源:
相关自定义节点: City96/ComfyUI-GGUF
Lightx2v 4steps LoRA 使用说明
Lightx2v 提供了快速生成优化方案:
评论
使用 GitHub 登录后即可参与讨论。