SVD_图像到视频_条件节点
了解 ComfyUI 中的 SVD_img2vid_Conditioning 节点,用于为视频生成任务生成条件数据,特别适用于与 SVD_img2vid 模型一起使用。它接受各种输入,包括初始图像、视频参数和 VAE 模型,以生成可以用于指导视频帧生成的条件数据。
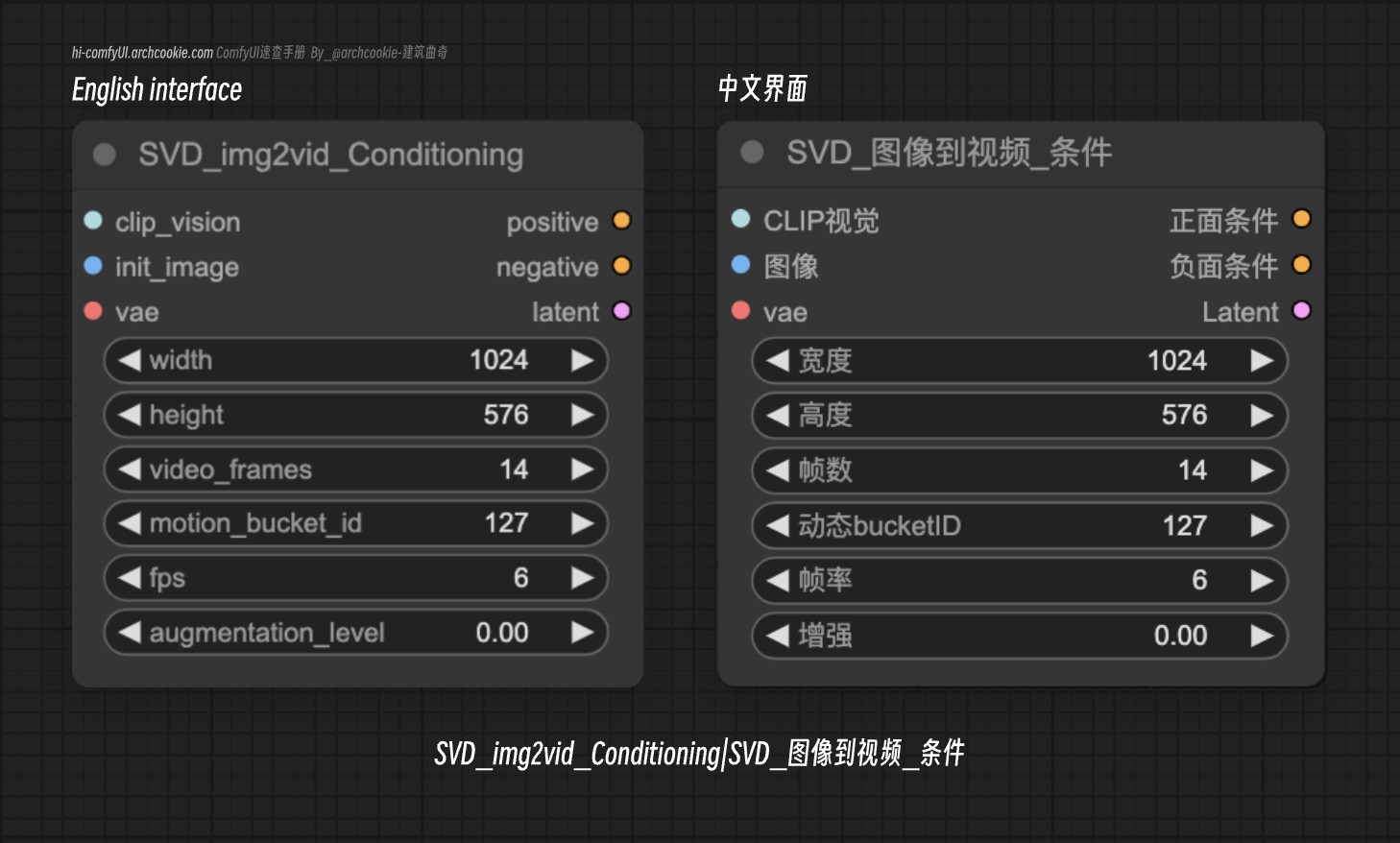
文档说明
- 类名:
SVD_img2vid_条件 - 类别:
条件/视频模型 - 输出节点:
False
此节点旨在为视频生成任务生成条件数据,特别适用于SVD_img2vid模型。它接受各种输入,包括初始图像、视频参数和VAE模型,以产生可用于指导视频帧生成的条件数据。
输入类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
clip_vision | CLIP_VISION | 用于从初始图像编码视觉特征的CLIP视觉模型,对理解图像内容和视频生成上下文至关重要。 |
init_image | IMAGE | 视频将从中生成的初始图像,作为视频生成过程的起点。 |
vae | VAE | 用于将初始图像编码到潜在空间的变分自编码器(VAE)模型,有助于生成连贯和连续的视频帧。 |
width | INT | 要生成的视频帧的期望宽度,允许自定义视频的分辨率。 |
height | INT | 要生成的视频帧的高度,可以控制视频的宽高比和分辨率。 |
video_frames | INT | 为视频生成的帧数,决定视频的长度。 |
motion_bucket_id | INT | 用于分类将要应用的视频生成中运动类型的标识符,有助于创造动态和吸引人的视频。 |
fps | INT | 视频的每秒帧数(fps),影响生成视频的平滑度和真实感。 |
augmentation_level | FLOAT | 控制应用于初始图像的增强水平的参数,影响生成视频帧的多样性和可变性。 |
输出类型
| 参数名称 | 数据类型 | 作用 |
|---|---|---|
positive | CONDITIONING | 正面条件数据,由编码特征和参数组成,指导视频生成过程朝着期望的方向发展。 |
negative | CONDITIONING | 负面条件数据,与正面条件形成对比,可用于避免生成视频中的某些模式或特征。 |
latent | LATENT | 为视频中的每一帧生成的潜在表示,作为视频生成过程的基础组成部分。 |
评论
使用 GitHub 登录后即可参与讨论。