ComfyUI Frame Pack 工作流完整逐步使用教程
本篇教程将会带你了解如何在 ComfyUI 中使用 Frame Pack 工作流,并提供详细的步骤说明
FramePack 是由斯坦福大学博士、ControlNet 作者张吕敏(Lvmin Zhang)团队开发的一项 AI 视频生成技术。其主要特点包括:
- 动态上下文压缩:通过对视频帧按重要性进行分级压缩,关键帧保留 1536 个特征标记,过渡帧精简至 192 个。
- 抗漂移采样:采用双向记忆法和倒序生成术,避免画面漂移,确保动作连贯性。
- 显存需求降低:将视频生成所需的显存门槛从专业级硬件(12GB+)降至消费级水平(仅需 6GB 显存),使普通用户使用 RTX 3060 笔记本即可生成长达 60 秒的高质量视频。
- 开源与集成:目前 FramePack 已开源并集成至腾讯混元视频模型,支持多模态输入(文字+图像+语音)和实时交互生成。
Frame Pack 相关原始链接
- 原始仓库:https://github.com/lllyasviel/FramePack/
- 在 Windows上 无需 ComfyUI 的一键运行整合包:https://github.com/lllyasviel/FramePack/releases/tag/windows
对应提示词
lllyasviel 在对应仓库提供了一段用于视频生成的 GPT 提示词,如果你在使用 frame pack 工作流时不知道怎么写提示词,可以试试。
- 复制下面的提示词,发送给 GPT
- 等 GPT 了解要求后把对应图片提供给它,你就会得到对应的提示词。
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.目前 Frame Pack 在 ComfyUI 中的实现
目前有三个自定义节点作者在 ComfyUI 中实现了 Frame Pack 的能力
- Kijai: ComfyUI-FramePackWrapper
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
这些自定义节点的差别
下面我们说明下这几个自定义节点实现的工作流的差异所在。
Kijai 的自定义插件
Kijai 使用了重新打包了对应的模型,我想你肯定已经用过 Kijai 的相关自定义节点了,感谢他每次都带来如此迅速的更新!
其中 Kijai 的版本似乎没有在 ComfyUI Manager 中注册,所以目前无法通过 Manager 的 Custom nodes Manager 来进行安装,你需要通过 Manager 的 Git 或者手动安装。
特点:
- 支持首尾帧视频生成
- 需要通过 Git 安装或者手动安装
- 模型重新可复用
HM-RunningHub 与 汤圆猪(TTPlanetPig) 的自定义插件
这两个自定义节点是源于相同代码的修改版本,原始版本由 HM-RunningHub 创建,然后 汤圆猪(TTPlanetPig) 实现了 FramePack 的首尾帧视频生成,并基于对应插件源码做了修改,你可以看这个 PR
这两个自定义节点使用的模型文件夹结构是一致的,都是未重新打包过的原始仓库模型文件,所以你这些模型文件,在其它不支持这个文件夹结构的的自定义节点中,会无法使用到这些模型,导致磁盘空间占用较大
特点:
- 支持首尾帧视频生成
- 下载的模型文件你可能无法在其它节点或者工作流中复用
- 对磁盘空间占用较大,因为使用的模型文件都是没有重新打包的
- 有些依赖的兼容性问题
Kijai ComfyUI-FramePackWrapper 首尾帧视频生成实现 ComfyUI 工作流
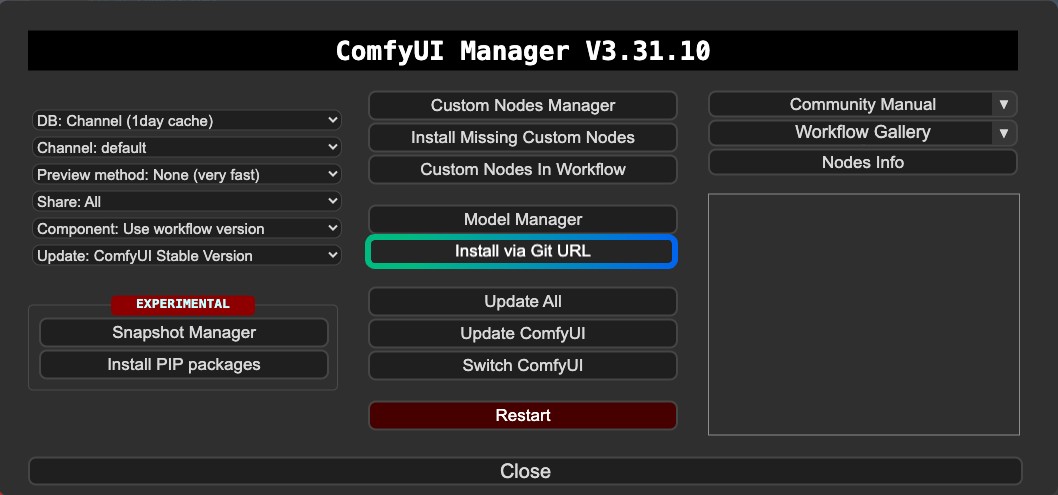
1. 插件安装
对于 ComfyUI-FramePackWrapper 你可能需要使用 Manager 的 Git 安装:
下面是你可能用到的文章:
2. 工作流文件下载
下载下面的视频文件,并拖入 ComfyUI 中加载对应的工作流, 我已经在文件中添加了对应模型信息,会提示你进行模型下载
视频预览
下载下面的图片,我们将用作图片输入


3. 手动模型安装
如果你无法顺利下载工作流中的模型,请下载下面的模型,并保存到对应位置
CLIP Vision
VAE
Text Encoder
Diffusion Model Kijai 提供了两个精度的版本,你选择一个下载就好了,你可以根据你的显卡性能选择对应的版本
| 文件名 | 精度 | 体积 | 下载链接 | 显卡性能要求 |
|---|---|---|---|---|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | 下载链接 | 高 |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | 下载链接 | 低 |
文件保存位置
📂 ComfyUI/
├──📂 models/
│ ├──📂 diffusion_models/
│ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # 或者 bf16 精度
│ ├──📂 text_encoders/
│ │ ├─── clip_l.safetensors
│ │ └─── llava_llama3_fp16.safetensors
│ ├──📂 clip_vision/
│ │ └── sigclip_vision_patch14_384.safetensors
│ └──📂 vae/
│ └── hunyuan_video_vae_bf16.safetensors4. 按步骤完成对应工作流的运行
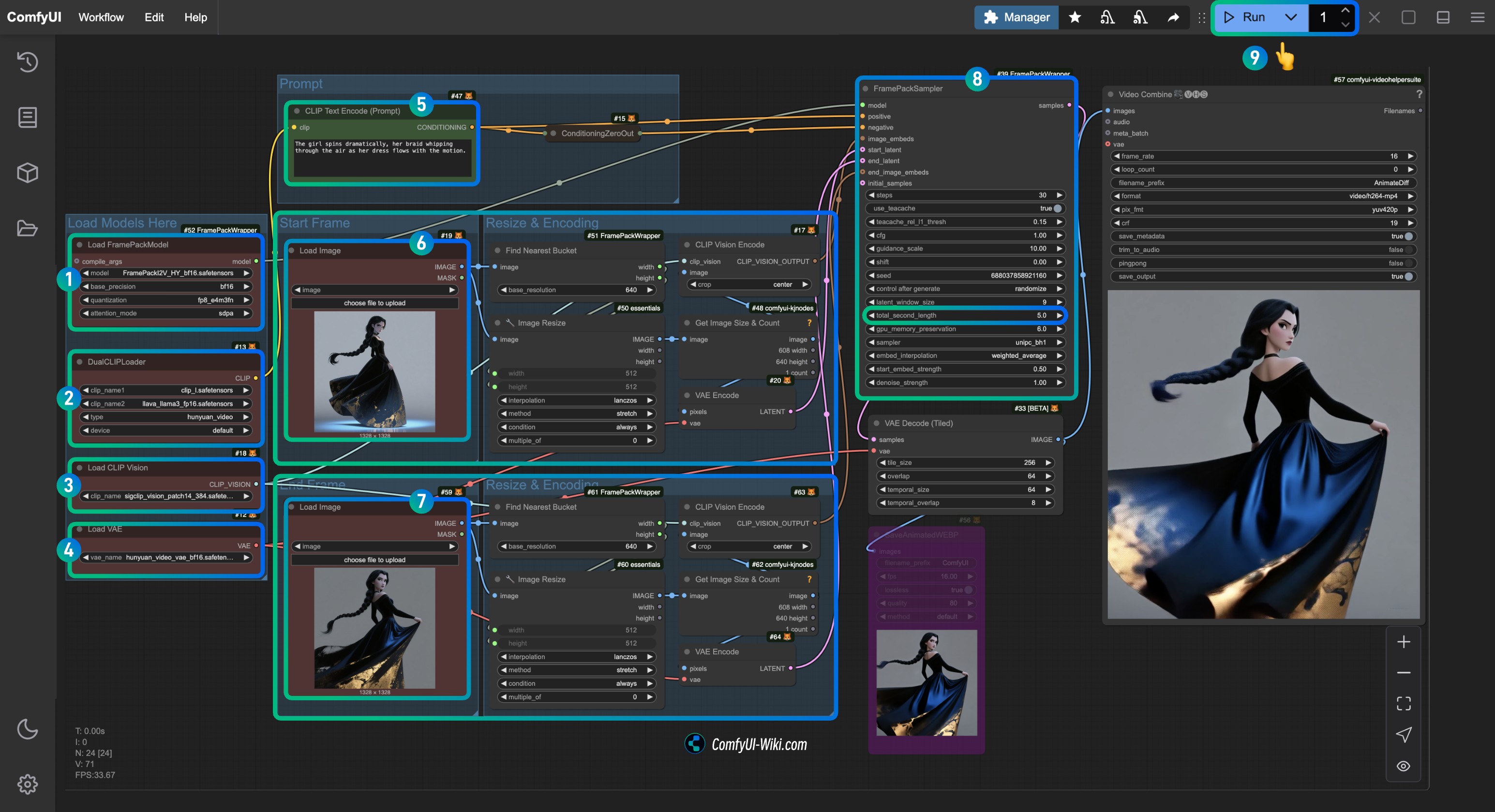
- 确保
Load FramePackModel节点加载了FramePackI2V_HY_fp8_e4m3fn.safetensors模型 - 确保
DualCLIPLoader节点加载了:clip_l.safetensors模型llava_llama3_fp16.safetensors模型
- 确保
Load CLIP Vision节点加载了sigclip_vision_patch14_384.safetensors模型 - 可以在
Load VAE节点加载了hunyuan_video_vae_bf16.safetensors模型 - (可选,如果使用我的 input 图片)修改
CLIP Text Encoder节点中的Prompt参数,输入你想要生成的视频描述内容 - 在
Load Image节点中加载first_frame.jpg这整个区域都是first_frame的输入处理相关的节点 - 在
Load Image节点中加载last_frame.jpg这整个区域都是last_frame的输入处理相关的节点(如果你不需要尾帧,可以删除或者使用 ByPass 来禁用) - 在
FramePackSampler节点中,可以修改total_second_length参数,来修改视频的时长,我的工作流中是5秒,你可以根据你的需求修改 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
如果不需要尾帧,请绕过(Bypass)整个 last_frame 的输入处理相关节点
HM-RunningHub 与 TTPlanetPig 插件详细说明
这两个插件使用的模型存储位置是一致的,但是和我开头所说,他们使用模型的方式就是下载原始的整个仓库,需要保存到指定位置,这导致其它的插件并没有办法复用这些模型会造成一定硬盘空间浪费,不过实现了首尾帧生成,如果你想要体验可以尝试一下。
插件安装
- 下面二选一或者都安装,节点有所差异,但都是只有一个节点,使用起来也很简单
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
- 提升 ComfyUI 中视频编辑体验能力
如果你有使用过视频相关工作流 VideoHelperSuite 在目前扩展 ComfyUI 视频能力上还是非常关键的。
1. 模型下载
HM-RunningHub 提供了一个 python 脚本用来下载所有的模型,你只需要使用运行这个脚本,然后按照提示操作即可。
我的操作是,把下面的代码保存为 download_models.py 文件并保存到ComfyUI/models 的根目录下,然后在对应目录中使用终端运行 python download_models.py 运行这个脚本。
cd <你的安装路径>/ComfyUI/models/然后
python download_models.py当然这需要你的python独立环境 / 系统环境有安装了 huggingface_hub 这个包
from huggingface_hub import snapshot_download
# Download HunyuanVideo model
snapshot_download(
repo_id="hunyuanvideo-community/HunyuanVideo",
local_dir="HunyuanVideo",
ignore_patterns=["transformer/*", "*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download flux_redux_bfl model
snapshot_download(
repo_id="lllyasviel/flux_redux_bfl",
local_dir="flux_redux_bfl",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download FramePackI2V_HY model
snapshot_download(
repo_id="lllyasviel/FramePackI2V_HY",
local_dir="FramePackI2V_HY",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)当然你也可以使用手动下载的方式,下载下面的模型,并保存到对应位置,也就是下载对应仓库的所有文件
- HunyuanVideo: HuggingFace Link
- Flux Redux BFL: HuggingFace Link
- FramePackI2V: HuggingFace Link
文件保存结构
comfyui/models/
flux_redux_bfl
├── feature_extractor
│ └── preprocessor_config.json
├── image_embedder
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── image_encoder
│ ├── config.json
│ └── model.safetensors
├── model_index.json
└── README.md
FramePackI2V_HY
├── config.json
├── diffusion_pytorch_model-00001-of-00003.safetensors
├── diffusion_pytorch_model-00002-of-00003.safetensors
├── diffusion_pytorch_model-00003-of-00003.safetensors
├── diffusion_pytorch_model.safetensors.index.json
└── README.md
HunyuanVideo
├── config.json
├── model_index.json
├── README.md
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ └── model.safetensors.index.json
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── vae
├── config.json
└── diffusion_pytorch_model.safetensors2. 工作流下载
HM-RunningHub
汤圆猪(TTPlanetPig)
