腾讯混元团队开源 MixGRPO 框架,提升人类偏好对齐训练效率
腾讯混元团队发布开源 MixGRPO 框架,首个集成滑动窗口混合 ODE-SDE 采样的 GRPO 框架,可将训练速度提升71%,适用于扩散模型和流模型的人类偏好对齐任务。
腾讯混元团队正式开源了 MixGRPO 框架!这是首个集成滑动窗口混合 ODE-SDE 采样技术的 GRPO (Generalized Reward-based Policy Optimization) 框架,专门用于提升人工智能模型的人类偏好对齐效率。
该框架在保持优秀性能的同时,显著降低了训练开销。其中 MixGRPO-Flash 版本最高可实现 71% 的训练速度提升,超越了之前的 DanceGRPO 等方法。
 不同去噪步数优化的性能比较。DanceGRPO的性能提升依赖于更多优化步骤,而MixGRPO仅需4步即可达到最佳性能
不同去噪步数优化的性能比较。DanceGRPO的性能提升依赖于更多优化步骤,而MixGRPO仅需4步即可达到最佳性能
MixGRPO 框架特点
核心技术创新
- 滑动窗口混合采样: 首个集成滑动窗口混合 ODE-SDE 采样的 GRPO 框架
- 显著提升效率: MixGRPO-Flash 版本训练速度提升高达 71%
- 高阶求解器支持: 支持高阶 ODE 求解器,进一步加速训练过程
- 通用兼容性: 同时适用于扩散模型和流模型
 MixGRPO的技术架构示意图,展示了滑动窗口机制的工作原理
MixGRPO的技术架构示意图,展示了滑动窗口机制的工作原理
性能优势
- 训练开销大幅降低: 相比传统方法显著减少计算资源消耗
- 效果超越前代: 在效果和效率两方面都优于 DanceGRPO 等之前的方法
- 快速收敛: 仅需少量迭代步骤即可实现模型潜力
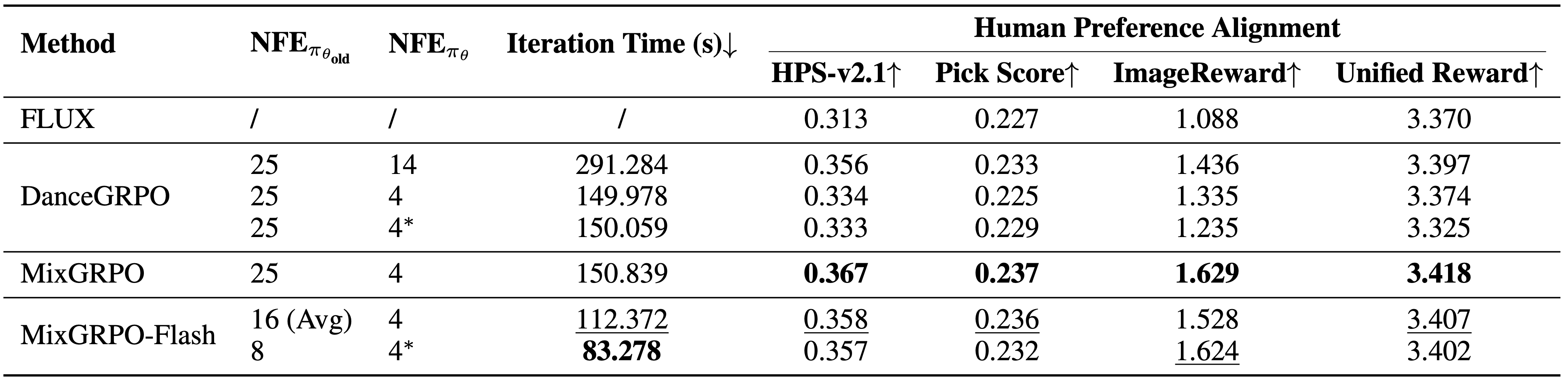 开销和性能比较结果。MixGRPO在多个指标上达到最佳性能,MixGRPO-Flash大幅降低采样时间的同时超越DanceGRPO
开销和性能比较结果。MixGRPO在多个指标上达到最佳性能,MixGRPO-Flash大幅降低采样时间的同时超越DanceGRPO
技术应用场景
MixGRPO 框架主要用于人类偏好对齐任务,这是人工智能领域的重要研究方向。通过该框架,研究人员可以:
- 更高效地训练符合人类偏好的图像生成模型
- 降低大规模模型训练的计算成本
- 在保持模型质量的前提下加速实验迭代
该技术对于提升 AI 生成内容的质量和用户满意度具有重要意义,特别是在图像生成、内容创作等应用场景中。
实验效果展示
 定性比较结果。MixGRPO在语义和美学两方面都达到了优秀的性能表现
定性比较结果。MixGRPO在语义和美学两方面都达到了优秀的性能表现
 不同训练时采样步数的定性比较。MixGRPO的性能不会随着开销的减少而显著降低
不同训练时采样步数的定性比较。MixGRPO的性能不会随着开销的减少而显著降低
 使用不同策略采样图像的t-SNE可视化。在去噪过程的早期阶段采用SDE采样会产生更离散的数据分布
使用不同策略采样图像的t-SNE可视化。在去噪过程的早期阶段采用SDE采样会产生更离散的数据分布
开源资源获取
目前 MixGRPO 框架已完全开源,研究人员和开发者可以通过以下渠道获取相关资源:
相关链接
- 项目主页: https://tulvgengenr.github.io/MixGRPO-Project-Page/
- 代码仓库: https://github.com/Tencent-Hunyuan/MixGRPO
- 研究论文: https://arxiv.org/abs/2507.21802
MixGRPO 的开源将为人工智能研究社区提供强有力的工具支持,推动人类偏好对齐技术的进一步发展和应用。