Wan2.1 Fun Control ComfyUI 工作流 - 完整指南
本教程详细介绍了如何在 ComfyUI 中使用通义 Wan Fun Control 模型,包括完整的模型安装,工作流使用等等内容。
Wan2.1-Fun-Control 是阿里团队最新发布的视频控制能力,可以实现视频的depth,openpose,canny等控制能力,目前这一模型分为 1.3B 和 14B 两大类模型。
本篇指南将涉及两类工作流
- ComfyUI 原生工作流
-
- 完全原生(不依赖第三方自定义节点)
-
- 在原生工作流上的改进版本(使用了自定义节点)
- 使用 Kijai 的 ComfyUI-WanVideoWrapper 工作流
- 两个工作流在模型上基本相同,不过我还是使用了不同来源的模型只是为了更符合原始工作流的情况和模型使用。
- 对于视频相关你可以使用 ComfyUI-VideoHelperSuite 这个自定义节点包来完成视频加载、保存成 mp4 视频合并等等丰富的视频操作
- 插件安装请参考如何安装自定义节点 这篇指南完成
ComfyUI 原生 Wan2.1 Fun Control 工作流
目前 ComfyUI 官方已经原生支持了 Wan Fun Control 模型,但是截止目前(2025-04-10)并未官方正式式发布对应的工作流示例
在开始之前你需要保证你的 ComfyUI 版本至少在这个commit之后,你才能找到对应的WanFunControlToVideo节点 请参考 如何更新 ComfyUI 来更新你的 ComfyUI 版本。
1.1 Wan2.1 Fun Control 工作流文件下载
1.1.1 工作流文件
下载下面的图片,并拖入 ComfyUI 中,将会加载对应的工作流,并提示对应的模型下载。

Json 格式下载
1.1.2 起始帧及控制视频
下载下面的图片及视频,我们将会将他们作为输入条件

1.2 手动模型安装
如果对应的模型没有成功下载,下面是对应的模型下载地址
Diffusion models 选择 1.3B 或者 14B, 14B 的文件体积更大,效果更好,但同时对设备性能要求也更高
- Wan2.1-Fun-1.3B-Control: 下载后重命名为
Wan2.1-Fun-1.3B-Control.safetensors - Wan2.1-Fun-14B-Control: 下载后重命名为
Wan2.1-Fun-14B-Control.safetensors
Text encoders 选择下面两个模型中的一个,fp16 体积较大对性能要求高
VAE
CLIP Vision 用于提取图像特征
文件保存位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── Wan2.1-Fun-1.3B-Control.safetensors # 或者你选择的版本
│ ├── 📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── 📂 vae/
│ │ └── wan_2.1_vae.safetensors
│ └── 📂 clip_vision/
│ └── clip_vision_h.safetensors1.3 按步骤完成工作流的运行
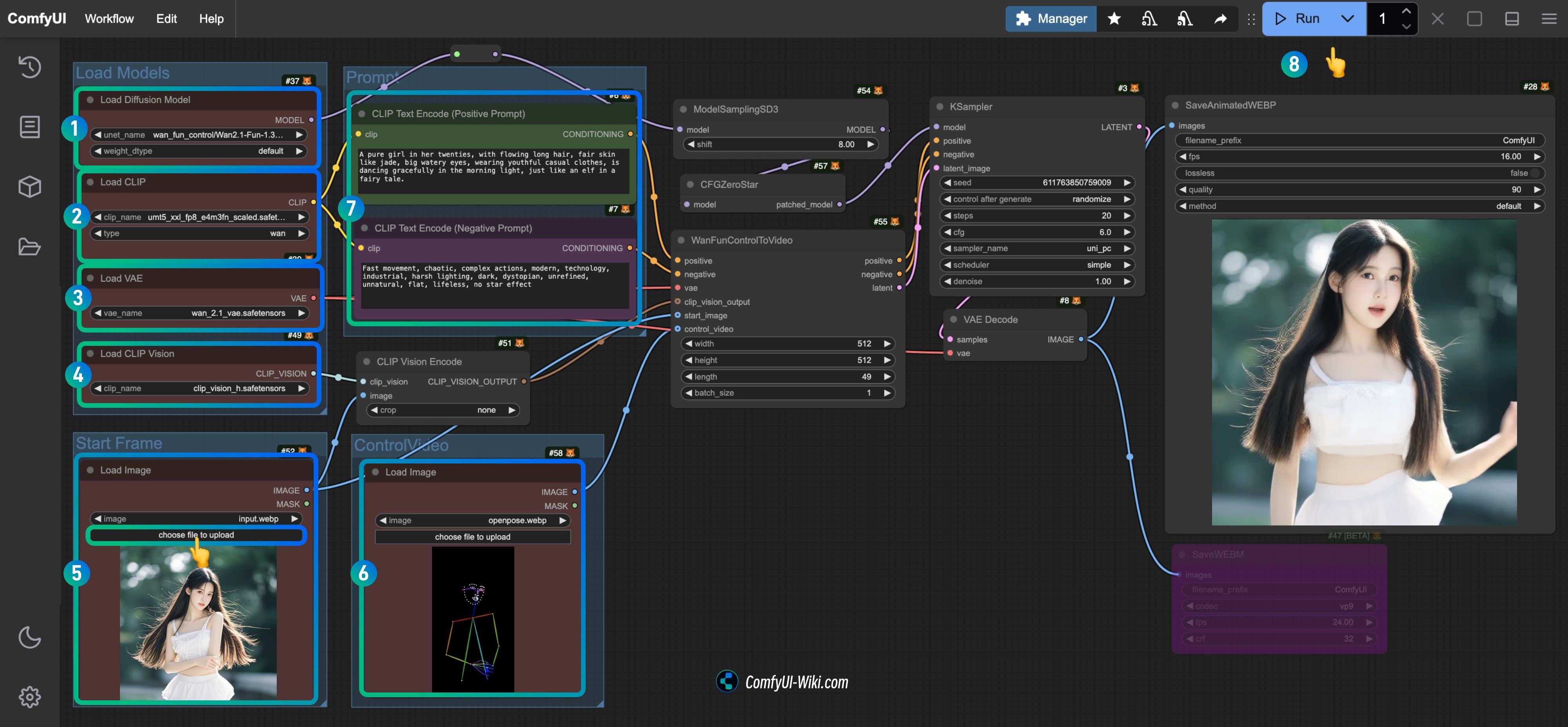
- 确保
Load Diffusion Model节点加载了Wan2.1-Fun-1.3B-Control.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载前面提供的输入图片作为起始帧 - 在
Load Image节点上传前面提供的视频,作为控制条件 - (可选)在
CLIP Text Encoder节点中修改视频提示词 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
1.4 工作流分析
原生的工作流主要在视频帧获取,对应的 WanFunControlToVideo 节点提供的默认的 Length 为 81(以 15 帧每秒将会生成 5秒的视频),而我的提供的控制视频仅有 49 帧,所以我进行了调整修改。 另外你可能看到人物在视频生成后被突然拉近了,这是因为起始帧图像和控制视频他们的尺寸不一致,导致处理过程中进行了裁切放大
2. Wan2.1 Fun Control 原生工作流调整版本
由于完全原生的工作流在视频尺寸和帧数计算上使用起来不是很便利,所以在这个改进版本的工作流中我使用了下面自定义节点包中的部分节点:
- ComfyUI-KJNodes 调整视频尺寸和获取图像帧数
- ComfyUI-comfyui_controlnet_aux: 进行视频图像的预处理
在开始前,确保你已经安装了这两个自定义节点包,或者使用 ComfyUI-Manager 在工作流加载后进行安装
2.1 工作流文件下载
2.1.1 工作流文件下载
下载下面的图片,并拖入 ComfyUI 中,将会加载对应的工作流,并提示对应的模型下载。

2.1.2 输入视频下载
下载下面的图片和视频,用于输入条件

因为没有足够的时间,还是使用了这个有突然放大效果的视频作为输入
2.2 按步骤完成工作流的运行
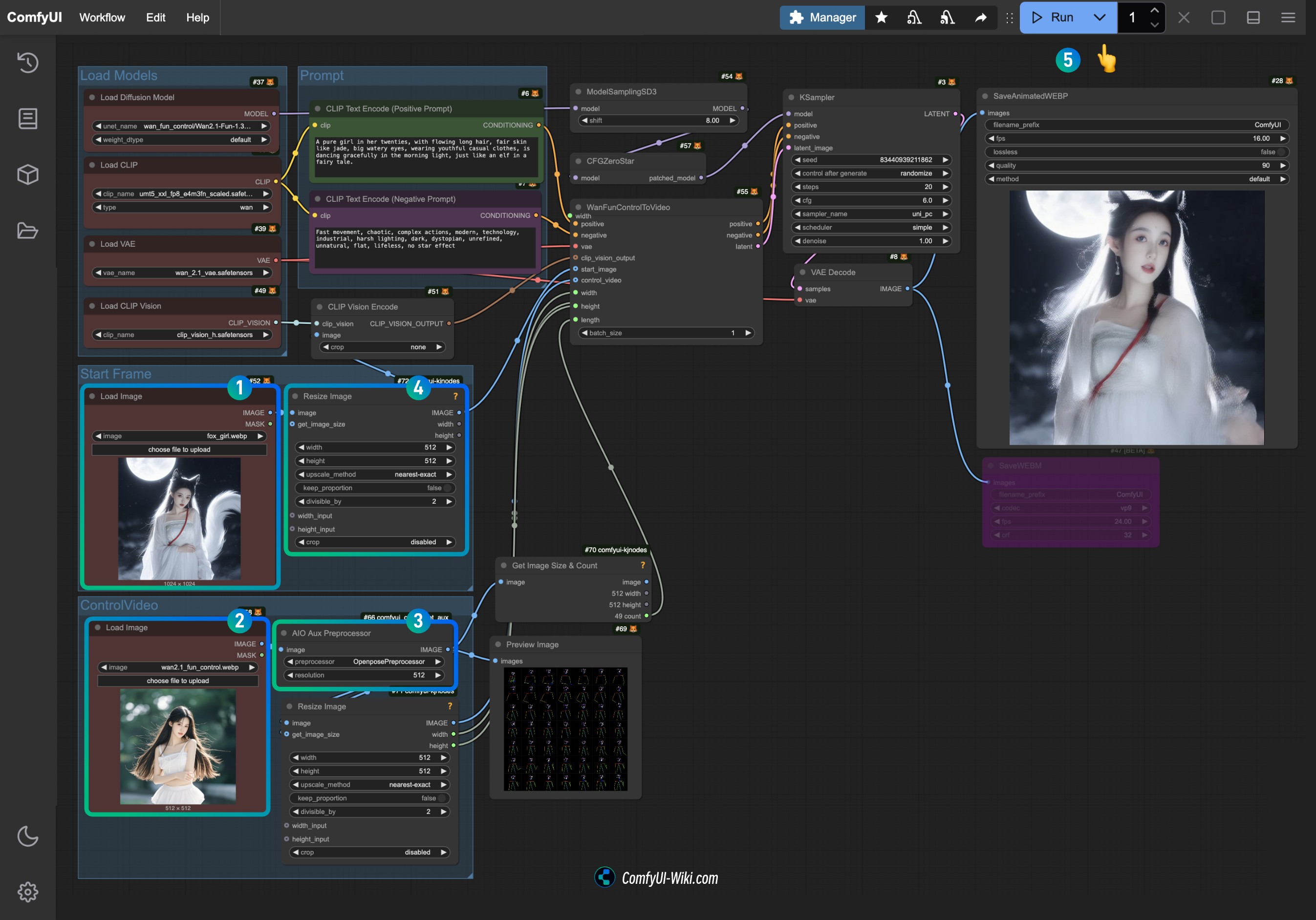
- 在 Start Frame 的
Load Image节点上传提供的输入图片 - 在 Control Video 的
Load Image节点上传前面提供的视频,作为控制条件 - 在
AIO Aux Preprocessor上选择你希望使用的预处理器(第一次运行时将会从 Hugging face下载对应模型) - 如果你需要调整尺寸,可以修改
Resize Image节点的尺寸设置,记得两个节点要保持一致 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Load Image 节点目前还不支持 mp4 视频,如果你希望有输入视频,你可以使用 ComfyUI-VideoHelperSuite 的 Load Video (Upload) 节点来完成多种格式的视频输入
3. 相关扩展
你可以在这些工作流基础上,再加上对应的图像生成的节点,从而能够不依赖输入参考图像而生成最后的视频
Kijai Wan Fun Control 工作流
将使用 Kijai 的 ComfyUI-WanVideoWrapper插件 来完成 Fun-Control 的示例,Kijai 提供的原始工作流你可以在这里找到。
本篇指南涉及的工作流,经过 ComfyUI Wiki 重新整理。
此部分工作流将分为两类:
- 仅使用视频控制条件进行 文生视频图像 的Control 工作流
- 使用 Clip_vision 对参考图片特征进行解析提取后,并添加视频控制条件的图像参考视频生成 的 Control 的工作流
相关安装
自定义节点安装
你需要安装以下几个插件,来保证工作流正常运行
- ComfyUI-WanVideoWrapper: 需要更新到最新版本
- ComfyUI-VideoHelperSuite
- ComfyUI-KJNodes
- ComfyUI-comfyui_controlnet_aux: 进行视频图像的预处理,或者你也可以替换为你常用的图像预处理节点
你可以使用 ComfyUI Manager 来更新或者安装上面提到的自定义节点,或者参考如何安装自定义节点 这篇指南完成对应的安装。
ComfyUI-comfyui_controlnet_aux 在首次运行时会下载对应的模型,请确保你可以正常访问 huggingface
模型安装
Wan2.1 Fun Control 提供了 1.3B 和 14B 两个模型,你可以根据你的设备性能选择合适的模型,
- Wan2.1-Fun-1.3B-Control: 下载后重命名为
Wan2.1-Fun-1.3B-Control.safetensors - Wan2.1-Fun-14B-Control: 下载后重命名为
Wan2.1-Fun-14B-Control.safetensors - Kijai/Wan2.1-Fun-Control-14B_fp8_e4m3fn.safetensors
从Text encoders 选择一个版本进行下载,
VAE
CLIP Vision
文件保存位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── Wan2.1-Fun-1.3B-Control.safetensors # 或者你选择的版本
│ ├── 📂 text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 或者你选择的版本
│ ├── 📂 vae/
│ │ └── Wan2_1_VAE_bf16.safetensors
│ └── 📂clip_vision/
│ └── clip_vision_h.safetensors1. 视频控制文生视频工作流
1.1 工作流文件下载
下载下面的图片,并拖入 ComfyUI 中,加载对应的工作流

Json 格式下载
下载下面的视频,作为输入视频
<video style={{ width: '100%', maxWidth: '680px' }} src="https://raw.githubusercontent.com/comfyui-wiki/ComfyUI-Wiki-Workflows/main/workflows/video/wan2.1_fun_control/input/pose.mp4" controls />
1.2 按步骤完成工作流的运行
下载下面的图片,并拖入 ComfyUI 中,加载对应的工作流
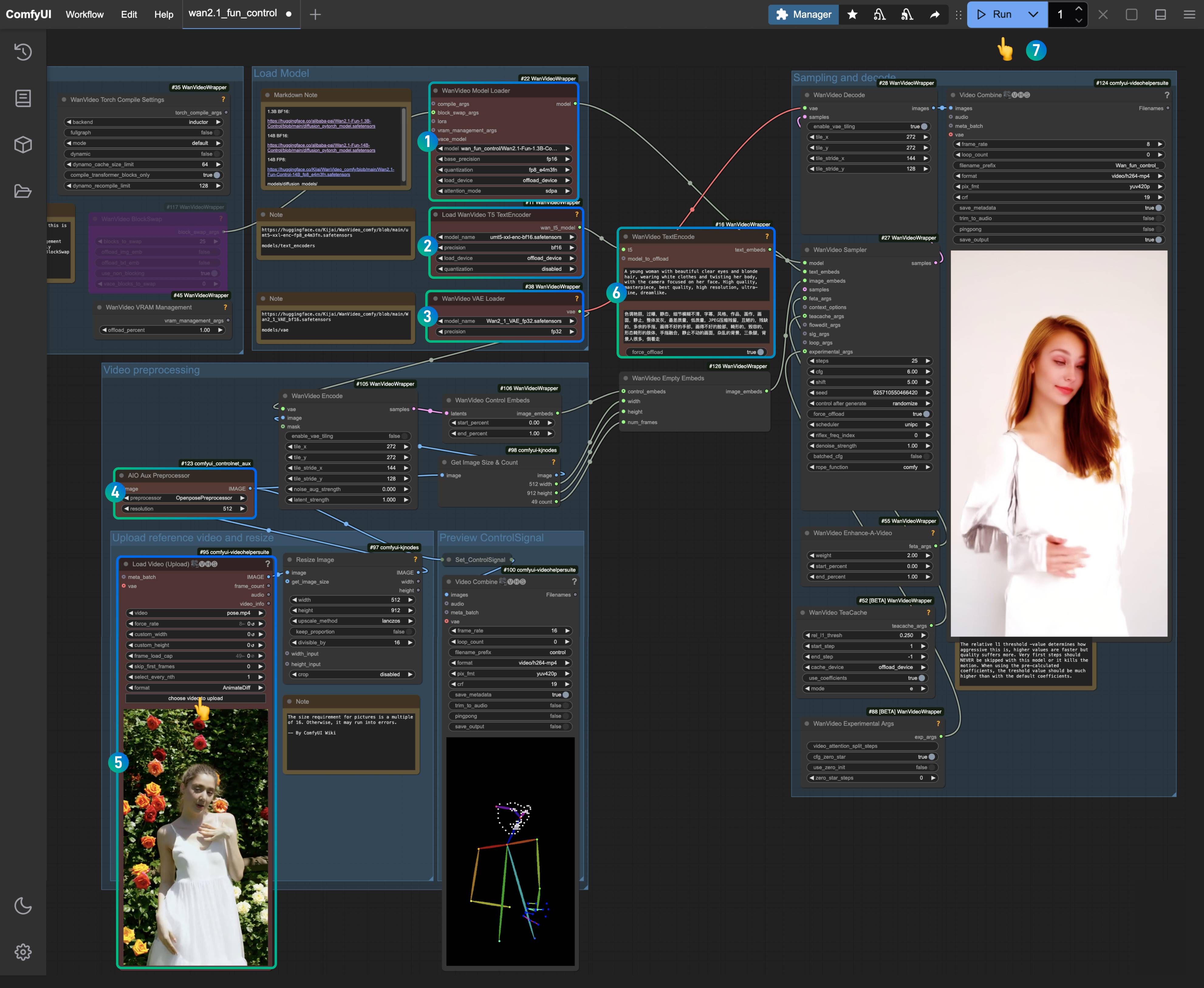
确保对应节点加载了对应模型,使用你下载的版本即可
- 确保
WanVideo Model Loader节点加载了Wan2.1-Fun-1.3B-Control.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_bf16.safetensors模型 - 在
AIO AuxAux Preprocessor节点中选择OpenposePreprocessor节点 - 在
Load Video(Upload)节点中上传前面我们提供的输入视频 - 在
WanVideo TextEncode处输入你想要生成的视频画面提示词(可不修改,保持工作流默认) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
1.3 工作流分析
这个版本的工作流,主要将预处理后的图像条件进行编码,然后再对视频进行生成,在图像预处理节点 OpenposePreprocessor 中,你可以选择多种预处理方式,比如 Openpose,Depth,Canny 等,这里我们选择 Openpose 预处理方式,生成了对应的人物动作控制并编码。
2. 视频控制参考图像视频生成的工作流
这个工作流主要加载了一个 clip_vision_h.safetensors 模型,从而可以很好地理解参考图像的内容,但并不是完全保留一致进行视频生成,而是根据参考图像的特征进行视频生成。
2.1 工作流文件下载
下载下面的图片,并拖入 ComfyUI 中,加载对应的工作流

Json 格式下载
下载下面的视频和图片,我们将会将他们作为输入条件
 

2.2 按步骤完成工作流的运行
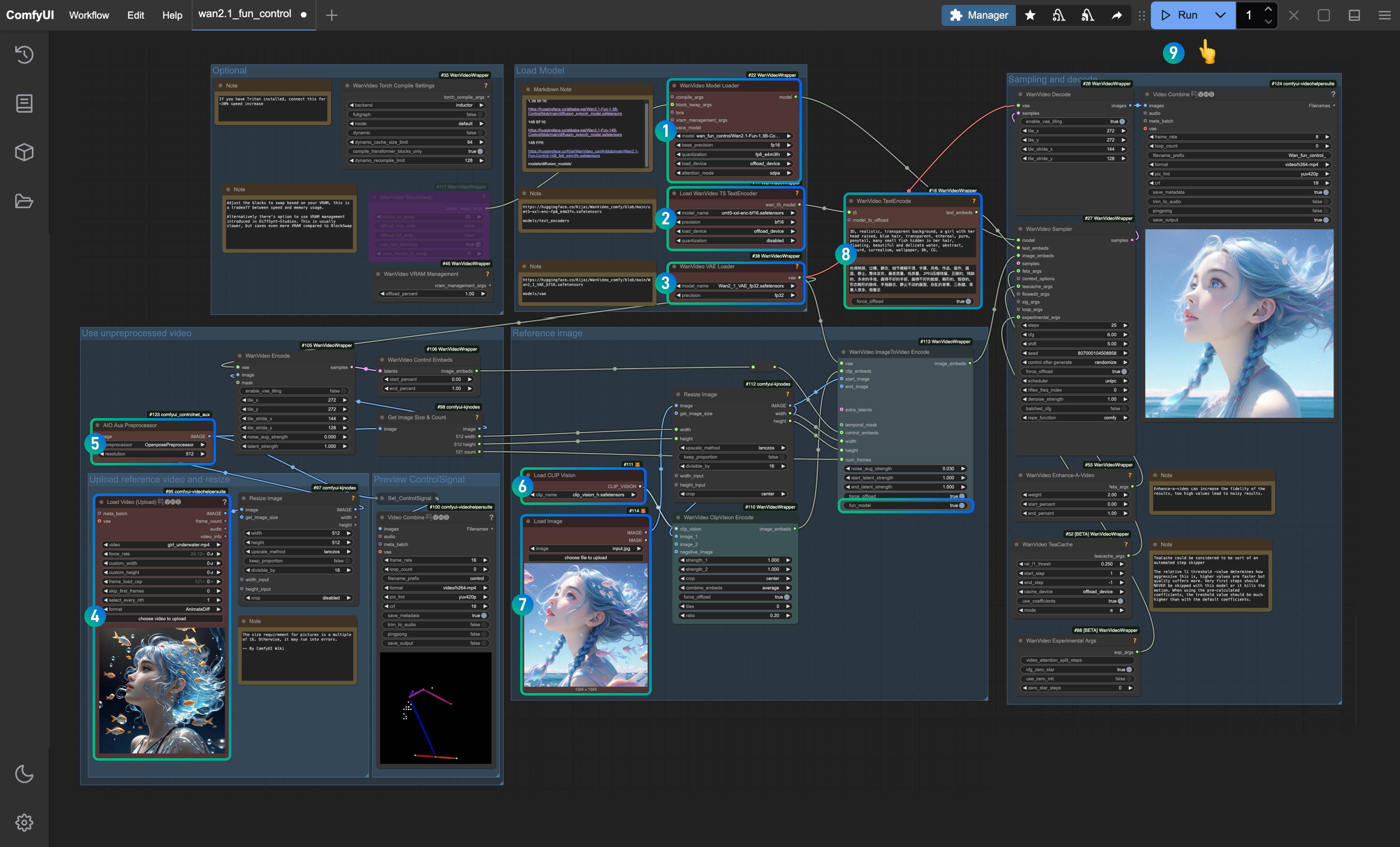
- 确保
WanVideo Model Loader节点加载了Wan2.1-Fun-1.3B-Control.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_bf16.safetensors模型 - 在
Load Video(Upload)节点中上传前面我们提供的输入视频 - 在
AIO AuxAux Preprocessor节点中选择OpenposePreprocessor节点 - 在
Load CLIP Vision节点中,选择clip_vision_h.safetensors模型被加载了,它将用于提取参考图像的特征 - 在
Load Image节点中,上传之前提供的参考图片 - 在
WanVideo TextEncode处输入你想要生成的视频画面提示词(可不修改,保持工作流默认) - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2.3 工作流分析
- 由于 Kijai 更新了对应的节点,所以请注意
WanVideo ImageToVideo Encode节点最后有一个fun_model的选项需要设置为 true。 - 经过对比,使用了参考图像的特征会更贴合,所以使用参考图像还是必要的,但是由于只是提取了图像特征,所以并不能完整地保持角色一致性。
- 在图像预处理处,你可以尝试将多个预处理节点进行组合,来生成更加丰富的控制条件。