Qwen-Image ComfyUI 原生、GGUF、Nunchaku 工作流完整使用指南
Qwen-Image 是一个拥有 20B 参数的 MMDiT(多模态扩散变换器)模型,基于 Apache 2.0 许可证开源。
Qwen-Image 是由阿里巴巴通义千问团队开发的图像生成基础模型,采用 20B 参数的 MMDiT(多模态扩散变换器)架构,以 Apache 2.0 许可证形式开源发布。该模型在图像生成领域展现出独特的技术优势,特别是在文本渲染和图像编辑方面表现突出。
核心特性:
- 多语言文本渲染能力:模型能够准确生成包含英语、中文、韩语、日语等多种语言的图像,文本清晰可读且与图像风格协调
- 丰富的艺术风格支持:从写实风格到艺术创作,从动漫风格到现代设计,模型能够根据提示词灵活切换不同的视觉风格
- 精确的图像编辑功能:支持对现有图像进行局部修改、风格转换、内容添加等操作,保持整体视觉一致性
相关资源:
Qwen-Image ComfyUI 原生工作流指南
在本篇文档所附工作流中使用的不同模型有三种
- Qwen-Image 原版模型 fp8_e4m3fn
- 8步加速版: Qwen-Image 原版模型 fp8_e4m3fn 使用 lightx2v 8步 LoRA,
- 蒸馏版:Qwen-Image 蒸馏版模型 fp8_e4m3fn
显存使用参考 GPU: RTX4090D 24GB
| 使用模型 | VRAM Usage | 首次生成 | 第二次生成 |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn 使用 lightx2v 8步 LoRA | 86% | ≈ 55s | ≈ 34s |
| 蒸馏版 fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. 工作流文件
更新 ComfyUI 后你可以从模板中找到工作流文件,或者将下面的工作流拖入 ComfyUI 中加载

蒸馏版
2. 模型下载
你可以在 ComfyOrg 仓库找到的版本
- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- 蒸馏版本 (非官方,仅需 15 步)
所有模型均可在 Huggingface 或者 魔搭 找到
Diffusion model
Qwen_image_distill
LoRA
Text encoder
VAE
模型保存位置
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ ├── qwen_image_fp8_e4m3fn.safetensors
│ │ └── qwen_image_distill_full_fp8_e4m3fn.safetensors ## 蒸馏版
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-8steps-V1.0.safetensors ## 8步加速 LoRA 模型
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors3. 按步骤完成工作流
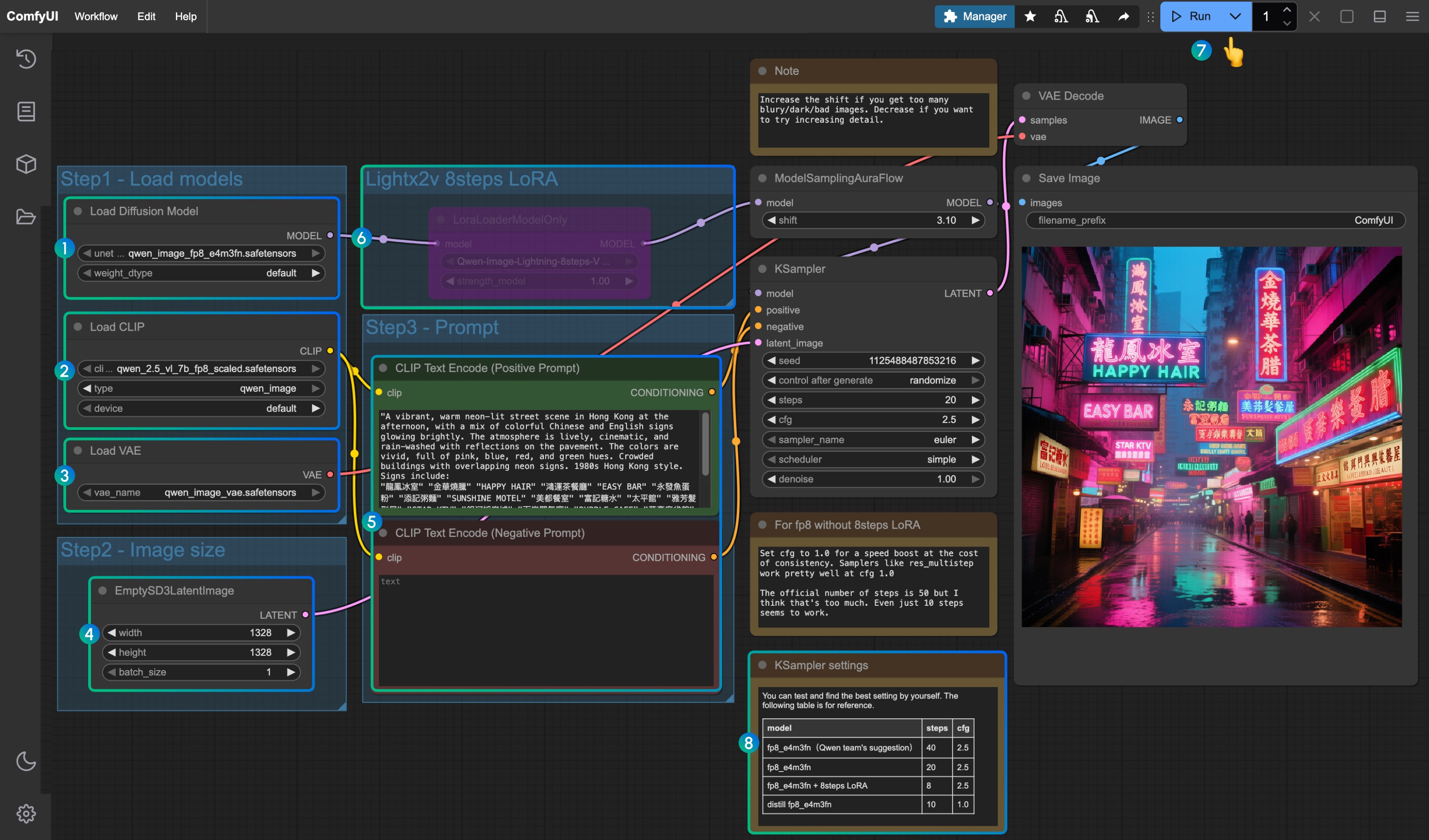
- 确保
Load Diffusion Model节点加载了qwen_image_fp8_e4m3fn.safetensors - 确保
Load CLIP节点中加载了qwen_2.5_vl_7b_fp8_scaled.safetensors - 确保
Load VAE节点中加载了qwen_image_vae.safetensors - 确保
EmptySD3LatentImage节点中设置好了图片的尺寸 - 在
CLIP Text Encoder节点中设置好提示词,目前经过测试目前至少支持:英语、中文、韩语、日语、意大利语等 - 如果需要启用 lightx2v 的 8 步加速 LoRA ,请选中后用
Ctrl + B启用该节点,并按 序号8处的设置参数修改 Ksampler 的设置设置 - 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流 - 对于不同版本的模型和工作流的对应 KSampler 的参数设置
Qwen-Image GGUF 版 ComfyUI 工作流
GGUF 版本对低显存用户来说比较友好,在某些权重情况下你只需要 8GB 左右的显存即可运行 Qwen-Image
显存使用情况参考:
| Workflow | VRAM Usage | 首次生成 | 后续生成 |
|---|---|---|---|
| qwen-image-Q4_K_S.gguf | 56% | ≈ 135s | ≈ 77s |
| With 8steps LoRA | 56% | ≈ 100s | ≈ 45s |
模型地址:Qwen-Image-gguf
1. 更新或者安装自定义节点
使用 GGUF 版本需要你安装或者 更新 ComfyUI-GGUF 这个插件
具体请参考如何安装 ComfyUI 自定义节点,或者通过 Manager 搜索安装即可
2. 工作流下载

3. 模型下载
GGUF 版本使用的模型仅有 diffusion 模型与其它的不同
请访问 https://huggingface.co/city96/Qwen-Image-gguf 下载任意一个权重,通常文件体积越大质量越好,同时也要求更高的显存,在本篇教程中我将使用下面的版本
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen-image-Q4_K_S.gguf # 或者其它你选择的版本3. 按步骤完成 GGUF 工作流
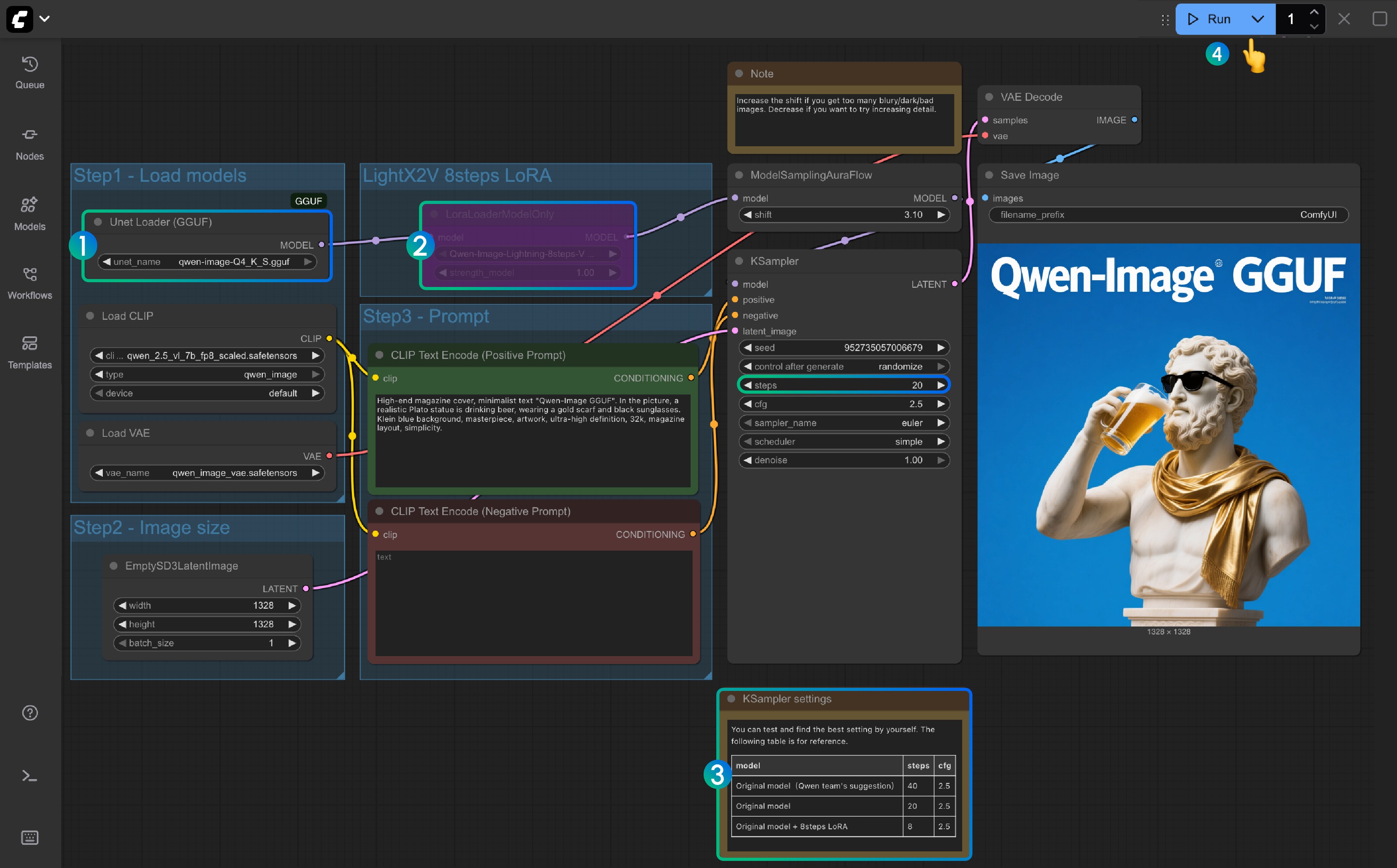
- 确保
Unet Loader(GGUF)节点中加载了qwen-image-Q4_K_S.gguf或者其它你下载的版本- 请确保 ComfyUI-GGUF 已经安装并更新
- 对于
LightX2V 8Steps LoRA默认并未启用,你可以选中后使用 Ctrl+B 启用该节点 - 如果未启用 8 步 LoRA 时,对应的步数默认为 20 , 如果你启用了 8 步 LoRA 请把它设置为 8
- 这里是对应设置步数的参考
- 点击
Queue按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Qwen-Image Nunchaku 版工作流
模型地址:nunchaku-qwen-image 自定义节点地址:https://github.com/nunchaku-tech/ComfyUI-nunchaku
Qwen Image ControlNet
Qwen Image ControlNet DiffSynth-ControlNets Model Patches 工作流
这个模型实际上并不是一个 controlnet,而是一个 Model patch, 支持 canny、depth、inpaint 三种不同的控制模式
原始模型地址:DiffSynth-Studio/Qwen-Image ControlNet Comfy Org rehost 地址: Qwen-Image-DiffSynth-ControlNets/model_patches
1. 工作流及输入图片
下载下面的图片拖入 ComfyUI 中以加载对应的工作流

下载下面的图片作为输入图片:

2. 模型链接
其它模型与 Qwen-Image 基础工作流一致,你只需下载下面的模型并保存到 ComfyUI/models/model_patches 文件夹中
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. 工作流使用说明
目前 diffsynth 有三个 patch 的模型: Canny、Detph、Inpaint 三个模型
如果你是第一次使用 ControlNet 相关的工作流,你需要了解的是,用于控制的图片需要预处理成受支持的图像才可以被模型使用和识别

- Canny: 处理后的 canny , 线稿轮廓
- Detph: 预处理后的深度图,体现空间关系
- Inpaint: 需要用 Mask 标记需要重绘的部分
由于这个 patch 模型分为了三个不同的模型,所以你需要在输入时选择正确的预处理类型来保证图像的正确预处理
Canny 模型 ControlNet 使用说明
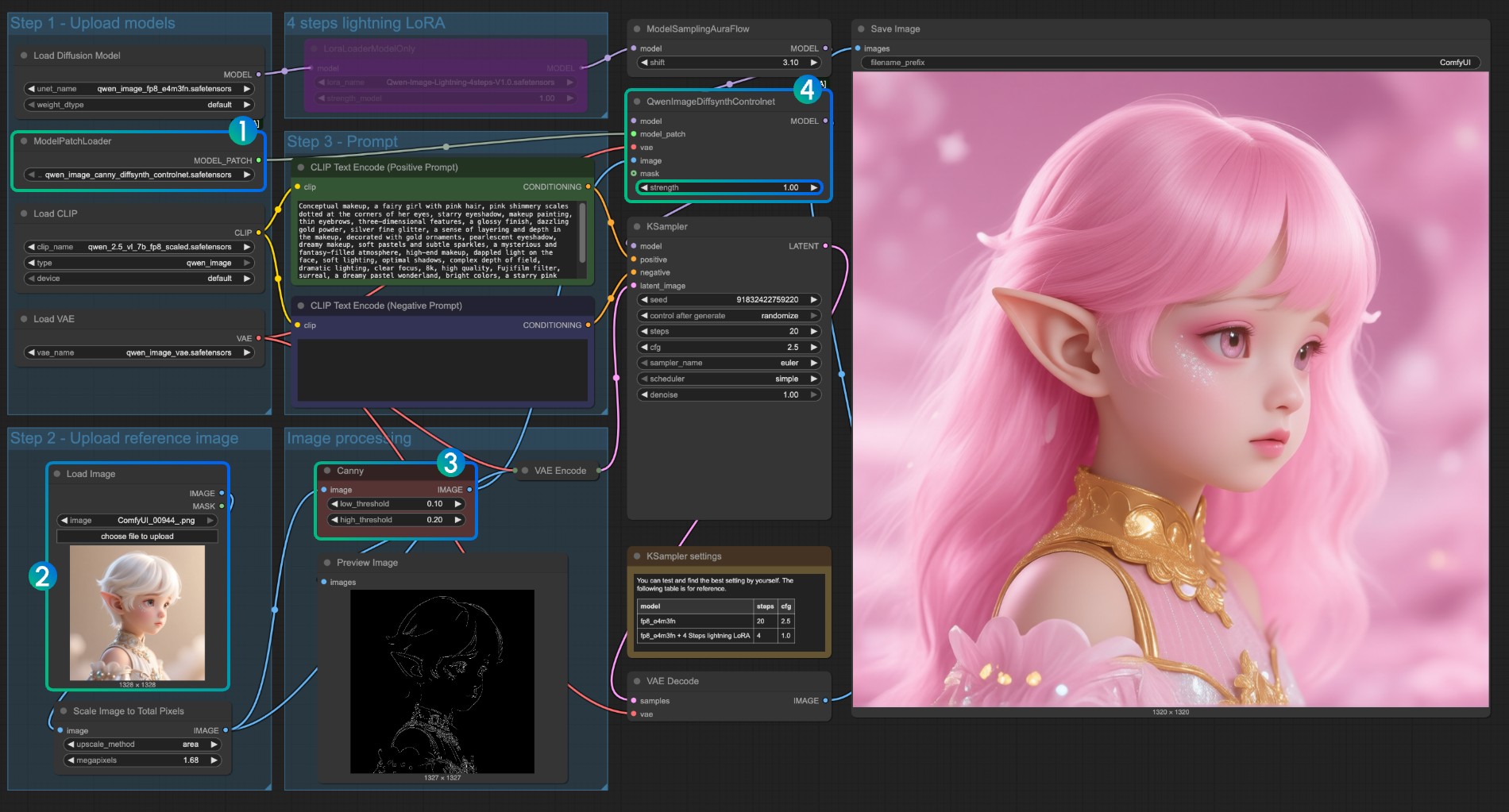
- 确保对应
qwen_image_canny_diffsynth_controlnet.safetensors已被加载 - 上传输入图片,用于后续处理
- Canny 节点是原生的预处理节点,它将按照你设置的参数,将输入图像进行预处理,控制生成
- 如果需要可以修改
QwenImageDiffsynthControlnet节点的strength强度来控制线稿控制的强度 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
对于 qwen_image_depth_diffsynth_controlnet.safetensors 使用,需要将图像预处理成 detph 深度图,替换掉
image proccessing图,对于这部分的使用,请参考本篇文档中 InstantX 的处理方法,其它部分与 Canny 模型的使用类似
Inpaint 模型 ControlNet 使用说明
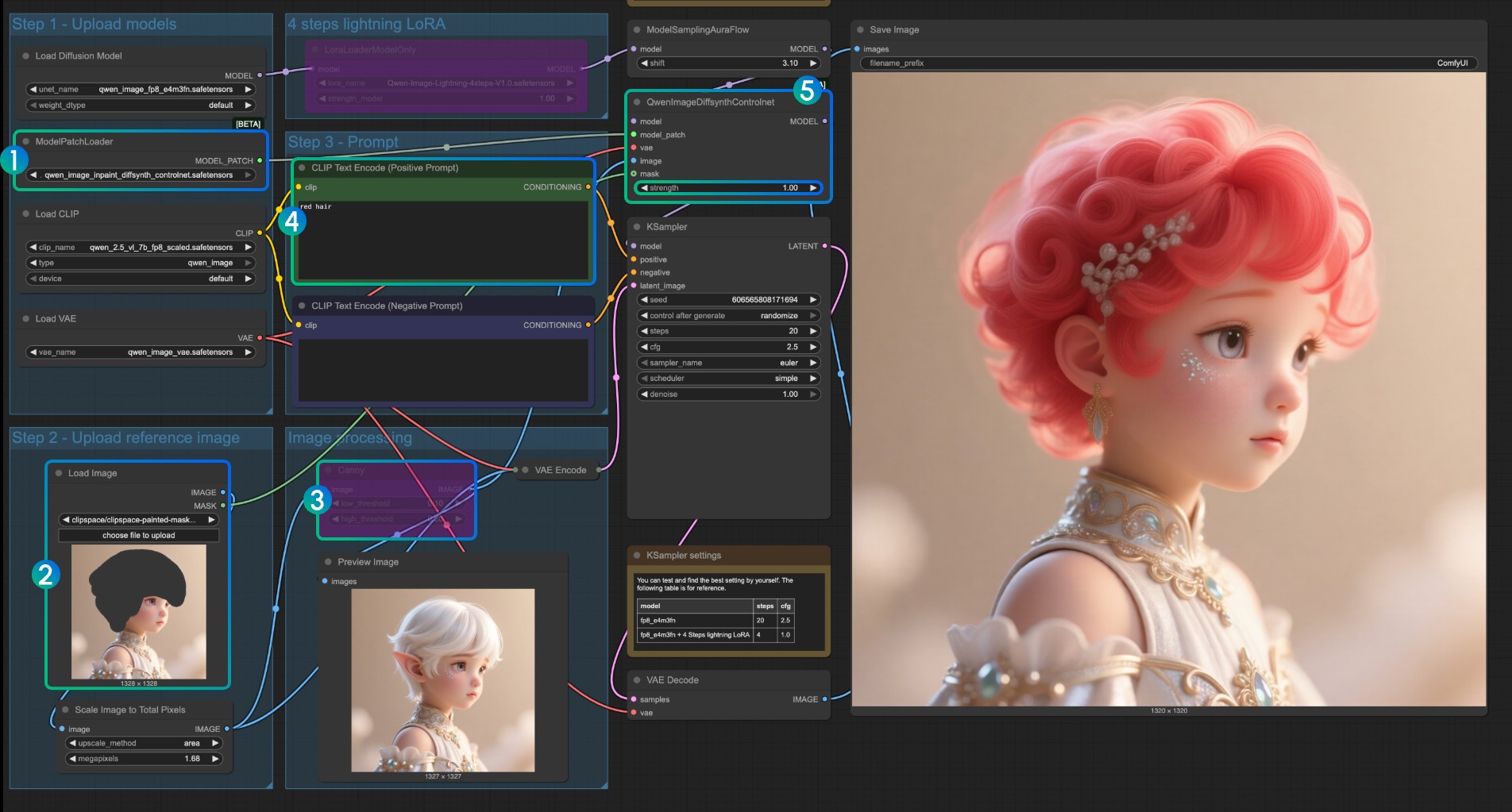
对于 Inpaint 模型,它需要使用 蒙版编辑器,来绘制一个蒙版然后作为输入控制条件
- 确保
ModelPatchLoader加载的是qwen_image_inpaint_diffsynth_controlnet.safetensors模型 - 上传图片,并使用蒙版编辑器 绘制蒙版,你需要将对应
Load Image节点的mask输出连接到QwenImageDiffsynthControlnet的mask输入才能保证对应的蒙版被加载 - 使用
Ctrl-B快捷键,将原本工作流中的 Canny 设置为绕过模式,来使得对应的 Canny 节点处理不生效 - 在
CLIP Text Encoder输入你需要将蒙版部分修改成样式 - 如需要可以修改
QwenImageDiffsynthControlnet节点的strength强度来控制对应的控制强度 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
Qwen Image union ControlNet LoRA 工作流
原始模型地址:DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Comfy Org reshot 地址: qwen_image_union_diffsynth_lora.safetensors: 图像结构控制lora 支持 canny、depth、post、lineart、softedge、normal、openpose
1. 工作流及输入图片
下载下面的图片并拖入 ComfyUI 以加载工作流

下载下面的图片作为输入图片

2. 模型链接
下载下面的模型,由于这是一个 LoRA 模型,所以需要保存到 ComfyUI/models/loras/ 文件夹下
- qwen_image_union_diffsynth_lora.safetensors: 图像结构控制lora 支持 canny、depth、post、lineart、softedge、normal、openpose
3. 工作流说明
这个模型是一个统一的控制 LoRA, 支持 canny、depth、pose、lineart、softedge、normal、openpose 等控制, 由于许多的图像预处理原生节点并未完全支持,所以你应该需要类似 comfyui_controlnet_aux 来完成其它图像的预处理
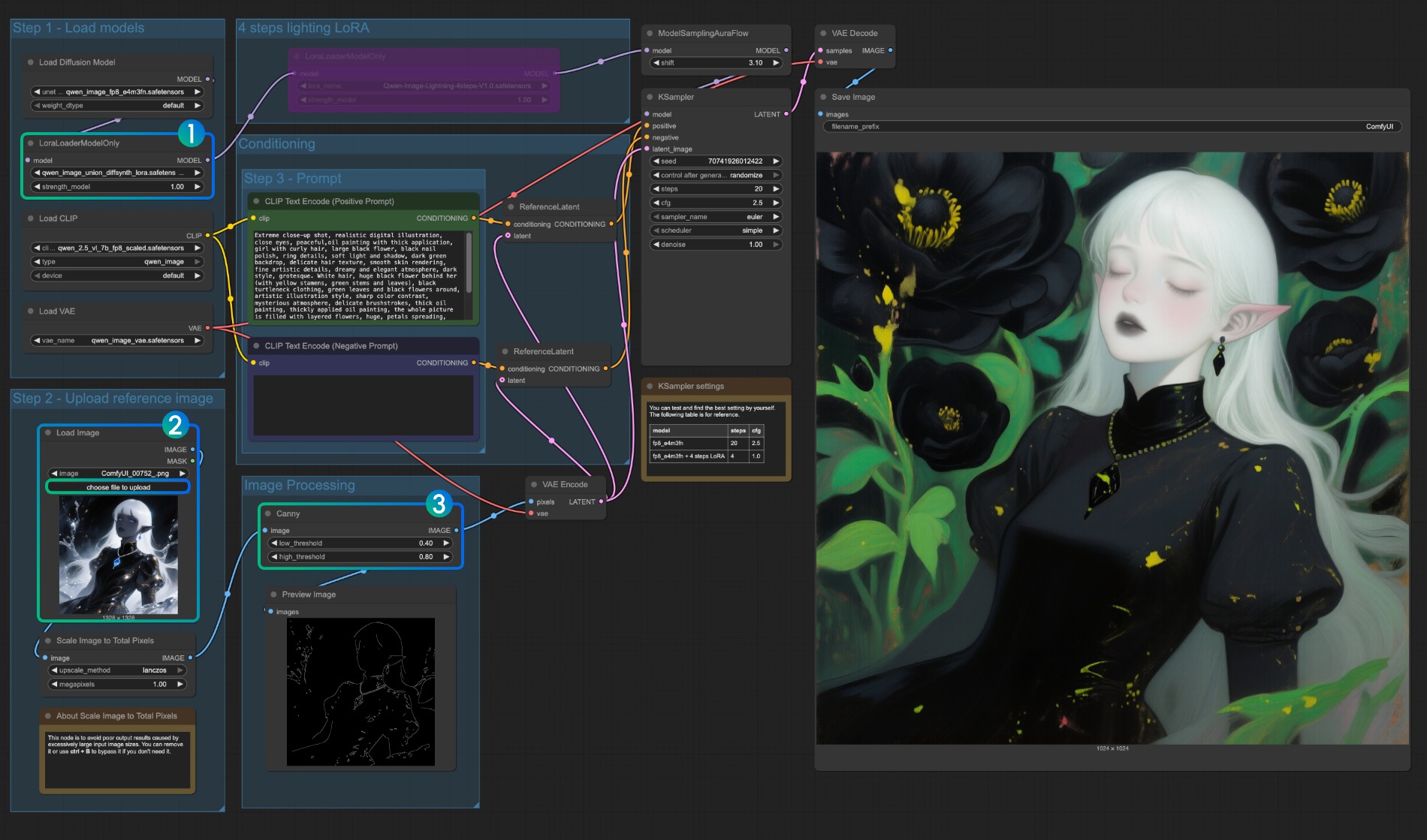
- 确保
LoraLoaderModelOnly正确加载了qwen_image_union_diffsynth_lora.safetensors模型 - 上传输入图像
- 如需要你可以调整
Canny节点的参数,由于不同的输入图像需要不同的参数设置来获得更好的图像预处理结果,你可以尝试调整对应的参数值来获得更多/更少细节 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来运行工作流
其它类型的类型的控制,也是需要将图像处理的部分替换
评论
使用 GitHub 登录后即可参与讨论。