OpenMOSS 发布 MOVA - 开源音视频同步生成模型
2026/01/29
通义 Wan2.1 ComfyUI 工作流
阿里巴巴于2025年2月开源的Wan2.1是当前视频生成领域的标杆性模型,其开源协议为Apache 2.0,提供14B(140亿参数)和1.3B(13亿参数)两个版本,覆盖文生视频(T2V)、图生视频(I2V)等多项任务。 该模型不仅在性能上超越现有开源模型,更重要的是其轻量级版本仅需 8GB 显存即可运行,大大降低了使用门槛。
另外目前已有社区作者制作了 GGUF 和量化版本
- GGUF: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
- 量化版本: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
本文将带领你完成对应的 Wan2.1 相关工作流包括:
- ComfyUI 原生支持的 Wan2.1 工作流
- 来自 Kijai 的版本
- 来自 City96 的 GGUF 版本
本教程中用所有的工作流文件,都已经包含对应的工作流信息,可直接拖入 ComfyUI 加载对应的工作流及模型信息,在弹窗后点击下载对应模型即可,如果无法完成对应模型下载,请参考手动安装部分完成模型安装,所有输出视频将会输出至 ComfyUI/output 目录下
由于 Wan2.1 将 480P 和 720P 的模型分开,但是对应工作流除了模型和画布尺寸,其它工作流并没有差异,你可以根据对应的 720P 或者 480P 工作流进行调整另一版本工作流
Wan2.1 ComfyUI 原生(native)工作流示例
以下工作流来自 ComfyUI 官方博客,目前 ComfyUI 已原生支持 Wan2.1,使用官方原生支持版本请升级你的 ComfyUI 到最新版本,请参考 如何升级 ComfyUI 部分指南完成升级。 ComfyUI Wiki 对原始的工作流进行了整理。
更新 ComfyUI 到最新版本之后 在 菜单栏 Workflows -> Workflow Templates 中可以看到 Wan2.1 的工作流模板
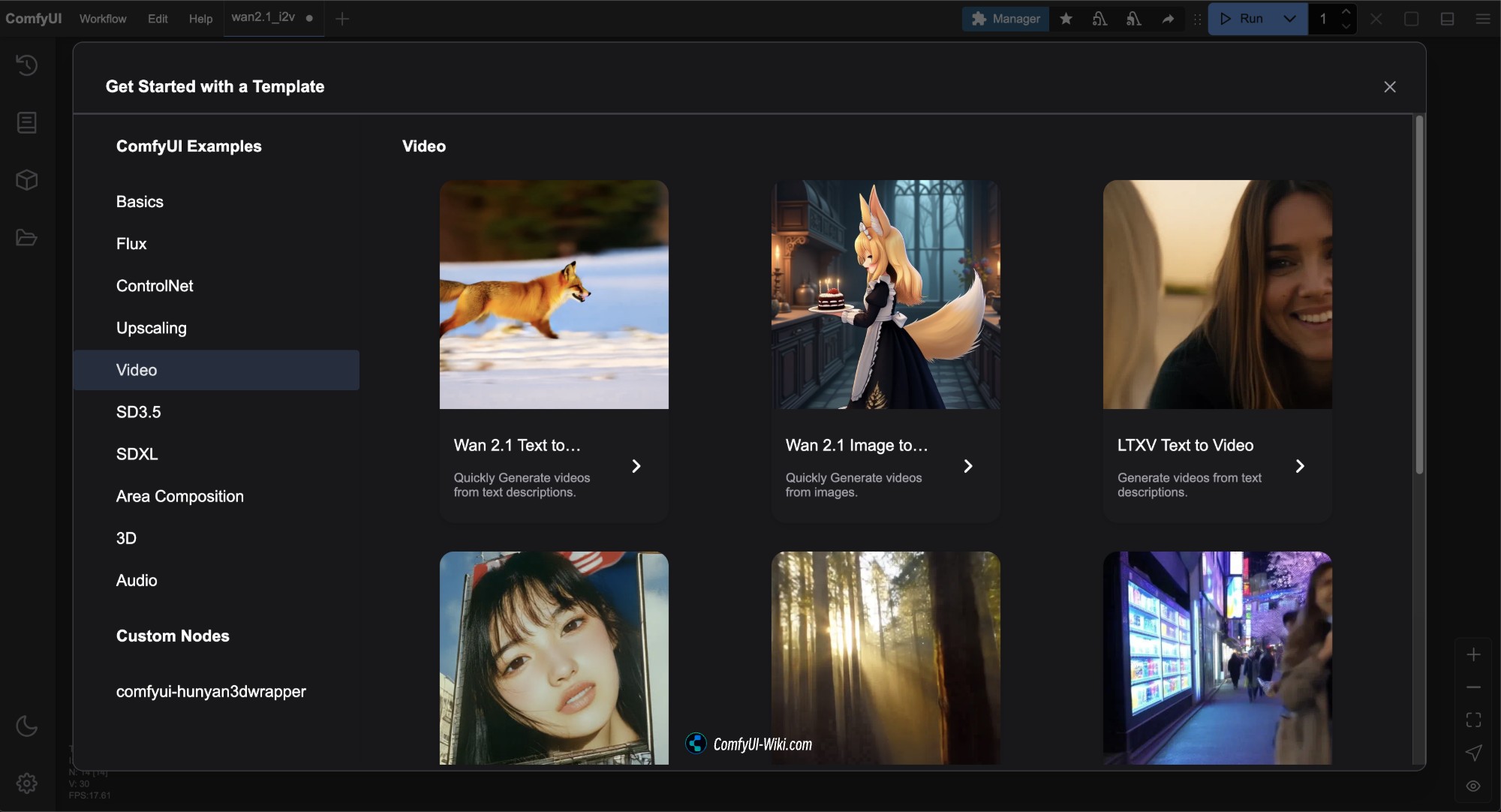
此版本的对应工作流文件全部来自于 Comfy-Org/Wan_2.1_ComfyUI_repackaged
其中 Diffusion models Comfy-org 提供了多个版本,如果本文中官方原生版本所用模型版本对硬件要求较高,你可以选择自己需要的版本来进行使用
- i2v 为 image to video 即 图生视频模型, t2v 为 text to video 即 文生视频模型
- 14B、1.3B 为对应的参数量,数值越大对硬件性能要求越高
- bf16、fp16、fp8 代表不同的精度,精度越高对硬件性能要求越高
- 其中bf16 可能需要Ampere 架构及以上的 GPU 支持
- fp16 受支持更广泛
- fp8 精度最低,对硬件性能要求最低,但效果相对也会较差
- 通常文件体积越大对设备的硬件要求也越高
1. Wan2.1 文生视频工作流
1.1 Wan2.1 文生视频工作流文件下载
下载下面的图片,并拖入 ComfyUI 或使用菜单栏 Workflows -> Open(Ctrl+O) 打开以加载工作流

Json 格式文件下载
1.2 手动模型安装
如果上面的工作流文件无法完成模型下载,请下载下面的模型文件,并保存到对应的位置。
不同类型模型有多个文件的,请下载一个即可,ComfyUI Wiki 已经按照对 GPU 性能要求顺序由高到低排序了。你可以访问这里查看所有模型文件。
从下面选择一个Diffusion models 模型文件进行下载,
- wan2.1_t2v_14B_bf16.safetensors
- wan2.1_t2v_14B_fp16.safetensors
- wan2.1_t2v_14B_fp8_e4m3fn.safetensors
- wan2.1_t2v_14B_fp8_scaled.safetensors
- wan2.1_t2v_1.3B_bf16.safetensors
- wan2.1_t2v_1.3B_fp16.safetensors
从Text encoders 选择一个版本进行下载,
VAE
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_t2v_14B_fp16.safetensors # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 按流程完成工作流运行
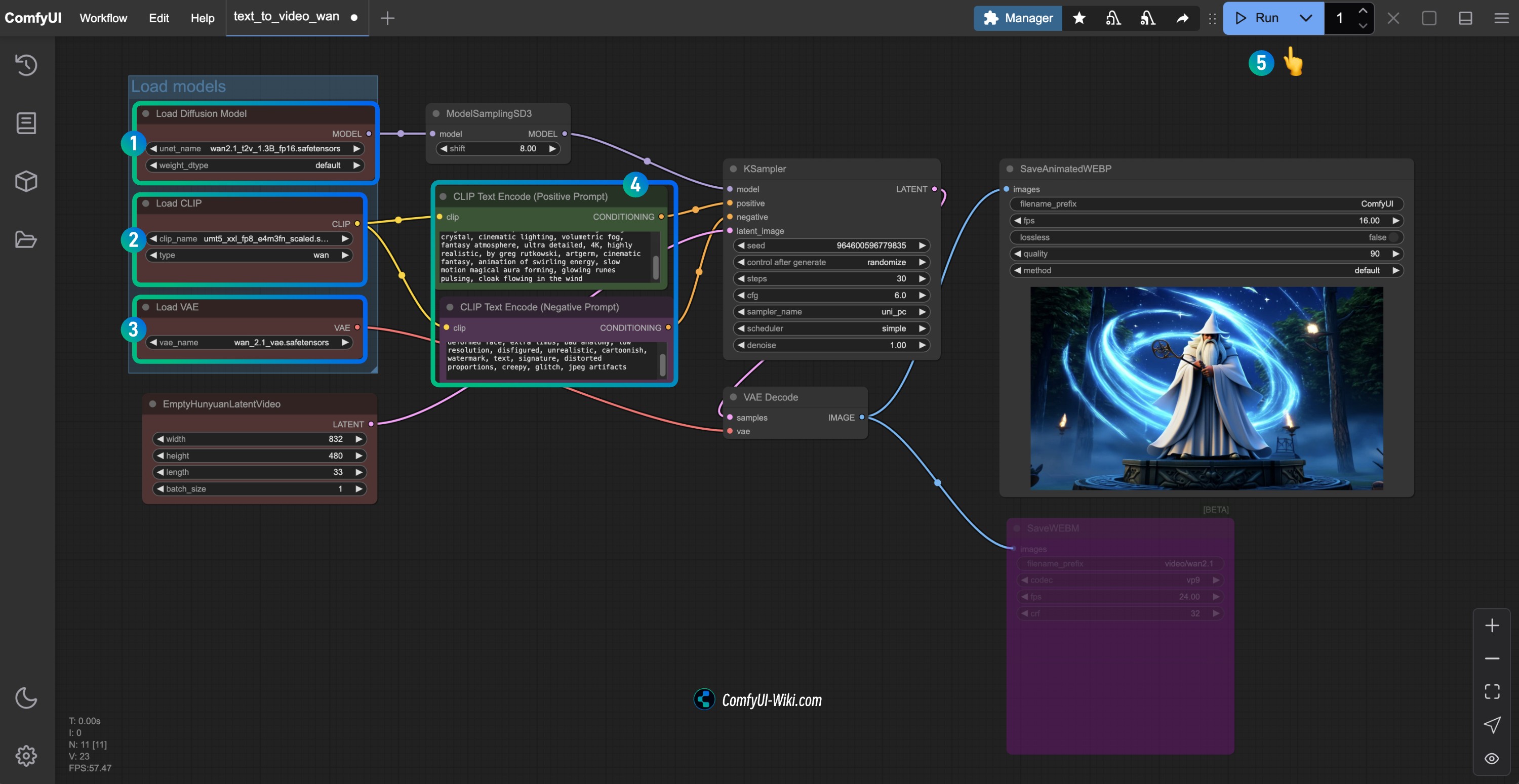
- 确保
Load Diffusion Model节点加载了wan2.1_t2v_1.3B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 可以在
CLIP Text Encoder节点中输入你想要生成的视频描述内容 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2. Wan2.1 图生视频工作流
2.1 Wan2.1 图生视频工作流 14B Workflow
工作流文件下载
请点击下面的按钮下载对应的工作流,然后拖入 ComfyUI 界面或者使用菜单栏 Workflows -> Open(Ctrl+O) 进行加载

Json 格式文件下载
这个版本的工作流和 480P 版本基本一致,只是使用的 diffusion model 不同,和 WanImageToVideo 节点的尺寸不同
下载下面的图片作为输入图片

2.2 手动模型下载
如果上面的工作流文件无法完成模型下载,请下载下面的模型文件,并保存到对应的位置
Diffusion models
720P 版本
- wan2.1_i2v_720p_14B_bf16.safetensors
- wan2.1_i2v_720p_14B_fp16.safetensors
- wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_720p_14B_fp8_scaled.safetensors
480P 版本
- wan2.1_i2v_480p_14B_bf16.safetensors
- wan2.1_i2v_480p_14B_fp16.safetensors
- wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_480p_14B_fp8_scaled.safetensors
Text encoders
VAE
CLIP Vision
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_i2v_480p_14B_fp16.safetensors # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── vae/
│ │ └── wan_2.1_vae.safetensors
│ └── clip_vision/
│ └── clip_vision_h.safetensors 2.3 按流程完成 Wan2.1 480P 图生视频工作流
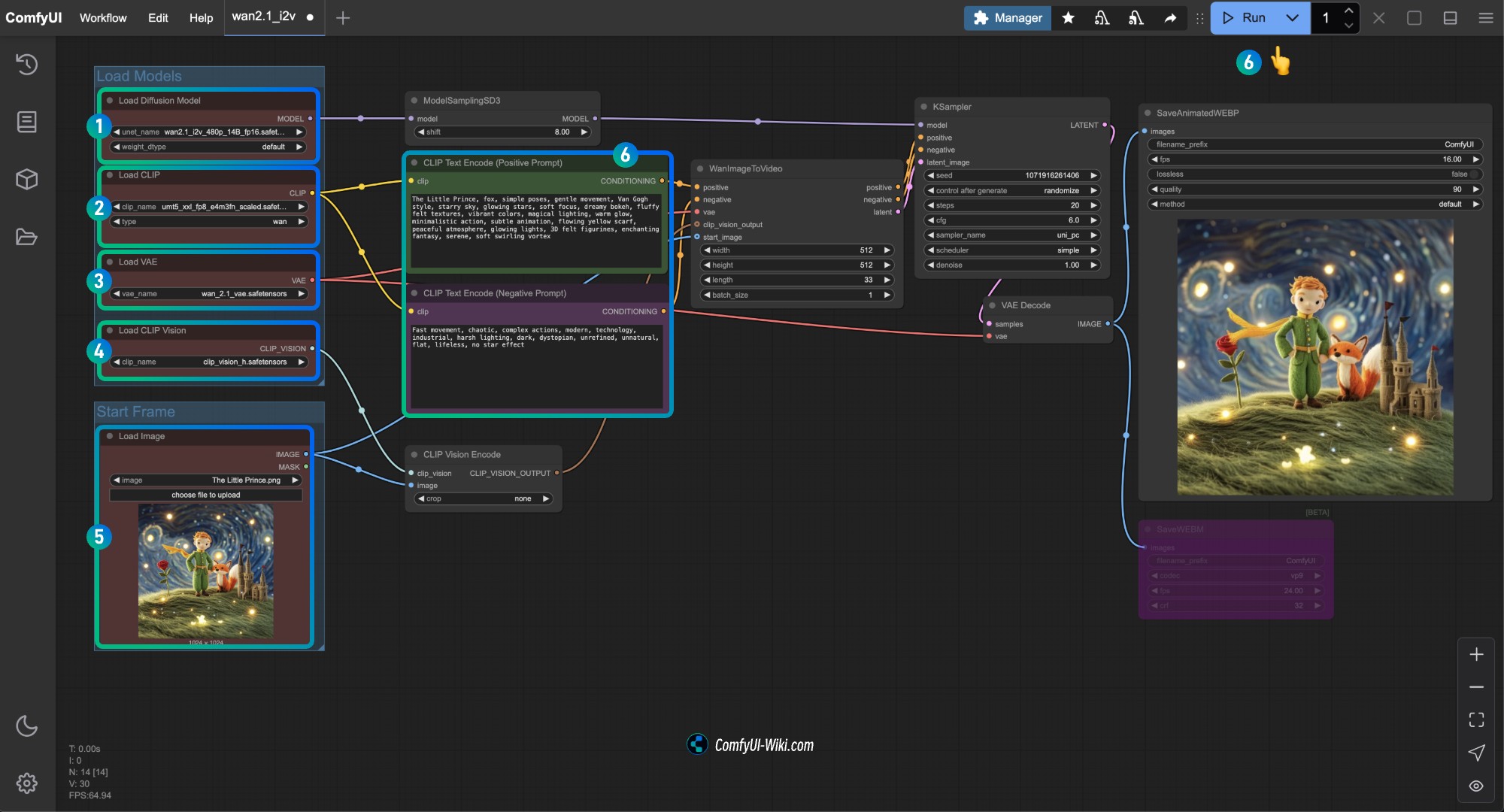
- 确保
Load Diffusion Model节点加载了wan2.1_i2v_480p_14B_fp16.safetensors模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载前面提供的输入图片 - 在
CLIP Text Encoder节点中输入你想要生成的视频描述内容,或者使用工作流中的示例 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Kijai Wan2.1 量化版本工作流
这个版本由 Kijai 提供,需要配合以下自定义节点使用
需要安装下面三个节点:
请在开始前使用 ComfyUI-Manager 或者参考ComfyUI 自定义节点安装教程完成对应这三个自定义节点的安装
模型仓库:Kijai/WanVideo_comfy
该仓库提供了多种不同版本的模型,请按照你的设备性能选择合适的模型,通常体积越大,效果越好,但同时对设备性能要求也越高。
如果 ComfyUI 原生工作流在你的设备上运行良好,你也可以使用Comfy Org 提供的模型,在示例中,我将使用 Kijai 提供模型来完成示例
1. Kijai 文生图工作流
1.1 Kijai Wan2.1 文生图工作流下载
请点击下面的按钮下载对应的工作流,请点击下面的按钮下载对应的工作流,然后拖入 ComfyUI 界面或者使用菜单栏 Workflows -> Open(Ctrl+O) 进行加载
以上两个工作流文件基本相同,2 号文件多了可选的备注信息
1.2 手动模型安装
访问: https://huggingface.co/Kijai/WanVideo_comfy/tree/main 查看文件体积大小,通常文件体积越大,效果越好,但同时对设备性能要求也越高
Diffusion models
- Wan2_1-T2V-14B_fp8_e4m3fn.safetensors
- Wan2_1-T2V-14B_fp8_e5m2.safetensors
- Wan2_1-T2V-1_3B_fp32.safetensors
- Wan2_1-T2V-1_3B_bf16.safetensors
- Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors
Text encoders模型
VAE模型
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-T2V-14B_fp8_e4m3fn.safetensors # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 或者你选择的版本
│ └─── vae/
│ └── Wan2_1_VAE_bf16.safetensors1.3 按步骤完成工作流的运行
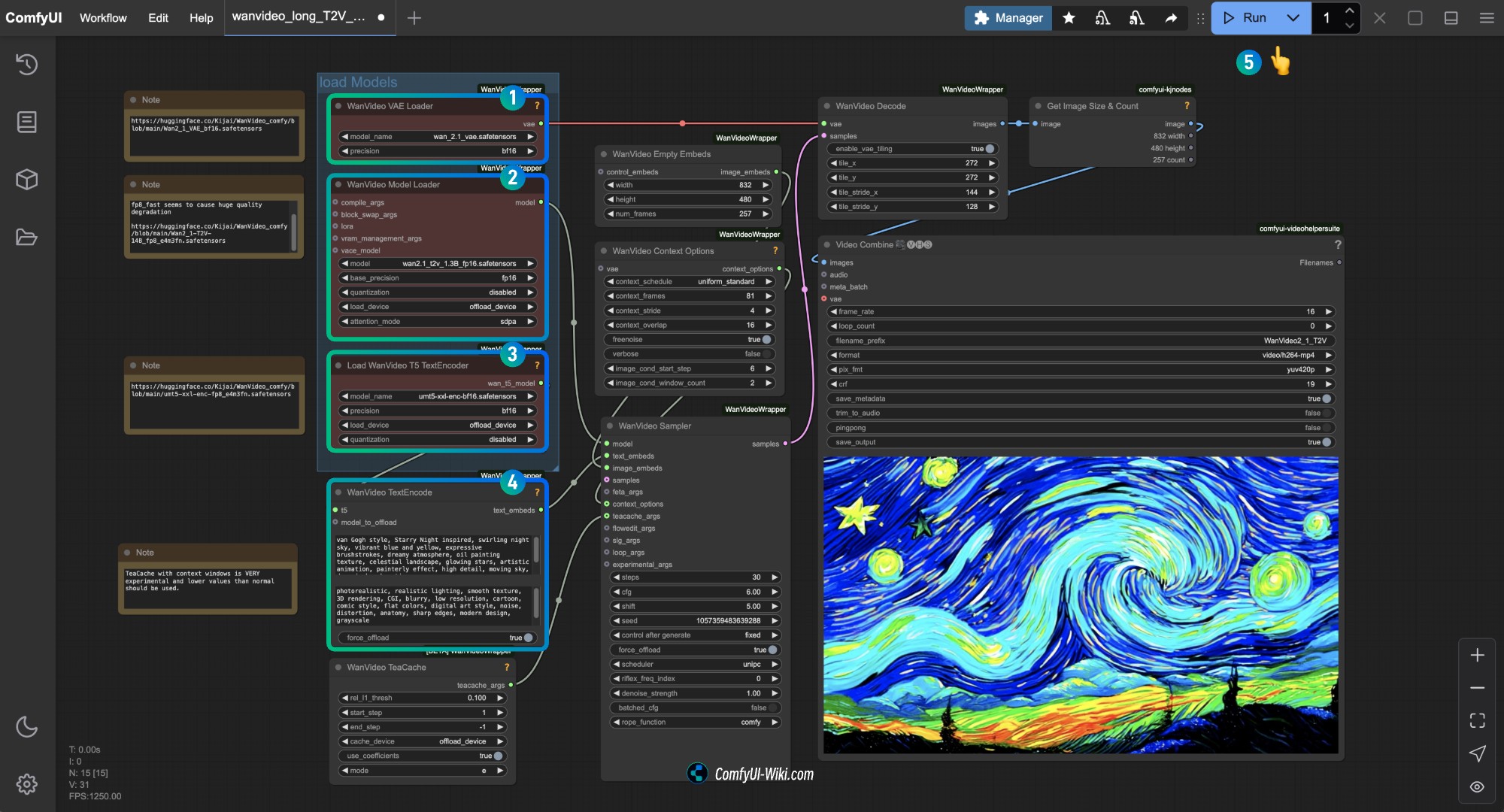
确保对应节点加载了对应模型,使用你下载的版本即可
- 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_bf16.safetensors模型 - 确保
WanVideo Model Loader节点加载了Wan2_1-T2V-14B_fp8_e4m3fn.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 在
WanVideo TextEncode处输入你想要生成的视频画面提示词 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
可以修改 WanVideo Empty Embeds 中的尺寸来修改画面尺寸
2. Kiai Wan2.1 图生视频工作流
2.1 工作流文件下载
下载下面的图片我们将作输入图片

2.2 手动模型下载
使用 ComfyUI Native 部分的示例的模型也是可以的,似乎仅有 text_encoder 无法使用
Diffusion models 720P 版本
480P 版本
Text encoders模型
VAE模型
CLIP Vision
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # 或者你选择的版本
│ ├── vae/
│ │ └── Wan2_1_VAE_fp32.safetensors # 或者你选择的版本
│ └── clip_vision/
│ └── clip_vision_h.safetensors 2.3 按步骤完成工作流的运行
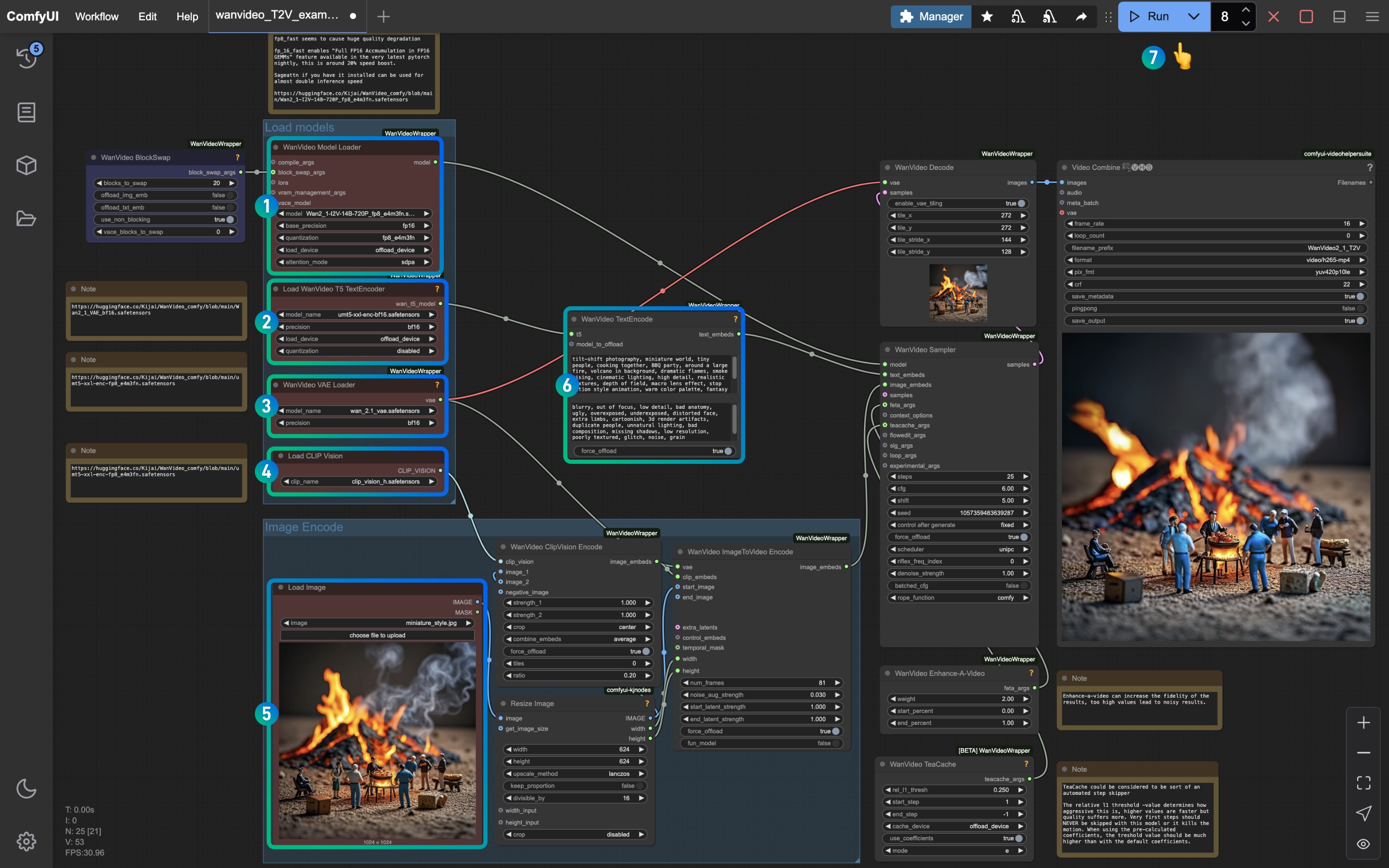
请参考图片序号,确保对应节点和模型均已加载来完成来确保模型能够正常运行
- 确保
WanVideo Model Loader节点加载了Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors模型 - 确保
Load WanVideo T5 TextEncoder节点加载了umt5-xxl-enc-bf16.safetensors模型 - 确保
WanVideo Vae Loader节点加载了Wan2_1_VAE_fp32.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载我们前面提供的输入图片 - 保存默认或者修改
WanVideo TextEncode提示词来调整画面效果 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
Wan2.1 GGUF 版本工作流
这个部分我们将使用 GGUF 版本模型来完成视频生成 模型仓库:https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
我们需要 ComfyUI-GGUF 来加载对应模型,请在开始前使用 ComfyUI-Manager 或者参考ComfyUI 自定义节点安装教程完成对应自定义节点的安装
这个版本工作流基本与 ComfyUI Native 版本工作流一致,只不过我们使用了 GGUF 版本和对应 GGUF模型加载来完成视频生成,我仍旧会在这个部分提供完整的模型列表,防止有些用户直接查看这个部分的示例。
1. Wan2.1 GGUF 版本文生视频工作流
1.1 工作流文件下载

1.2 手动模型下载
从下面选择一个Diffusion models 模型文件进行下载, city96 提供了多种不同版本的模型,请访问 https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main 下载一个合适你的版本,通常体积越大,效果越好,但同时对设备性能要求也越高
从Text encoders 选择一个版本进行下载,
VAE
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-t2v-14b-Q4_K_M.gguf # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 按步骤完成工作流的运行
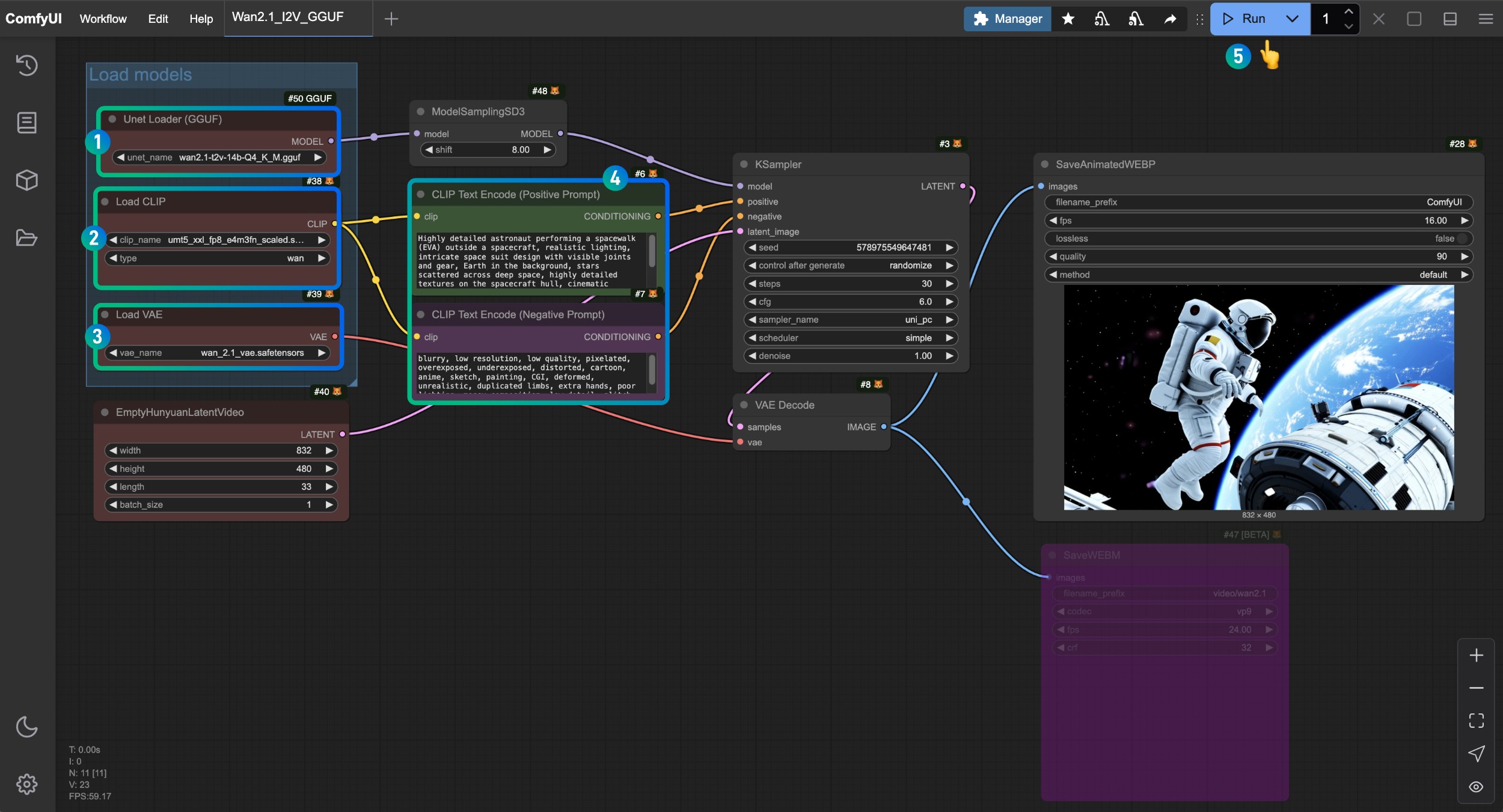
- 确保
Unet Loader(GGUF)节点加载了wan2.1-t2v-14b-Q4_K_M.gguf模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 可以在
CLIP Text Encoder节点中输入你想要生成的视频描述内容 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
2. Wan2.1 GGUF 版本图生视频工作流
2.1 工作流文件下载

2.2 手动模型下载
从下面选择一个Diffusion models 模型文件进行下载, city96 提供了多种不同版本的模型,请访问对应仓库下载适合你的版本,通常体积越大,效果越好,但同时对设备性能要求也越高
在这里我使用 wan2.1-i2v-14b-Q4_K_M.gguf 模型来完成示例
从Text encoders 选择一个版本进行下载,
VAE
文件保存位置
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-i2v-14b-Q4_K_M.gguf # 或者你选择的版本
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # 或者你选择的版本
│ └── vae/
│ └── wan_2.1_vae.safetensors2.3 按步骤完成工作流的运行
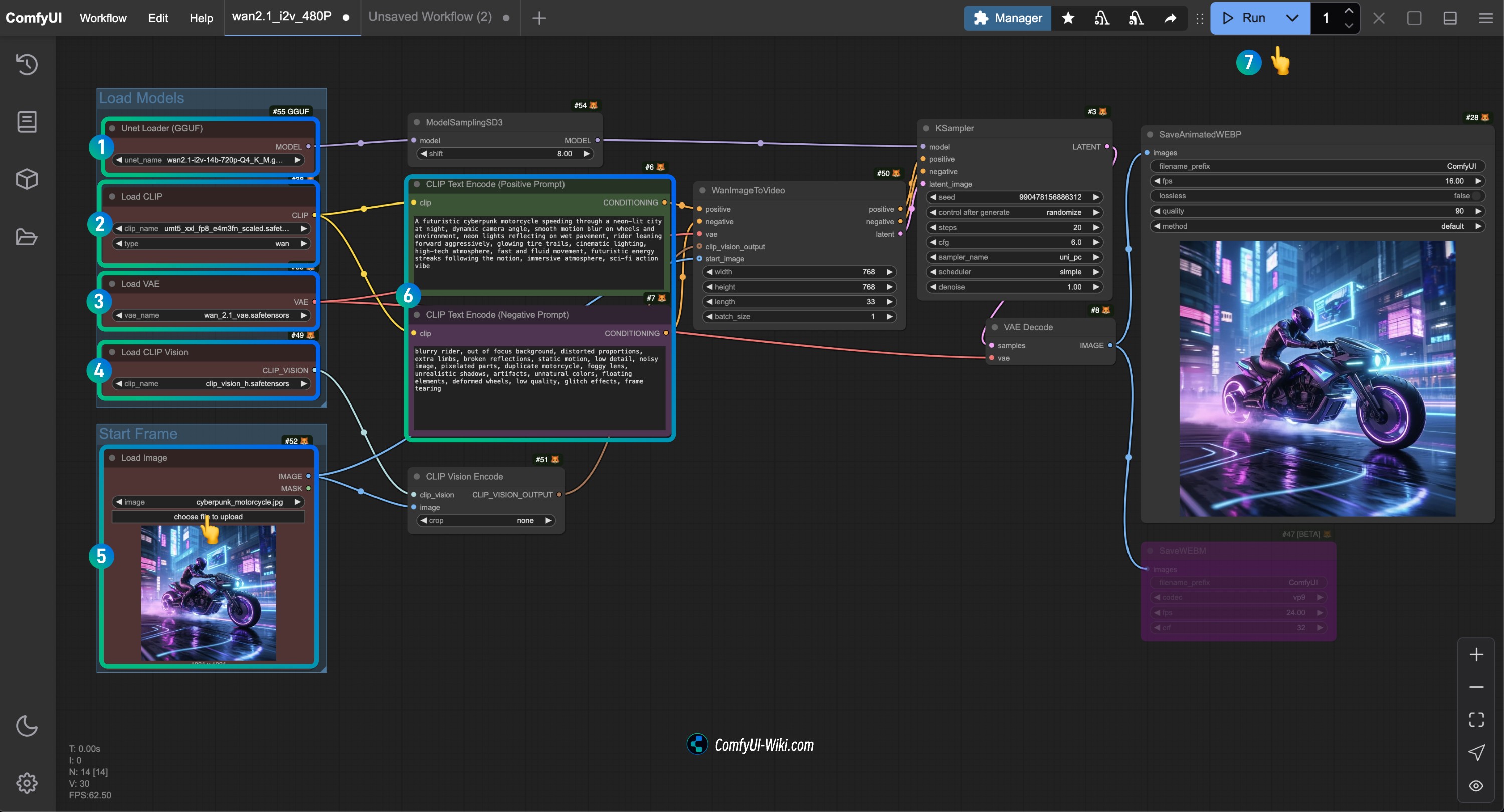
- 确保
Unet Loader(GGUF)节点加载了wan2.1-i2v-14b-Q4_K_M.gguf模型 - 确保
Load CLIP节点加载了umt5_xxl_fp8_e4m3fn_scaled.safetensors模型 - 确保
Load VAE节点加载了wan_2.1_vae.safetensors模型 - 确保
Load CLIP Vision节点加载了clip_vision_h.safetensors模型 - 在
Load Image节点中加载前面提供的输入图片 - 在
CLIP Text Encoder节点中输入你想要生成的视频描述内容,或者使用工作流中的示例 - 点击
Run按钮,或者使用快捷键Ctrl(cmd) + Enter(回车)来执行视频生成
常见问题
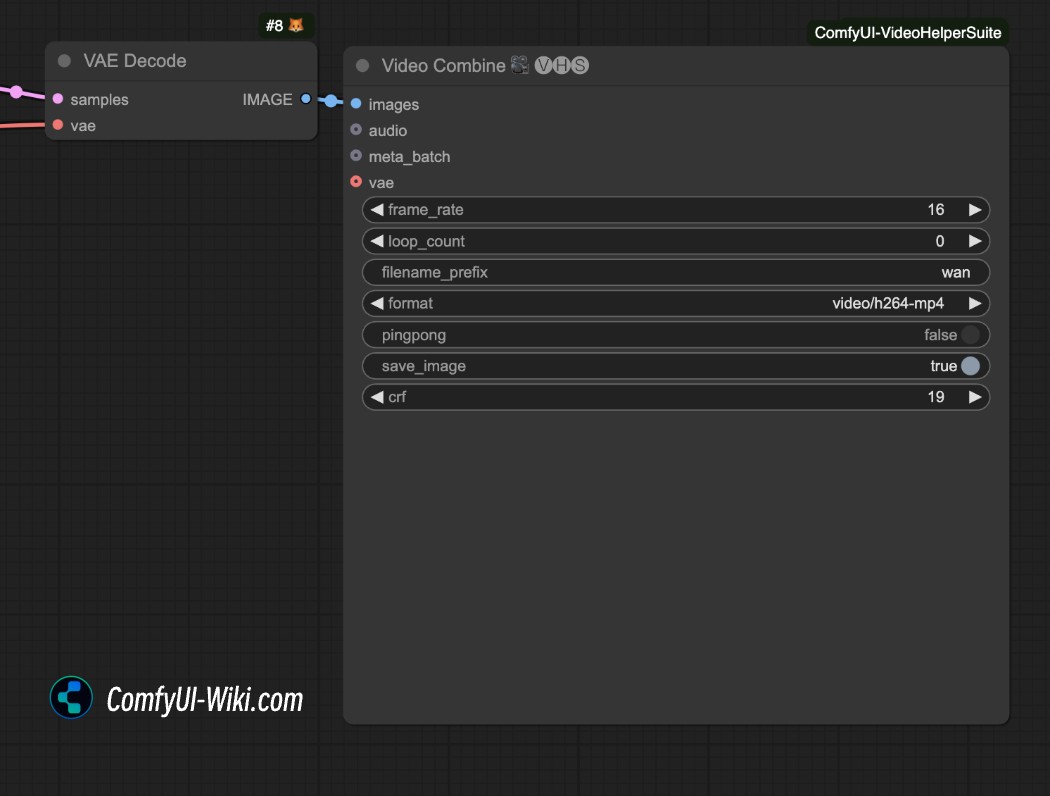
如何保存为 mp4 格式视频
上面的视频生成工作流默认生成的为 .webp 格式视频,如果想要保存为其它格式视频,可以尝试使用 ComfyUI-VideoHelperSuite 插件中的 video Combine 节点来保存为 mp4 格式视频
相关资源
目前所有模型已在 Hugging Face 和 ModelScope 平台开放下载:
-
T2V-14B:Hugging Face | ModelScope
-
I2V-14B-720P:Hugging Face | ModelScope
-
T2V-1.3B:Hugging Face | ModelScope