Guía Completa del Flujo de Trabajo de HunyuanVideo Image-to-Video con GGUF, FP8 y ComfyUI Native (Incluye Ejemplos)
Un tutorial completo sobre cómo utilizar el modelo HunyuanVideo de Tencent en ComfyUI para la generación de vídeo a partir de imágenes, incluyendo configuración del entorno, instalación de modelos e instrucciones de flujo de trabajo
Tencent lanzó oficialmente el modelo de imagen a vídeo HunyuanVideo el 6 de marzo de 2025. El modelo ahora es de código abierto y se puede encontrar en HunyuanVideo-I2V.
A continuación se muestra el diagrama de arquitectura general de HunyuanVideo:
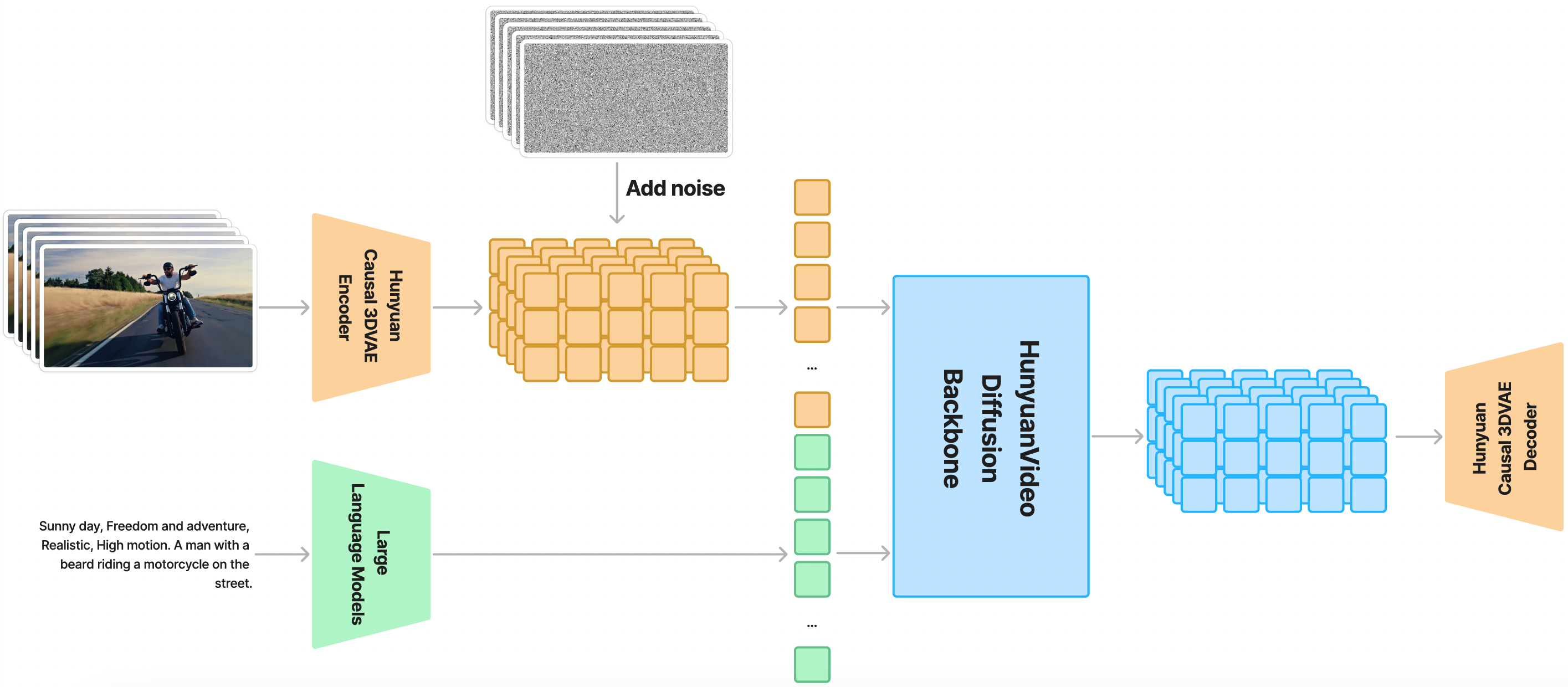
ComfyUI ahora soporta de forma nativa el modelo HunyuanVideo-I2V, y los desarrolladores de la comunidad kijai y city96 han actualizado sus nodos personalizados para soportar el modelo HunyuanVideo-I2V.
Además del modelo oficial de Tencent, aquí hay otras versiones recopiladas por ComfyUI Wiki:
- Versión oficial reempaquetada de ComfyUI (no requiere plugin): Comfy-Org/HunyuanVideo_repackaged
- Versión de Kijai (requiere ComfyUI-HunyuanVideoWrapper): Kijai/HunyuanVideo_comfy
- Versión empaquetada de city96 (requiere ComfyUI-GGUF): city96/HunyuanVideo-I2V-gguf
En este artículo, proporcionaremos instrucciones completas de instalación de modelos y ejemplos de flujo de trabajo para cada una de estas versiones.
Este artículo se centra en los flujos de trabajo de imagen a vídeo. Si desea conocer el flujo de trabajo de texto a vídeo de Tencent Hunyuan, consulte Guía y ejemplos del flujo de trabajo de texto a vídeo de Tencent Hunyuan.
Flujo de trabajo oficial de ComfyUI para HunyuanVideo I2V
Este flujo de trabajo proviene de la documentación oficial de ComfyUI.
Antes de comenzar este tutorial, consulte Cómo actualizar ComfyUI para actualizar su ComfyUI a la versión más reciente y evitar que falten los siguientes nodos de Comfy_Core para HunyuanVideo:
- HunyuanImageToVideo
- TextEncodeHunyuanVideo_ImageToVideo
1. Archivo de flujo de trabajo HunyuanVideo I2V
Descargue el archivo de flujo de trabajo a continuación, luego arrástrelo a ComfyUI, o use el menú Workflows -> Open (ctrl+o) para cargar el flujo de trabajo.

Descarga del flujo de trabajo en formato JSON
2. Descargas de modelos HunyuanVideo I2V
Los siguientes modelos son de Comfy-Org/HunyuanVideo_repackaged. Por favor, descargue estos modelos:
- llava_llama3_vision.safetensors
- clip_l.safetensors
- llava_llama3_fp16.safetensors
- llava_llama3_fp8_scaled.safetensors
- hunyuan_video_vae_bf16.safetensors
- hunyuan_video_image_to_video_720p_bf16.safetensors
Después de descargar, organice los archivos según la estructura a continuación y guárdelos en las carpetas correspondientes bajo ComfyUI/models:
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_image_to_video_720p_bf16.safetensors3. Imagen de entrada
Descargue la siguiente imagen como imagen de entrada

Complete la verificación de cada nodo del flujo de trabajo HunyuanVideo I2V
Consulte la imagen para completar la verificación del contenido de cada nodo y asegurar que el flujo de trabajo funcione correctamente
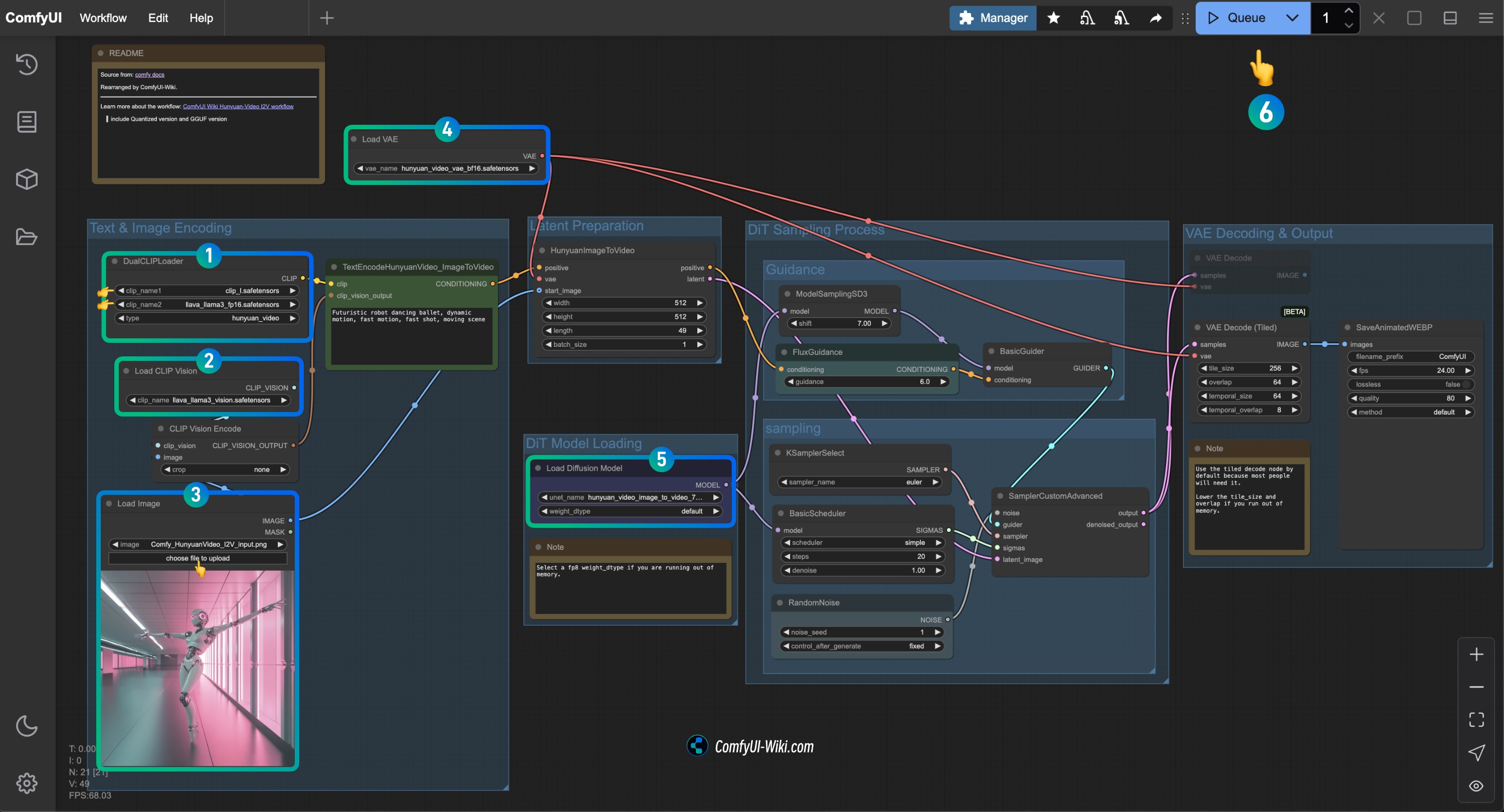
- Verifique el nodo
DualCLIPLoader:
- Asegúrese de que
clip_name1: clip_l.safetensors esté cargado correctamente - Asegúrese de que
clip_name2: llava_llama3_vision.safetensors esté cargado correctamente
- Verifique el nodo
Load CLIP Vision: Asegúrese de que llava_llama3_vision.safetensors esté cargado correctamente - En el nodo
Load Image, cargue la imagen de entrada proporcionada anteriormente - Verifique el nodo
Load VAE: Asegúrese de que hunyuan_video_vae_bf16.safetensors esté cargado correctamente - Verifique el nodo
Load Diffusion Model: Asegúrese de que hunyuan_video_image_to_video_720p_bf16.safetensors esté cargado correctamente
- Si encuentra un error de
running out of memory.durante la ejecución, puede intentar configurarweight_dtypeal tipofp8
- Haga clic en el botón
Runo use el atajo de tecladoCtrl(cmd) + Enterpara ejecutar la generación de vídeo
Versión Kijai HunyuanVideoWrapper
1. Instalación de nodos personalizados
Necesita instalar los siguientes nodos personalizados:
Si no sabe cómo instalar nodos personalizados, consulte la Guía de instalación de nodos personalizados de ComfyUI
2. Descargas de modelos
Los archivos descargados deben organizarse según la estructura a continuación y guardarse en las carpetas correspondientes bajo ComfyUI/models:
ComfyUI/
├── models/
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── diffusion_models/
│ └── hunyuan_video_I2V_fp8_e4m3fn.safetensors3. Archivo de flujo de trabajo HunyuanVideo I2V
Complete la verificación de cada nodo del flujo de trabajo HunyuanVideo I2V (Kijai)
Consulte la imagen para completar la verificación del contenido de cada nodo y asegurar que el flujo de trabajo funcione correctamente
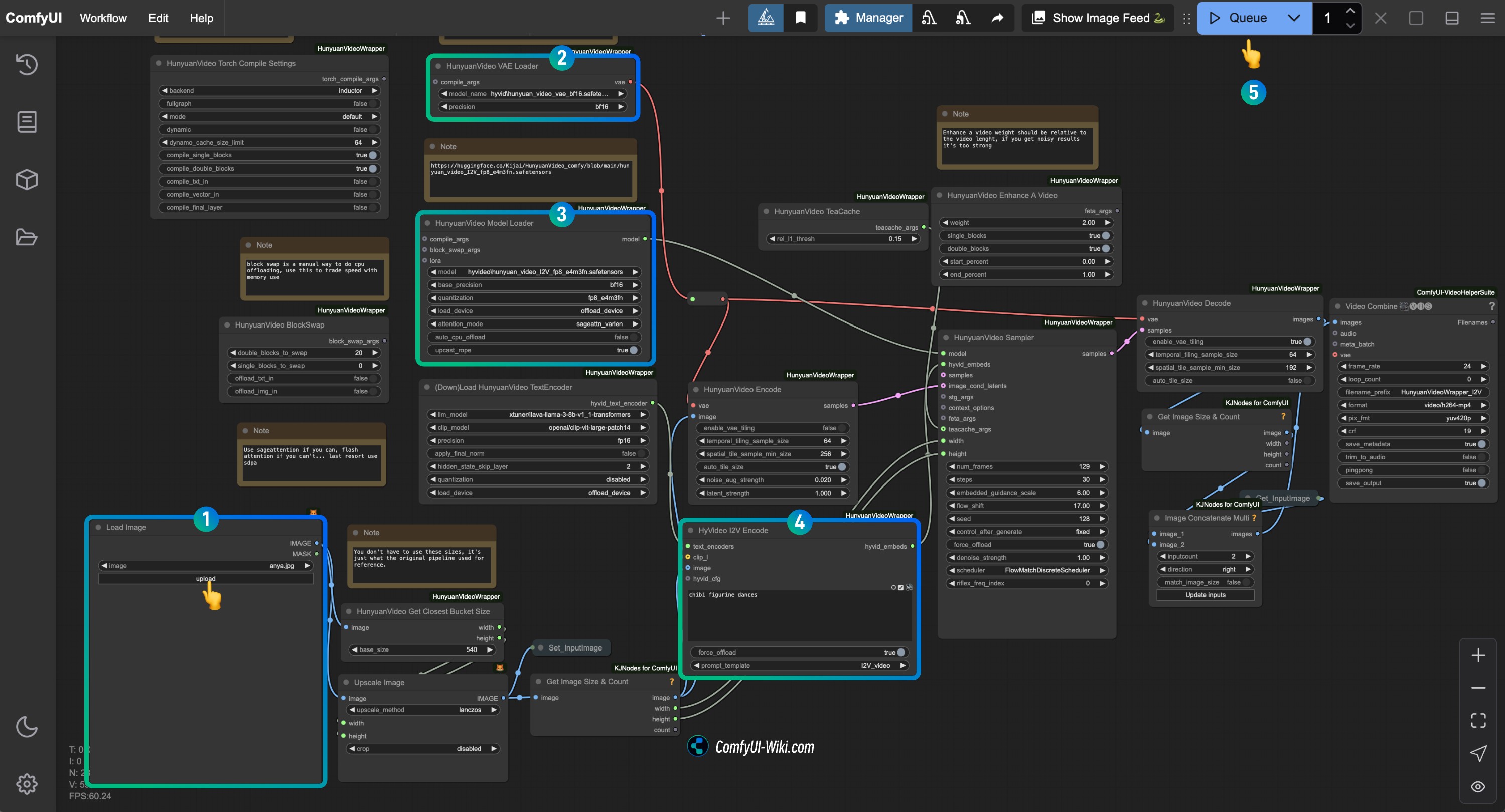
- En el nodo
Load Image, cargue la imagen que desea usar para la generación de imagen a vídeo - En el nodo
HunyuanVideo VAE Loader, asegúrese de quehunyuan_video_vae_bf16.safetensorsesté cargado correctamente - En el nodo
HunyuanVideo Model Loader, asegúrese de quehunyuan_video_I2V_fp8_e4m3fn.safetensorsesté cargado correctamente - Modifique el texto del prompt en el nodo
HyVideo I2V Encode, ingrese la descripción del vídeo que desea generar - Haga clic en el botón
Runo use el atajo de tecladoCtrl(cmd) + Enterpara ejecutar la generación de vídeo
Versión city96 GGUF
1. Instalación de nodos personalizados (GGUF)
Necesita instalar el siguiente nodo personalizado:
Si no sabe cómo instalar nodos personalizados, consulte la Guía de instalación de nodos personalizados de ComfyUI
2. Descargas de modelos (GGUF)
Los modelos para esta versión son básicamente los mismos que la versión oficial de ComfyUI, excepto por el modelo HunyuanVideo en sí. Consulte la sección de la versión oficial de ComfyUI de este artículo para descargas manuales.
Debe visitar city96/HunyuanVideo-I2V-gguf para descargar la versión del modelo que necesita y guardar el archivo de modelo gguf correspondiente en la carpeta ComfyUI/models:
ComfyUI/
├── models/
│ ├── clip_vision/
│ │ └── llava_llama3_vision.safetensors
│ ├── text_encoders/
│ │ ├── clip_l.safetensors
│ │ ├── llava_llama3_fp16.safetensors
│ │ └── llava_llama3_fp8_scaled.safetensors
│ ├── vae/
│ │ └── hunyuan_video_vae_bf16.safetensors
│ └── unet/
│ └── hunyuan-video-i2v-720p-Q4_K_M.gguf // Depende de la versión GGUF que haya descargado3. Archivo de flujo de trabajo HunyuanVideo I2V (GGUF)
Complete la verificación de cada nodo del flujo de trabajo HunyuanVideo I2V (GGUF)
Consulte la imagen para completar la verificación del contenido de cada nodo y asegurar que el flujo de trabajo funcione correctamente
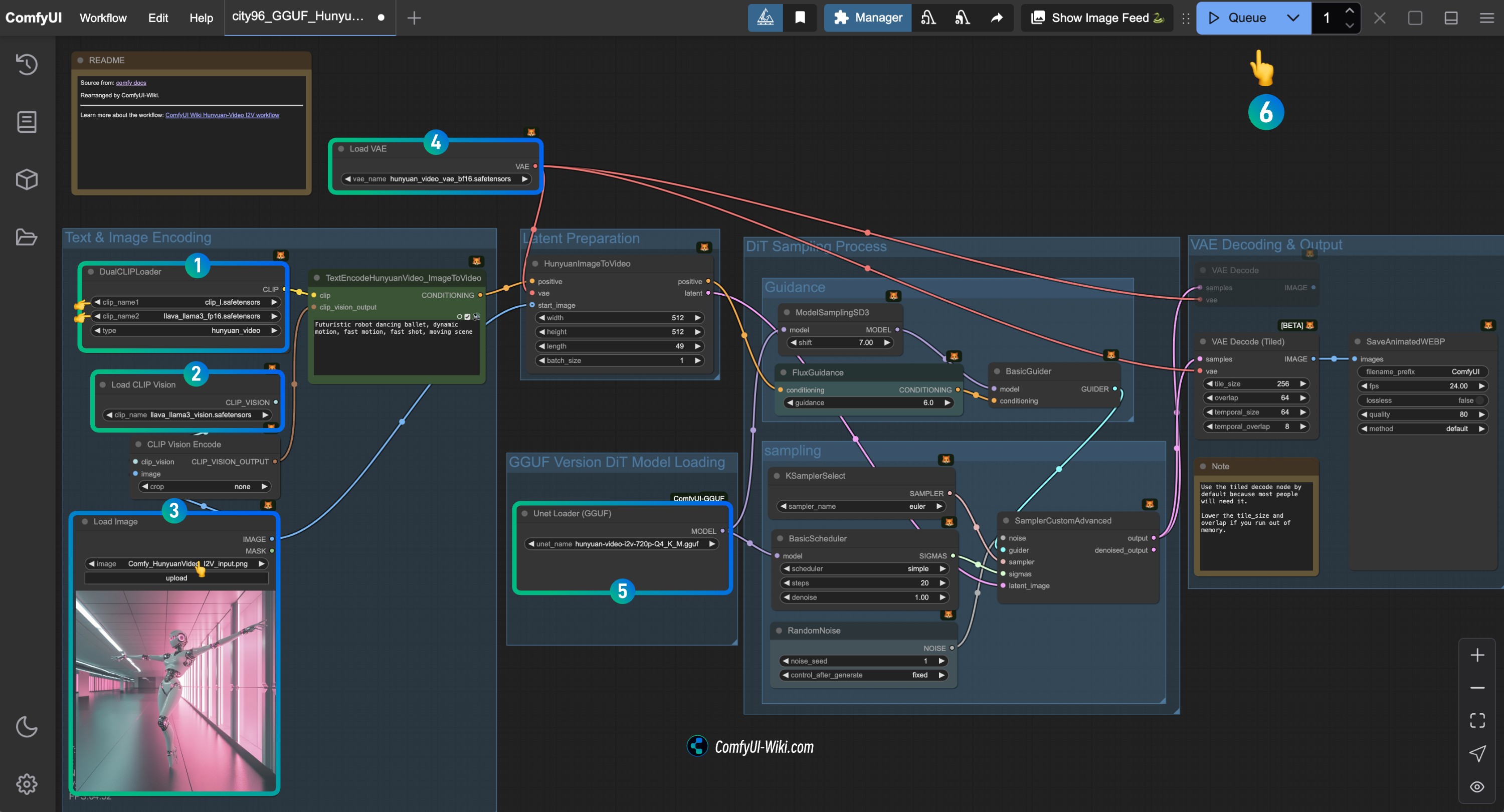
- Verifique el nodo
DualCLIPLoader:
- Asegúrese de que
clip_name1: clip_l.safetensors esté cargado correctamente - Asegúrese de que
clip_name2: llava_llama3_vision.safetensors esté cargado correctamente
- Verifique el nodo
Load CLIP Vision: Asegúrese de que llava_llama3_vision.safetensors esté cargado correctamente - En el nodo
Load Image, cargue la imagen de entrada proporcionada anteriormente - Verifique el nodo
Load VAE: Asegúrese de que hunyuan_video_vae_bf16.safetensors esté cargado correctamente - Verifique el nodo
Load Diffusion Model: Asegúrese de que el modelo GGUF de HunyuanVideo correspondiente esté cargado correctamente - Haga clic en el botón
Runo use el atajo de tecladoCtrl(cmd) + Enterpara ejecutar la generación de vídeo
Comentarios
Inicia sesión con GitHub para unirte a la conversación.