Guía Completa de Flujos de Trabajo de Qwen-Image ComfyUI Nativo, GGUF y Nunchaku
Qwen-Image es un modelo MMDiT (Transformador de Difusión Multimodal) de 20 mil millones de parámetros de código abierto bajo la licencia Apache 2.0.
Qwen-Image es un modelo base de generación de imágenes desarrollado por el equipo Tongyi Lab de Alibaba, que utiliza una arquitectura MMDiT (Transformador de Difusión Multimodal) de 20 mil millones de parámetros, publicado como código abierto bajo la licencia Apache 2.0. El modelo demuestra ventajas técnicas únicas en el campo de la generación de imágenes, destacando especialmente en la representación de texto y la edición de imágenes.
Características Principales:
- Capacidad de Representación de Texto Multilingüe: El modelo puede generar con precisión imágenes que contienen inglés, chino, coreano, japonés y otros idiomas, con texto claro y legible que se armoniza con el estilo de la imagen
- Amplia Gama de Estilos Artísticos: Desde estilos realistas hasta creaciones artísticas, desde estilos de anime hasta diseño moderno, el modelo puede cambiar flexiblemente entre diferentes estilos visuales según las indicaciones
- Funcionalidad de Edición de Imágenes Precisa: Soporta modificaciones locales, transformaciones de estilo y adiciones de contenido a imágenes existentes, manteniendo la consistencia visual general
Recursos Relacionados:
- Dirección del Proyecto en GitHub
- Página del Modelo en Hugging Face
- Repositorio de Modelos ModelScope
Guía de Flujo de Trabajo Nativo de Qwen-Image ComfyUI
En el flujo de trabajo adjunto a este documento se utilizan tres modelos diferentes:
- Modelo original de Qwen-Image fp8_e4m3fn
- Versión acelerada de 8 pasos: Modelo original de Qwen-Image fp8_e4m3fn usando LoRA de 8 pasos lightx2v
- Versión destilada: Modelo destilado de Qwen-Image fp8_e4m3fn
Referencia de Uso de Memoria VRAM GPU: RTX4090D 24GB
| Modelo Utilizado | Uso de VRAM | Primera Generación | Segunda Generación |
|---|---|---|---|
| fp8_e4m3fn | 86% | ≈ 94s | ≈ 71s |
| fp8_e4m3fn usando LoRA de 8 pasos lightx2v | 86% | ≈ 55s | ≈ 34s |
| Versión destilada fp8_e4m3fn | 86% | ≈ 69s | ≈ 36s |
1. Archivo de Flujo de Trabajo
Después de actualizar ComfyUI, puedes encontrar el archivo de flujo de trabajo en las plantillas, o arrastrar el flujo de trabajo a continuación a ComfyUI para cargarlo

<a className="prose" target='_blank' href="https://raw.githubusercontent.com/Comfy-Org/workflow_templates/refs/heads/main/templates/image_qwen_image.json" style={{ display: 'inline-block', backgroundColor: '#0078D6', color: '#ffffff', padding: '10px 20px', borderRadius: '8px', borderColor: "transparent", textDecoration: 'none', fontWeight: 'bold'}}> <p className="prose" style={{ margin: 0, fontSize: "0.8rem" }}>Descargar Flujo de Trabajo Oficial en Formato JSON
Versión Destilada
2. Descarga de Modelos
Versiones que puedes encontrar en el repositorio de ComfyOrg
- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
- Versión destilada (no oficial, solo 15 pasos)
Todos los modelos se pueden encontrar en Huggingface o ModelScope
Modelo de difusión
Qwen_image_distill
LoRA
Codificador de texto
VAE
Ubicación de almacenamiento de modelos
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ ├── qwen_image_fp8_e4m3fn.safetensors
│ │ └── qwen_image_distill_full_fp8_e4m3fn.safetensors ## Versión destilada
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-8steps-V1.0.safetensors ## Modelo LoRA de aceleración de 8 pasos
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors3. Completar el Flujo de Trabajo Paso a Paso
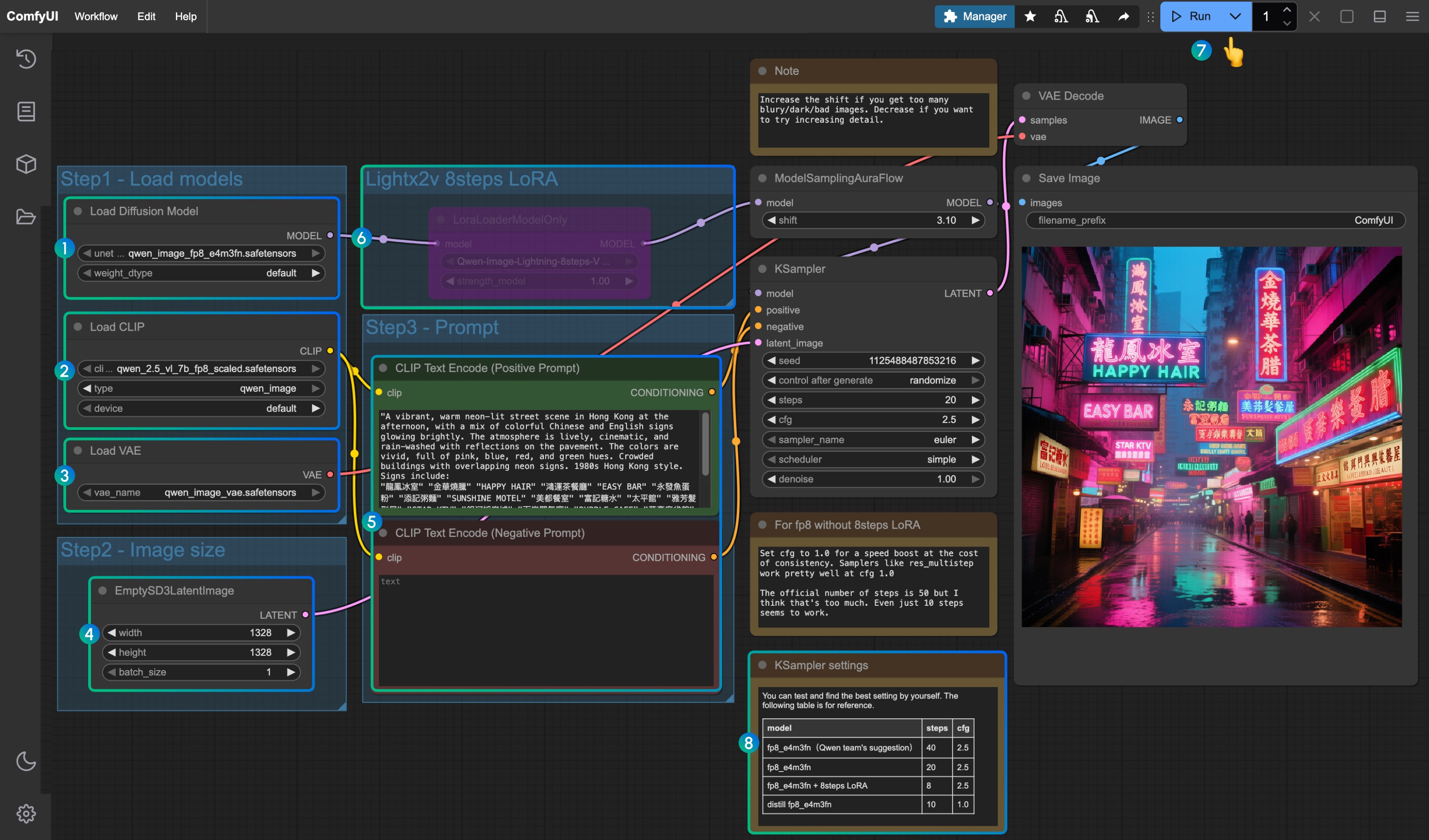
- Asegúrese de que el nodo
Load Diffusion Modelcargueqwen_image_fp8_e4m3fn.safetensors - Asegúrese de que el nodo
Load CLIPcargueqwen_2.5_vl_7b_fp8_scaled.safetensors - Asegúrese de que el nodo
Load VAEcargueqwen_image_vae.safetensors - Asegúrese de que las dimensiones de la imagen estén configuradas en el nodo
EmptySD3LatentImage - Configure los indicadores en el nodo
CLIP Text Encoder; actualmente probado para soportar al menos: inglés, chino, coreano, japonés, italiano, etc. - Para habilitar el LoRA de aceleración de 8 pasos lightx2v, selecciónelo y use
Ctrl + Bpara habilitar el nodo, y modifique la configuración de Ksampler según los parámetros en la posición8 - Haga clic en el botón
Queue, o use el atajoCtrl(cmd) + Enterpara ejecutar el flujo de trabajo - Configuración de parámetros para KSampler correspondiente a diferentes versiones de modelos y flujos de trabajo
Flujo de Trabajo Qwen-Image Versión GGUF ComfyUI
La versión GGUF es más amigable para usuarios con poca VRAM, y en ciertas configuraciones de pesos, solo necesita aproximadamente 8GB de VRAM para ejecutar Qwen-Image
Referencia de Uso de VRAM:
| Flujo de Trabajo | Uso de VRAM | Primera Generación | Generaciones Subsiguientes |
|---|---|---|---|
| qwen-image-Q4_K_S.gguf | 56% | ≈ 135s | ≈ 77s |
| Con LoRA de 8 pasos | 56% | ≈ 100s | ≈ 45s |
Dirección del modelo: Qwen-Image-gguf
1. Actualizar o Instalar Nodos Personalizados
Usar la versión GGUF requiere que instale o actualice el complemento ComfyUI-GGUF
Consulte Cómo Instalar Nodos Personalizados de ComfyUI, o busque e instale a través del Administrador
2. Descarga de Flujo de Trabajo

3. Descarga de Modelos
La versión GGUF solo utiliza el modelo de difusión diferente de los demás
Visite https://huggingface.co/city96/Qwen-Image-gguf para descargar cualquier peso; normalmente, los archivos de mayor tamaño significan mejor calidad pero también requieren más VRAM. En este tutorial, usaré la siguiente versión:
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen-image-Q4_K_S.gguf # O cualquier otra versión que elija3. Completar el flujo de trabajo GGUF paso a paso
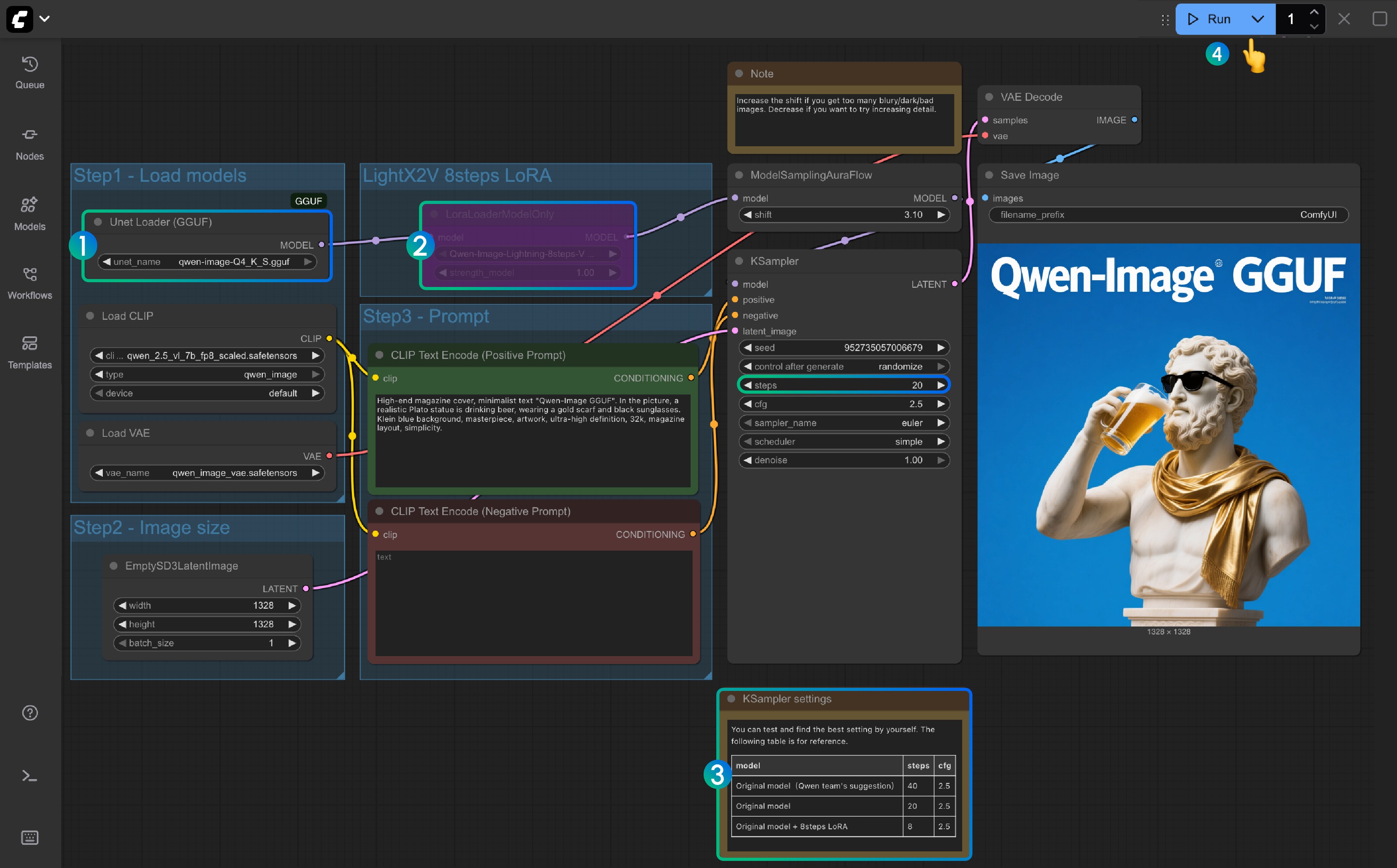
- Asegúrese de que el nodo
Unet Loader(GGUF)cargueqwen-image-Q4_K_S.ggufo cualquier otra versión que haya descargado- Asegúrese de que ComfyUI-GGUF esté instalado y actualizado
- Para
LightX2V 8Steps LoRA, no está habilitado por defecto; puede seleccionarlo y usar Ctrl+B para habilitar el nodo - Si el LoRA de 8 pasos no está habilitado, los pasos predeterminados son 20; si habilita el LoRA de 8 pasos, configúrelo a 8
- Aquí está la referencia para configurar los pasos correspondientes
- Haga clic en el botón
Queue, o use el atajoCtrl(cmd) + Enterpara ejecutar el flujo de trabajo
Flujo de Trabajo Versión Nunchaku de Qwen-Image
Dirección del modelo: nunchaku-qwen-image Dirección del nodo personalizado: https://github.com/nunchaku-tech/ComfyUI-nunchaku
Qwen Image ControlNet
Flujo de Trabajo Qwen Image ControlNet DiffSynth-ControlNets Model Patches
Este modelo en realidad no es un controlnet, sino un Model patch que admite tres modos de control diferentes: canny, depth e inpaint.
Dirección del modelo original: DiffSynth-Studio/Qwen-Image ControlNet Dirección de rehost Comfy Org: Qwen-Image-DiffSynth-ControlNets/model_patches
1. Flujo de Trabajo e Imágenes de Entrada
Descargue la imagen de abajo y arrástrela a ComfyUI para cargar el flujo de trabajo correspondiente

Descargue la imagen de abajo como imagen de entrada:

2. Enlaces de Modelos
Los otros modelos son consistentes con el flujo de trabajo básico de Qwen-Image. Solo necesita descargar los siguientes modelos y guardarlos en la carpeta ComfyUI/models/model_patches:
- qwen_image_canny_diffsynth_controlnet.safetensors
- qwen_image_depth_diffsynth_controlnet.safetensors
- qwen_image_inpaint_diffsynth_controlnet.safetensors
3. Instrucciones de Uso del Flujo de Trabajo
Actualmente, diffsynth tiene tres modelos de patch: los modelos Canny, Depth e Inpaint.
Si está usando flujos de trabajo relacionados con ControlNet por primera vez, debe entender que las imágenes utilizadas para el control deben ser preprocesadas en formatos de imagen compatibles antes de que puedan ser utilizadas y reconocidas por el modelo.

- Canny: Canny procesado, contornos de dibujo a línea
- Depth: Mapa de profundidad preprocesado, mostrando relaciones espaciales
- Inpaint: Requiere usar una Máscara para marcar las áreas que necesitan ser redibujadas
Dado que este modelo de patch está dividido en tres modelos diferentes, debe seleccionar el tipo de preprocesamiento correcto al ingresar para asegurar un preprocesamiento de imagen correcto.
Instrucciones de Uso del Modelo Canny ControlNet
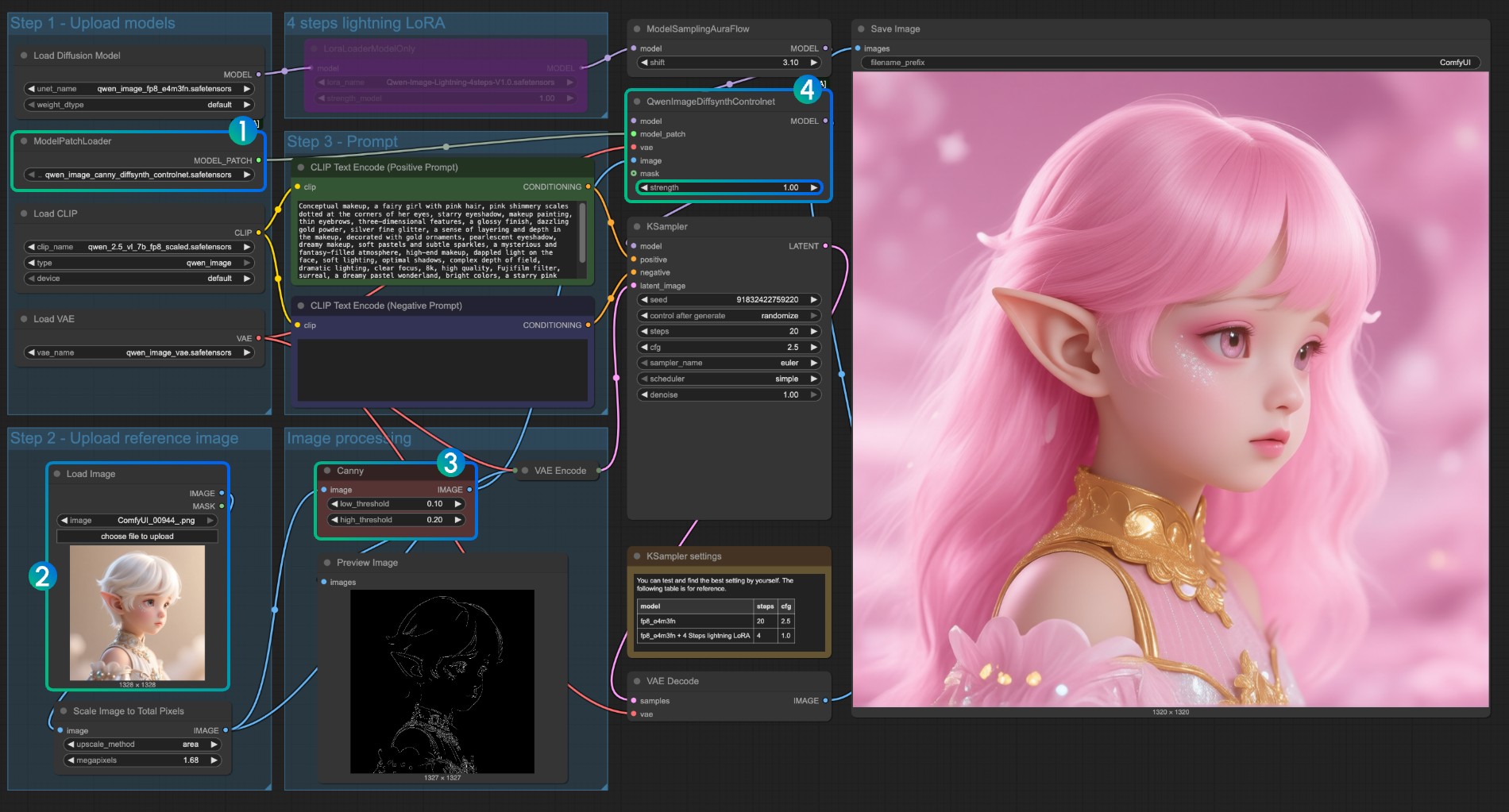
- Asegúrese de que
qwen_image_canny_diffsynth_controlnet.safetensorsesté cargado - Suba la imagen de entrada para el procesamiento posterior
- El nodo Canny es un nodo de preprocesamiento nativo que preprocesará la imagen de entrada según sus parámetros establecidos para controlar la generación
- Si es necesario, puede modificar el parámetro
strengthdel nodoQwenImageDiffsynthControlnetpara controlar la fuerza del control de dibujo a línea - Haga clic en el botón
Run, o use el atajoCtrl(cmd) + Enterpara ejecutar el flujo de trabajo
Para usar qwen_image_depth_diffsynth_controlnet.safetensors, debe preprocesar la imagen en un mapa de profundidad, reemplazando la parte
image processing. Para este uso, consulte el método de procesamiento InstantX en este documento. Otras partes son similares al uso del modelo Canny.
Instrucciones de Uso del Modelo Inpaint ControlNet
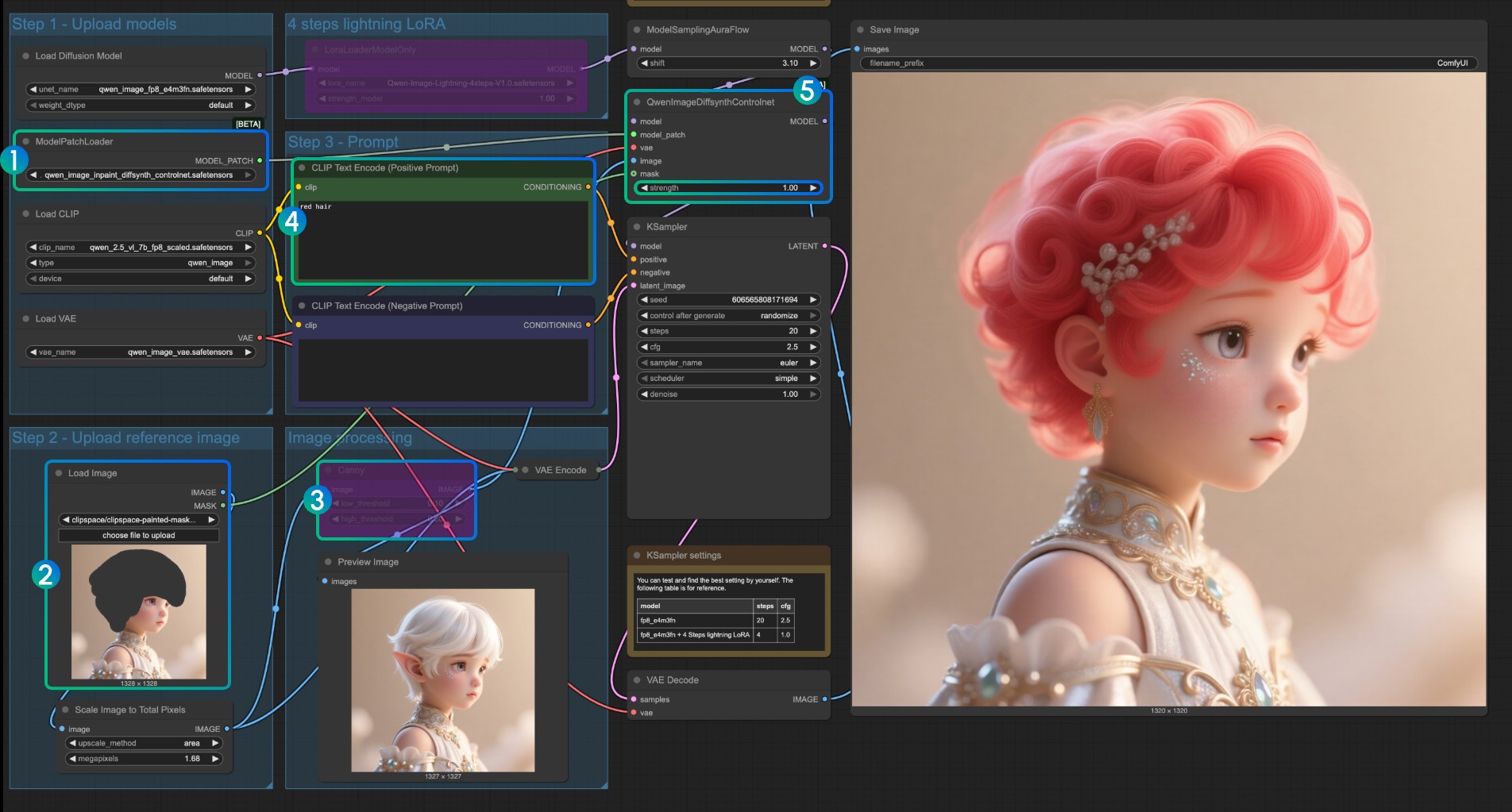
Para el modelo Inpaint, requiere usar el editor de máscaras para dibujar una máscara y usarla como condición de control de entrada.
- Asegúrese de que
ModelPatchLoadercargue el modeloqwen_image_inpaint_diffsynth_controlnet.safetensors - Suba una imagen y use el editor de máscaras para dibujar una máscara. Debe conectar la salida
maskdel nodoLoad Imagecorrespondiente a la entradamaskdeQwenImageDiffsynthControlnetpara asegurar que la máscara correspondiente se cargue - Use el atajo
Ctrl-Bpara establecer el Canny original en el flujo de trabajo en modo bypass, para que el procesamiento del nodo Canny correspondiente no tenga efecto - En el
codificador de texto CLIP, ingrese el estilo que desea cambiar para la parte enmascarada - Si es necesario, puede modificar el parámetro
strengthdel nodoQwenImageDiffsynthControlnetpara controlar la fuerza de control correspondiente - Haga clic en el botón
Run, o use el atajoCtrl(cmd) + Enterpara ejecutar el flujo de trabajo
Flujo de Trabajo Qwen Image Union ControlNet LoRA
Dirección del modelo original: DiffSynth-Studio/Qwen-Image-In-Context-Control-Union Dirección de rehost Comfy Org: qwen_image_union_diffsynth_lora.safetensors: LoRA de control de estructura de imagen que admite canny, depth, pose, lineart, softedge, normal, openpose
1. Flujo de Trabajo e Imágenes de Entrada
Descargue la imagen de abajo y arrástrela a ComfyUI para cargar el flujo de trabajo

Descargue la imagen de abajo como imagen de entrada:

2. Enlaces de Modelos
Descargue el siguiente modelo. Como es un modelo LoRA, debe guardarse en la carpeta ComfyUI/models/loras/:
- qwen_image_union_diffsynth_lora.safetensors: LoRA de control de estructura de imagen que admite canny, depth, pose, lineart, softedge, normal, openpose
3. Instrucciones del Flujo de Trabajo
Este modelo es un LoRA de control unificado que admite canny, depth, pose, lineart, softedge, normal, openpose y otros controles. Como muchos nodos de preprocesamiento de imagen nativos no están completamente soportados, puede necesitar algo como comfyui_controlnet_aux para completar otros preprocesamientos de imagen.
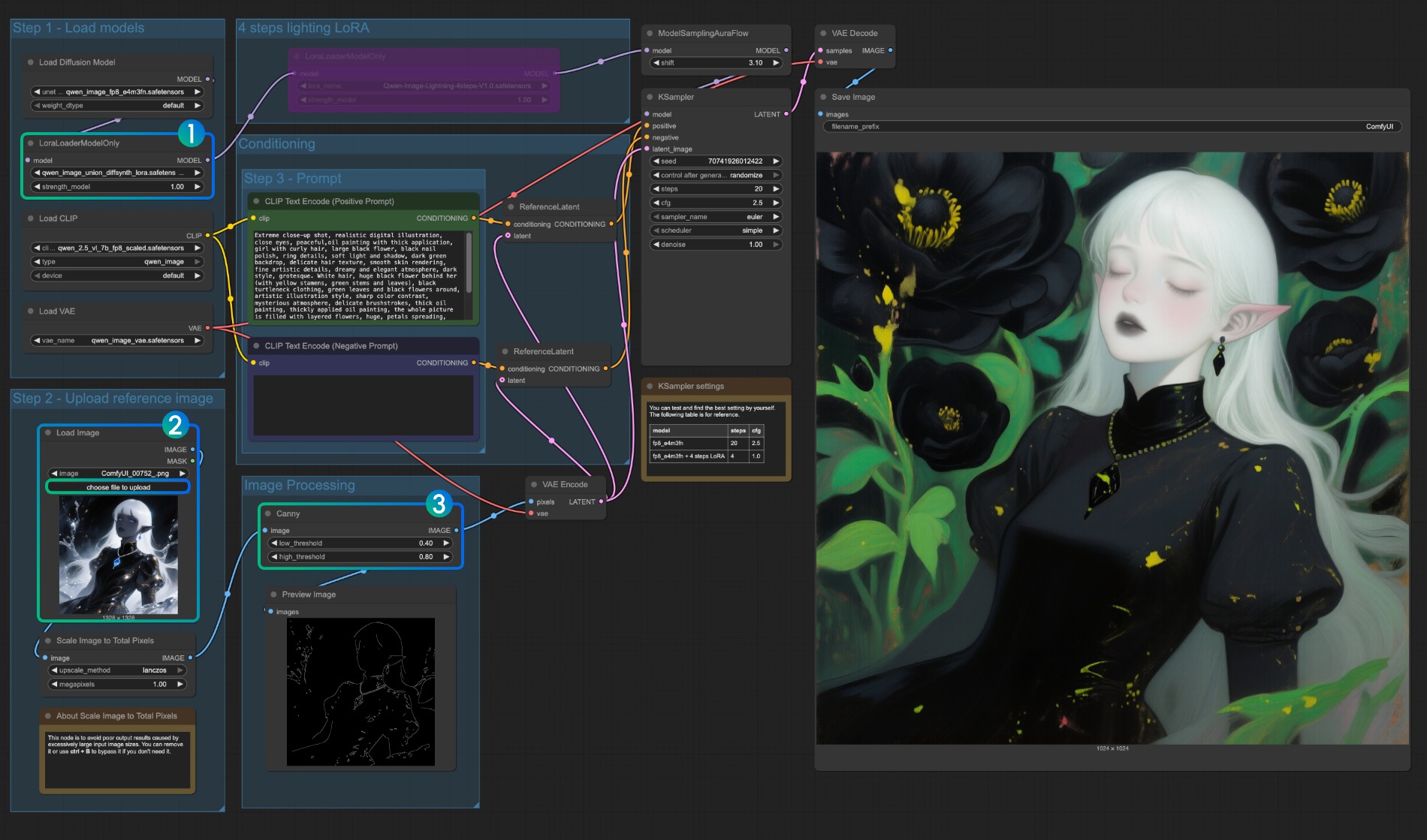
- Asegúrese de que
LoraLoaderModelOnlycargue correctamente el modeloqwen_image_union_diffsynth_lora.safetensors - Suba la imagen de entrada
- Si es necesario, puede ajustar los parámetros del nodo
Canny. Como diferentes imágenes de entrada requieren diferentes configuraciones de parámetros para obtener mejores resultados de preprocesamiento de imagen, puede intentar ajustar los valores de parámetros correspondientes para obtener más/menos detalles - Haga clic en el botón
Run, o use el atajoCtrl(cmd) + Enterpara ejecutar el flujo de trabajo
Para otros tipos de control, también debe reemplazar la parte de procesamiento de imagen.
Comentarios
Inicia sesión con GitHub para unirte a la conversación.