Flujo de trabajo y tutorial de generación de video impulsado por audio Wan2.2-S2V en ComfyUI
Crea avatares parlantes con lip-sync natural usando Wan2.2-S2V en ComfyUI. Cubre configuración del modelo, pipeline S2V y ejemplos de workflow.
Wan2.2-S2V representa un avance significativo en la tecnología de generación de video por IA, capaz de crear contenido de video dinámico a partir de imágenes estáticas y entradas de audio. Este modelo innovador destaca en la producción de videos sincronizados con sincronización labial natural, lo que lo hace particularmente valioso para creadores de contenido que trabajan en escenas de diálogo, actuaciones musicales y narrativas basadas en personajes.
Aspectos destacados del modelo
- Generación de video impulsada por audio: Transforma imágenes estáticas y audio en videos sincronizados con sincronización labial y expresiones naturales
- Calidad cinematográfica: Genera videos de calidad cinematográfica con expresiones faciales auténticas, movimientos corporales y lenguaje cinematográfico
- Generación de nivel de minutos: Soporta la creación de videos de larga duración de hasta nivel de minutos en una sola generación
- Soporte multi-formato: Funciona con personas reales, dibujos animados, animales, humanos digitales y soporta formatos de retrato, medio cuerpo y cuerpo completo
- Control de movimiento mejorado: Genera acciones y entornos a partir de instrucciones de texto con mecanismos de control AdaIN y CrossAttention
- Métricas de alto rendimiento: Alcanza FID 15.66, CSIM 0.677 y SSIM 0.734 para una calidad de video superior y consistencia de identidad
Flujo de trabajo nativo de Wan2.2 S2V en ComfyUI
1. Descargar archivo de flujo de trabajo
Descargue el siguiente archivo de flujo de trabajo y arrástrelo a ComfyUI para cargar el flujo de trabajo.
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/wan2.2_s2v/wan2.2-s2v.mp4"
Descargue la siguiente imagen y audio como entrada:

2. Enlaces de modelos
Puede encontrar los modelos en nuestro repositorio
diffusion_models
audio_encoders
vae
text_encoders
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_s2v_14B_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 audio_encoders/ # Cree una si no puede encontrar esta carpeta
│ │ └─── wav2vec2_large_english_fp16.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors3. Instrucciones del flujo de trabajo
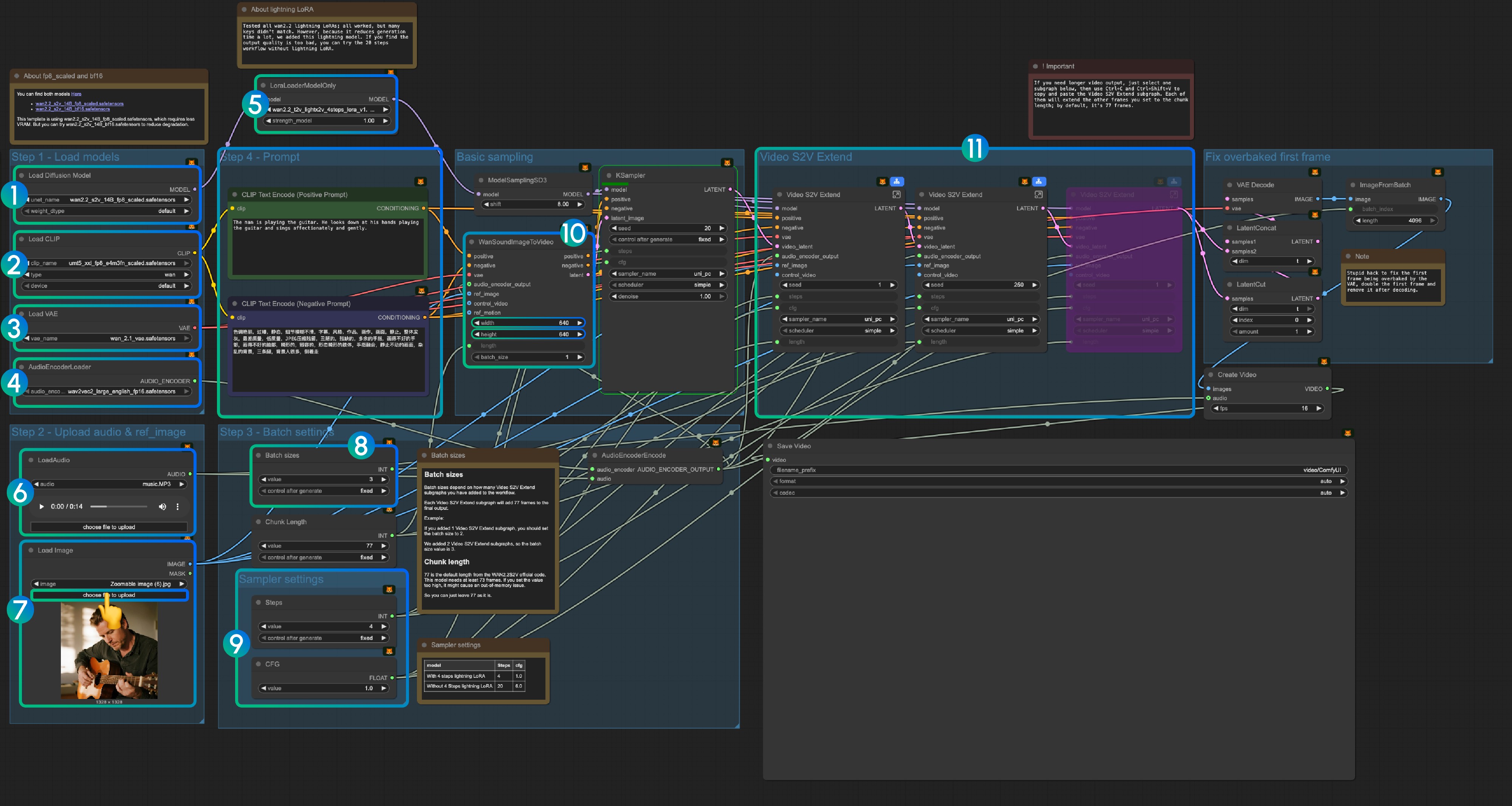
3.1 Lightning LoRA (Opcional, para aceleración)
Lightning LoRA reduce el tiempo de generación de 20 pasos a 4 pasos pero puede afectar la calidad. Úselo para vistas previas rápidas, desactívelo para la salida final.
3.1.1 Consejos de preprocesamiento de audio
Separación de voz para mejores resultados: Dado que el núcleo de ComfyUI no incluye nodos de separación de voz, recomendamos usar herramientas externas para separar las vocales de la música de fondo antes del procesamiento. Esto es especialmente importante para la generación de diálogos y sincronización labial, ya que las pistas vocales limpias producen resultados significativamente mejores que el audio mezclado con música de fondo o ruido.
3.2 Acerca de los modelos fp8_scaled y bf16
Puede encontrar ambos modelos aquí:
La plantilla usa wan2.2_s2v_14B_fp8_scaled.safetensors para menor uso de VRAM. Pruebe wan2.2_s2v_14B_bf16.safetensors para mejor calidad.
3.3 Instrucciones paso a paso
Paso 1: Cargar modelos
- Cargar modelo de difusión: Cargue
wan2.2_s2v_14B_fp8_scaled.safetensorsowan2.2_s2v_14B_bf16.safetensors- El flujo de trabajo usa
wan2.2_s2v_14B_fp8_scaled.safetensorspara requisitos de VRAM más bajos - Use
wan2.2_s2v_14B_bf16.safetensorspara salida de mejor calidad
- El flujo de trabajo usa
- Cargar CLIP: Cargue
umt5_xxl_fp8_e4m3fn_scaled.safetensors - Cargar VAE: Cargue
wan_2.1_vae.safetensors - AudioEncoderLoader: Cargue
wav2vec2_large_english_fp16.safetensors - LoraLoaderModelOnly: Cargue
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors(Lightning LoRA)- Este LoRA reduce el tiempo de generación pero puede afectar la calidad
- Desactive si la calidad de salida es insuficiente
- LoadAudio: Cargue el archivo de audio proporcionado o su propio audio
- Load Image: Cargue la imagen de referencia
- Tamaños de lote: Configure según el número de nodos del subgrafo Video S2V Extend
- Cada subgrafo Video S2V Extend agrega 77 cuadros a la salida
- Ejemplo: 2 subgrafos Video S2V Extend = tamaño de lote 3
- Longitud de fragmento: Mantenga el valor predeterminado de 77
- Configuración del muestreador: Elija según el uso de Lightning LoRA
- Con Lightning LoRA de 4 pasos: steps: 4, cfg: 1.0
- Sin Lightning LoRA: steps: 20, cfg: 6.0
- Configuración de tamaño: Establezca las dimensiones del video de salida
- Video S2V Extend: Nodos de subgrafo de extensión de video
- Cada extensión genera 77 / 16 = 4.8125 segundos de video
- Calcular nodos necesarios: longitud de audio (segundos) × 16 ÷ 77
- Ejemplo: audio de 14s = 224 cuadros ÷ 77 = 3 nodos de extensión
- Use Ctrl-Enter o haga clic en el botón Ejecutar para ejecutar el flujo de trabajo
Enlaces relacionados
- Código Wan2.2 S2V: GitHub
- Modelo Wan2.2 S2V: Hugging Face
Comentarios
Inicia sesión con GitHub para unirte a la conversación.