Flujo de trabajo Wan2.1 ComfyUI - Guía completa
Este tutorial explica detalladamente cómo usar el modelo Wan2.1 en ComfyUI, incluyendo instalación, configuración, uso del flujo de trabajo y ajuste de parámetros, abarcando texto a video, imagen a video y video a video.
Wan2.1, lanzado como código abierto por Alibaba en febrero de 2025, es un modelo referente en el campo de la generación de videos. Con licencia Apache 2.0, ofrece versiones de 14B (14 mil millones de parámetros) y 1.3B (1.3 mil millones de parámetros), cubriendo tareas como texto a video (T2V), imagen a video (I2V) y más.
Además, la comunidad ya ha creado versiones GGUF y cuantizadas:
- GGUF: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
- Versión cuantizada: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
Este artículo te guiará a través de varios flujos de trabajo relacionados con Wan2.1, incluyendo:
- Flujo de trabajo nativo de ComfyUI para Wan2.1
- Versión de Kijai
- Versión GGUF de City96
ComfyUI/output.
Dado que Wan2.1 separa los modelos de 480P y 720P, los flujos de trabajo correspondientes no tienen diferencias, excepto por el modelo y el tamaño del lienzo. Puedes ajustar el flujo de trabajo de la otra versión según el flujo de trabajo de 720P o 480P correspondiente.
Ejemplos de flujo de trabajo nativo de Wan2.1 para ComfyUI
Los siguientes flujos de trabajo provienen del blog oficial de ComfyUI. Actualmente, ComfyUI ya soporta nativamente Wan2.1. Para usar la versión de soporte nativo oficial, actualiza tu ComfyUI a la última versión siguiendo la guía Cómo actualizar ComfyUI. ComfyUI Wiki ha organizado los flujos de trabajo originales.
Después de actualizar ComfyUI a la última versión, podrás ver las plantillas de flujo de trabajo de Wan2.1 en la barra de menú Workflows -> Workflow Templates.
Todos los archivos de flujo de trabajo de esta versión provienen de Comfy-Org/Wan_2.1_ComfyUI_repackaged
En Diffusion models, Comfy-org ofrece múltiples versiones. Si la versión nativa oficial utilizada en este artículo tiene requisitos de hardware elevados, puedes elegir la versión que mejor se adapte a tus necesidades.
- i2v es el modelo de imagen a video, t2v es el modelo de texto a video
- 14B, 1.3B representan la cantidad de parámetros; a mayor valor, mayores requisitos de hardware
- bf16, fp16, fp8 representan diferentes precisiones; a mayor precisión, mayores requisitos de hardware
- bf16 puede requerir GPUs con arquitectura Ampere o superior
- fp16 es más ampliamente compatible
- fp8 tiene la menor precisión y los menores requisitos de hardware, pero también ofrece resultados de menor calidad
- Generalmente, cuanto mayor sea el tamaño del archivo, mayores serán los requisitos de hardware
1. Flujo de trabajo de texto a video Wan2.1
1.1 Descarga del archivo de flujo de trabajo de texto a video Wan2.1
Descarga la siguiente imagen y arrástrala a ComfyUI o usa la barra de menú Workflows -> Open(Ctrl+O) para cargar el flujo de trabajo

Descarga del archivo en formato Json
1.2 Instalación manual del modelo
Si el archivo de flujo de trabajo anterior no completa la descarga del modelo, descarga los siguientes archivos de modelo y guárdalos en las ubicaciones correspondientes.
Elige uno de los siguientes archivos de modelo Diffusion para descargar:
- wan2.1_t2v_14B_bf16.safetensors
- wan2.1_t2v_14B_fp16.safetensors
- wan2.1_t2v_14B_fp8_e4m3fn.safetensors
- wan2.1_t2v_14B_fp8_scaled.safetensors
- wan2.1_t2v_1.3B_bf16.safetensors
- wan2.1_t2v_1.3B_fp16.safetensors
Elige una versión de Text encoders para descargar:
VAE
Ubicación para guardar los archivos
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_t2v_14B_fp16.safetensors # o la versión que hayas seleccionado
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # o la versión que hayas seleccionado
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 Pasos para ejecutar el flujo de trabajo
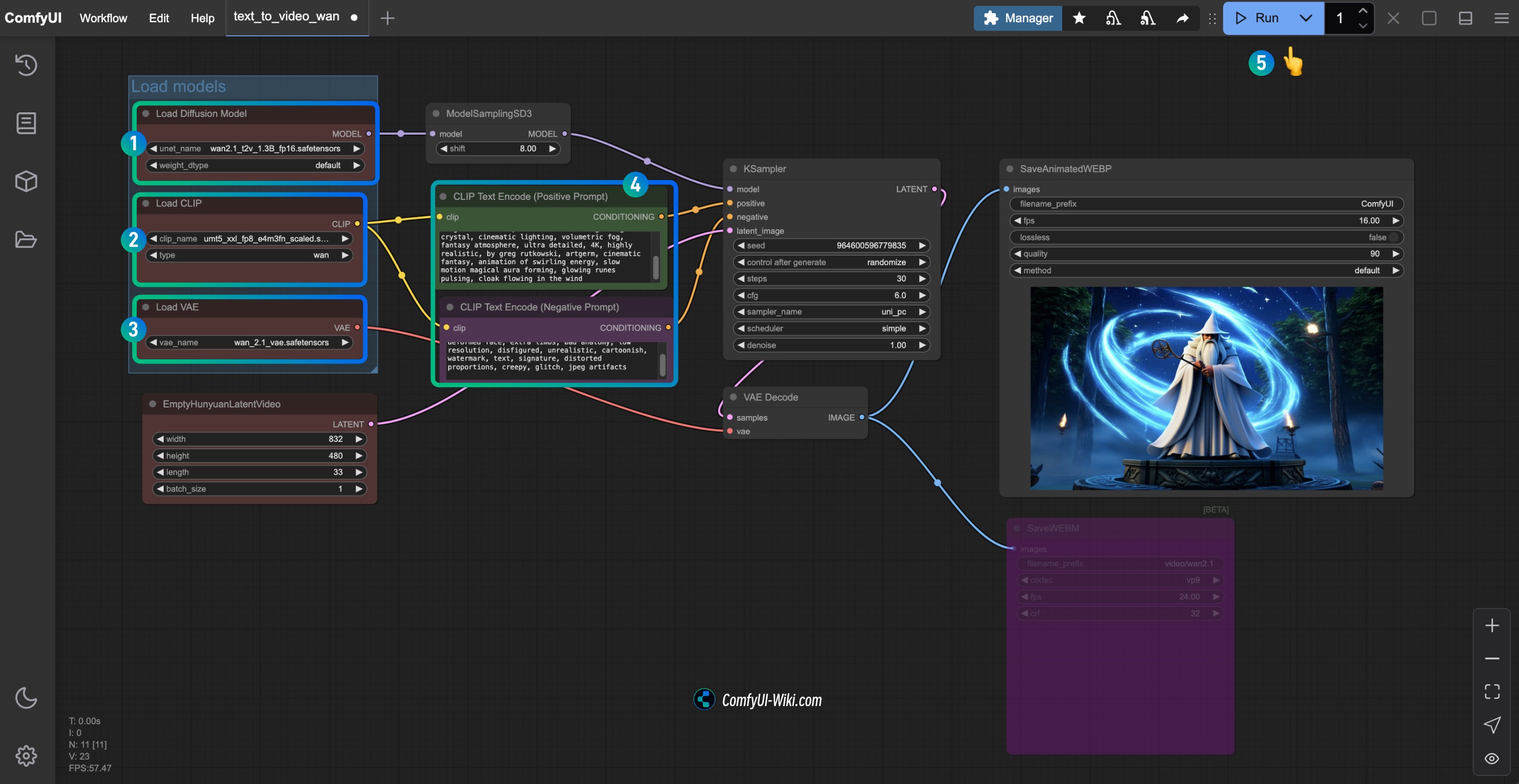
- Asegúrate de que el nodo
Load Diffusion Modelhaya cargado el modelowan2.1_t2v_1.3B_fp16.safetensors - Asegúrate de que el nodo
Load CLIPhaya cargado el modeloumt5_xxl_fp8_e4m3fn_scaled.safetensors - Asegúrate de que el nodo
Load VAEhaya cargado el modelowan_2.1_vae.safetensors - Puedes ingresar el contenido de descripción del video que deseas generar en el nodo
CLIP Text Encoder - Haz clic en el botón
Run, o utiliza el atajoCtrl(cmd) + Enterpara ejecutar la generación del video
2. Flujo de trabajo de imagen a video Wan2.1
2.1 Flujo de trabajo de imagen a video Wan2.1 14B Workflow
Descarga del archivo de flujo de trabajo
Haz clic en el siguiente botón para descargar el flujo de trabajo correspondiente y arrástralo a ComfyUI o usa la barra de menú Workflows -> Open(Ctrl+O) para cargar el flujo de trabajo

Descarga del archivo en formato Json
Este flujo de trabajo es similar al de 480P, pero utiliza un modelo de difusión diferente y el tamaño de la imagen es diferente en el nodo WanImageToVideo
Descarga la siguiente imagen como imagen de entrada

2.2 Descarga manual del modelo
Si el archivo de flujo de trabajo anterior no completa la descarga del modelo, descarga los siguientes archivos de modelo y guárdalos en las ubicaciones correspondientes.
Diffusion models
720P 版本
- wan2.1_i2v_720p_14B_bf16.safetensors
- wan2.1_i2v_720p_14B_fp16.safetensors
- wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_720p_14B_fp8_scaled.safetensors
480P 版本
- wan2.1_i2v_480p_14B_bf16.safetensors
- wan2.1_i2v_480p_14B_fp16.safetensors
- wan2.1_i2v_480p_14B_fp8_e4m3fn.safetensors
- wan2.1_i2v_480p_14B_fp8_scaled.safetensors
Text encoders
VAE
CLIP Vision
Ubicación para guardar los archivos
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1_i2v_480p_14B_fp16.safetensors # o la versión que hayas seleccionado
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # o la versión que hayas seleccionado
│ └── vae/
│ │ └── wan_2.1_vae.safetensors
│ └── clip_vision/
│ └── clip_vision_h.safetensors2.3 Ejecución del flujo de trabajo de imagen a video Wan2.1 480P
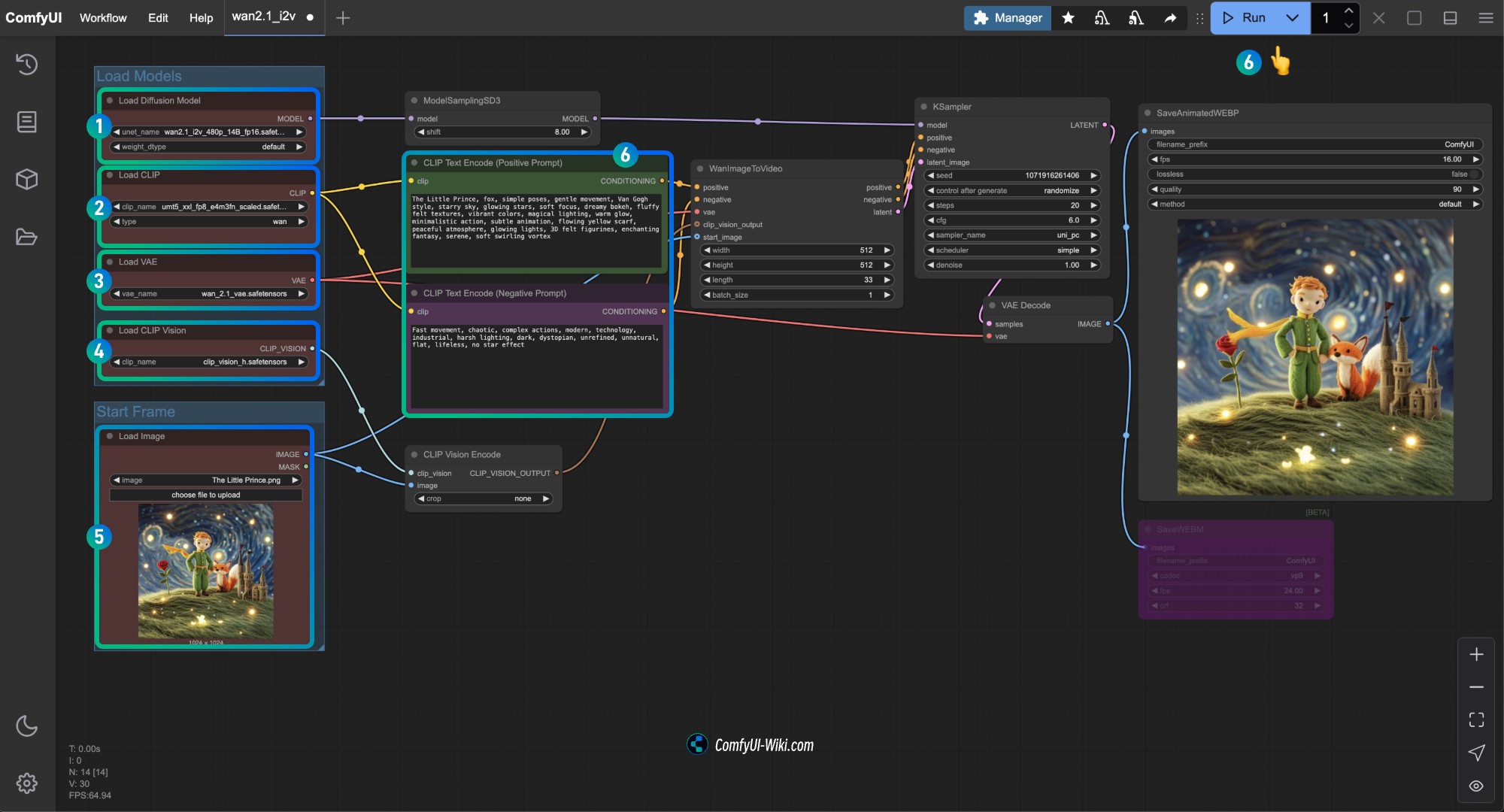
- Asegúrate de que el nodo
Load Diffusion Modelhaya cargado el modelowan2.1_i2v_480p_14B_fp16.safetensors - Asegúrate de que el nodo
Load CLIPhaya cargado el modeloumt5_xxl_fp8_e4m3fn_scaled.safetensors - Asegúrate de que el nodo
Load VAEhaya cargado el modelowan_2.1_vae.safetensors - Asegúrate de que el nodo
Load CLIP Visionhaya cargado el modeloclip_vision_h.safetensors - En el nodo
Load Image, carga la imagen de entrada proporcionada anteriormente - En el nodo
CLIP Text Encoder, ingresa el contenido de la descripción del video que deseas generar, o usa el ejemplo proporcionado en el flujo de trabajo - Haz clic en el botón
Run, o utiliza el atajoCtrl(cmd) + Enterpara ejecutar la generación del video
Flujo de trabajo de la versión cuantizada de Wan2.1 de Kijai
Esta versión está proporcionada por Kijai y requiere el uso de los siguientes nodos personalizados:
Necesitas instalar los siguientes nodos:
Antes de comenzar, instala los siguientes nodos personalizados usando ComfyUI-Manager o consulta el tutorial Instalación de nodos personalizados en ComfyUI para completar la instalación de estos tres nodos personalizados.
Repositorio de modelos: Kijai/WanVideo_comfy
Este repositorio proporciona varios modelos de diferentes versiones, selecciona el modelo que mejor se adapte a tus necesidades según el rendimiento de tu dispositivo. Generalmente, los modelos de mayor tamaño proporcionan mejores resultados, pero también requieren más recursos de hardware.
1. Kijai 文生图工作流
1.1 Descarga del flujo de trabajo de Kijai Wan2.1
Haz clic en el siguiente botón para descargar el flujo de trabajo correspondiente y arrástralo a ComfyUI o usa la barra de menú Workflows -> Open(Ctrl+O) para cargar el flujo de trabajo
Los dos archivos de flujo de trabajo son esencialmente iguales, el archivo 2 tiene información opcional adicional
1.2 Instalación manual del modelo
Diffusion models
- Wan2_1-T2V-14B_fp8_e4m3fn.safetensors
- Wan2_1-T2V-14B_fp8_e5m2.safetensors
- Wan2_1-T2V-1_3B_fp32.safetensors
- Wan2_1-T2V-1_3B_bf16.safetensors
- Wan2_1-T2V-1_3B_fp8_e4m3fn.safetensors
Text encoders
VAE
Ubicación para guardar los archivos
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-T2V-14B_fp8_e4m3fn.safetensors # o la versión que hayas seleccionado
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # o la versión que hayas seleccionado
│ └─── vae/
│ └── Wan2_1_VAE_bf16.safetensors # o la versión que hayas seleccionado1.3 Ejecución del flujo de trabajo de Kijai Wan2.1
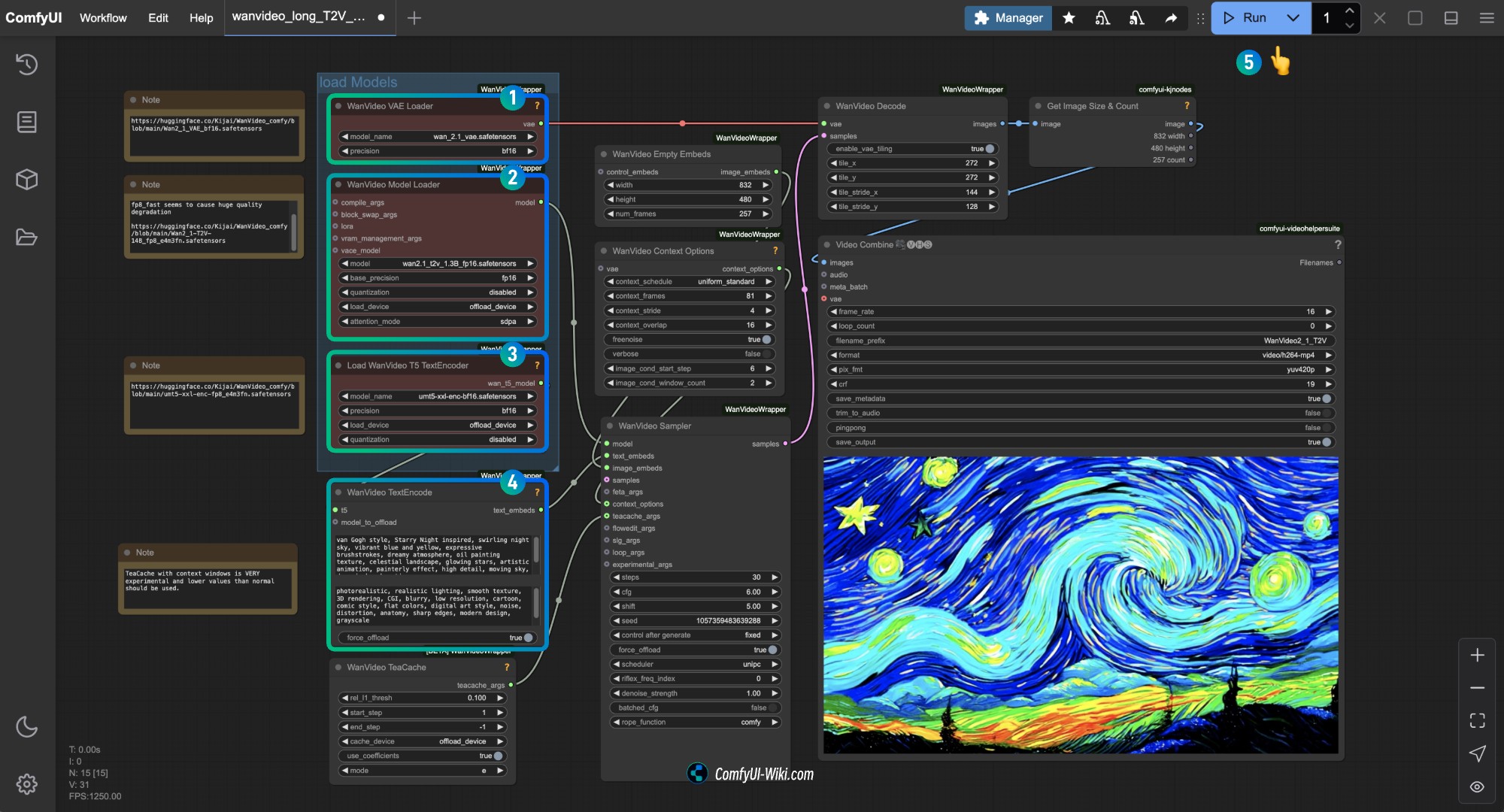
Asegúrate de que los nodos correspondientes hayan cargado los modelos correspondientes, usa la versión que descargaste
- Asegúrate de que el nodo
WanVideo Vae Loaderhaya cargado el modeloWan2_1_VAE_bf16.safetensors - Asegúrate de que el nodo
WanVideo Model Loaderhaya cargado el modeloWan2_1-T2V-14B_fp8_e4m3fn.safetensors - Asegúrate de que el nodo
Load WanVideo T5 TextEncoderhaya cargado el modeloumt5-xxl-enc-bf16.safetensors - En el nodo
WanVideo TextEncodeingresa el contenido de la descripción del video que deseas generar - Haz clic en el botón
Run, o utiliza el atajoCtrl(cmd) + Enterpara ejecutar la generación del video
Puedes modificar el tamaño en el nodo WanVideo Empty Embeds para cambiar el tamaño de la imagen
2. Flujo de trabajo de imagen a video de Kijai Wan2.1
2.1 Descarga del flujo de trabajo de imagen a video de Kijai Wan2.1
Descarga la siguiente imagen como imagen de entrada

2.2 Descarga manual del modelo
Diffusion models Versión 720P
Versión 480P
Text encoders
VAE
CLIP Vision
Ubicación para guardar los archivos
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── Wan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors # o la versión que hayas seleccionado
│ ├── text_encoders/
│ │ └─── umt5-xxl-enc-bf16.safetensors # o la versión que hayas seleccionado
│ ├── vae/
│ │ └── Wan2_1_VAE_fp32.safetensors # o la versión que hayas seleccionado
│ └── clip_vision/
│ └── clip_vision_h.safetensors2.3 Ejecución del flujo de trabajo de imagen a video de Kijai Wan2.1
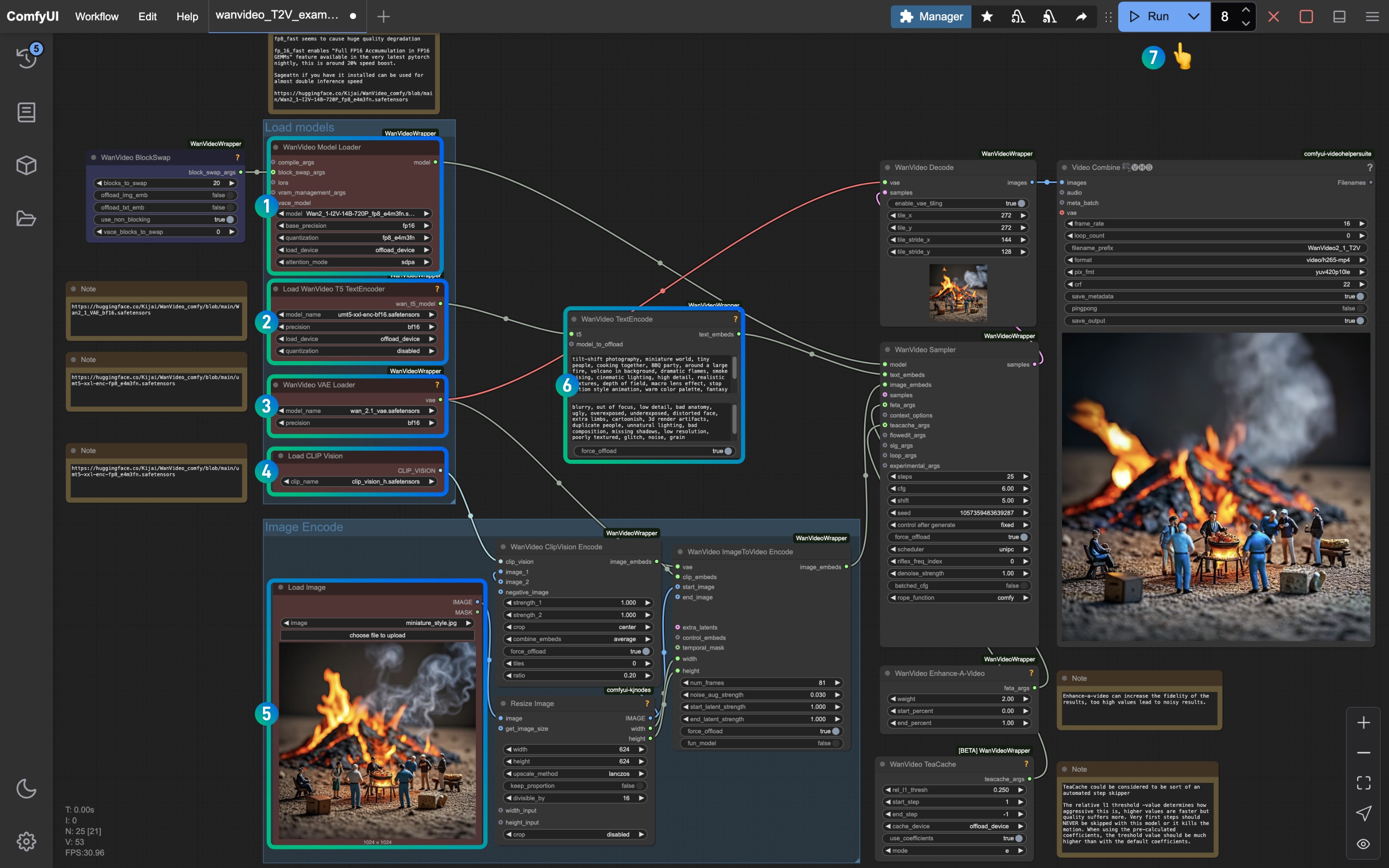
Referencia la imagen por número, asegúrate de que los nodos y modelos correspondientes hayan cargado para completar la generación del video
- Asegúrate de que el nodo
WanVideo Model Loaderhaya cargado el modeloWan2_1-I2V-14B-720P_fp8_e4m3fn.safetensors - Asegúrate de que el nodo
Load WanVideo T5 TextEncoderhaya cargado el modeloumt5-xxl-enc-bf16.safetensors - Asegúrate de que el nodo
WanVideo Vae Loaderhaya cargado el modeloWan2_1_VAE_fp32.safetensors - Asegúrate de que el nodo
Load CLIP Visionhaya cargado el modeloclip_vision_h.safetensors - En el nodo
Load Image, carga la imagen de entrada proporcionada anteriormente - Guarda el valor predeterminado o modifica el
WanVideo TextEncodepara ajustar el efecto de la imagen - Haz clic en el botón
Run, o utiliza el atajoCtrl(cmd) + Enterpara ejecutar la generación del video
Flujo de trabajo de la versión GGUF de Wan2.1
Esta parte usará el modelo GGUF para completar la generación de videos Repositorio de modelos: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
Necesitamos ComfyUI-GGUF para cargar el modelo correspondiente, antes de comenzar, instala el nodo correspondiente usando ComfyUI-Manager o consulta el tutorial Instalación de nodos personalizados en ComfyUI para completar la instalación del nodo correspondiente
1. Flujo de trabajo de la versión GGUF de Wan2.1
1.1 Descarga del flujo de trabajo de la versión GGUF de Wan2.1

1.2 Descarga manual del modelo
Selecciona un archivo de modelo Diffusion models para descargar, city96 proporciona varios modelos de diferentes versiones, visita https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main para descargar una versión adecuada para ti, generalmente, los modelos de mayor tamaño proporcionan mejores resultados, pero también requieren más recursos de hardware
Selecciona una versión de Text encoders para descargar,
VAE
Ubicación para guardar los archivos
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-t2v-14b-Q4_K_M.gguf # o la versión que hayas seleccionado
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # o la versión que hayas seleccionado
│ └── vae/
│ └── wan_2.1_vae.safetensors1.3 Ejecución del flujo de trabajo de la versión GGUF de Wan2.1
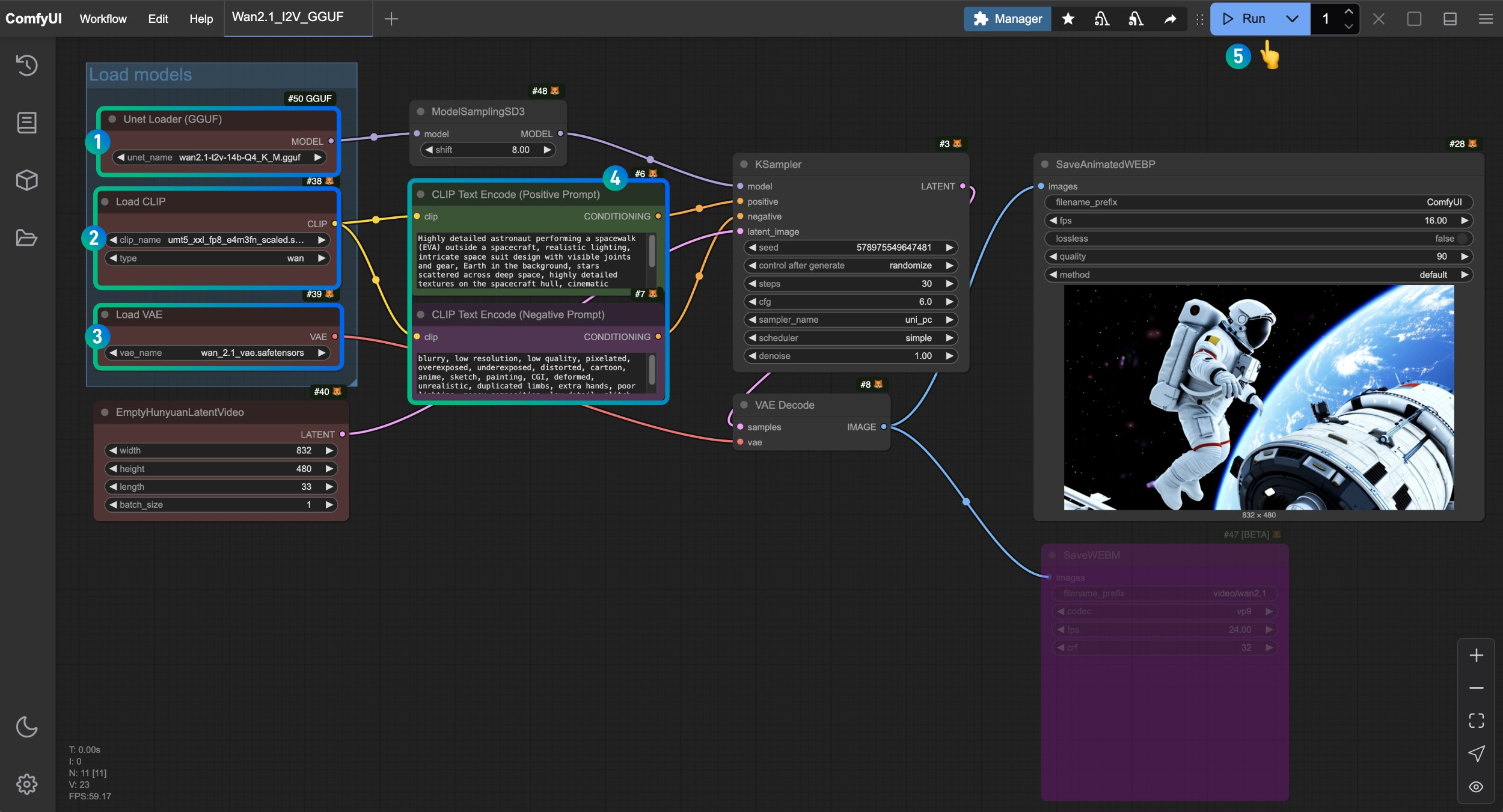
- Asegúrate de que el nodo
Unet Loader(GGUF)haya cargado el modelowan2.1-t2v-14b-Q4_K_M.gguf - Asegúrate de que el nodo
Load CLIPhaya cargado el modeloumt5_xxl_fp8_e4m3fn_scaled.safetensors - Asegúrate de que el nodo
Load VAEhaya cargado el modelowan_2.1_vae.safetensors - En el nodo
CLIP Text Encoderingresa el contenido de la descripción del video que deseas generar - Haz clic en el botón
Run, o utiliza el atajoCtrl(cmd) + Enterpara ejecutar la generación del video
2. Flujo de trabajo de la versión GGUF de Wan2.1
2.1 Descarga del flujo de trabajo de la versión GGUF de Wan2.1

2.2 Descarga manual del modelo
Selecciona un archivo de modelo Diffusion models para descargar, city96 proporciona varios modelos de diferentes versiones, visita https://huggingface.co/city96/Wan2.1-I2V-14B-gguf/tree/main para descargar una versión adecuada para ti, generalmente, los modelos de mayor tamaño proporcionan mejores resultados, pero también requieren más recursos de hardware
Aquí uso el modelo wan2.1-i2v-14b-Q4_K_M.gguf para completar el ejemplo
Selecciona una versión de Text encoders para descargar,
VAE
Ubicación para guardar los archivos
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── wan2.1-i2v-14b-Q4_K_M.gguf # o la versión que hayas seleccionado
│ ├── text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors # o la versión que hayas seleccionado
│ └── vae/
│ └── wan_2.1_vae.safetensors2.3 Ejecución del flujo de trabajo de la versión GGUF de Wan2.1
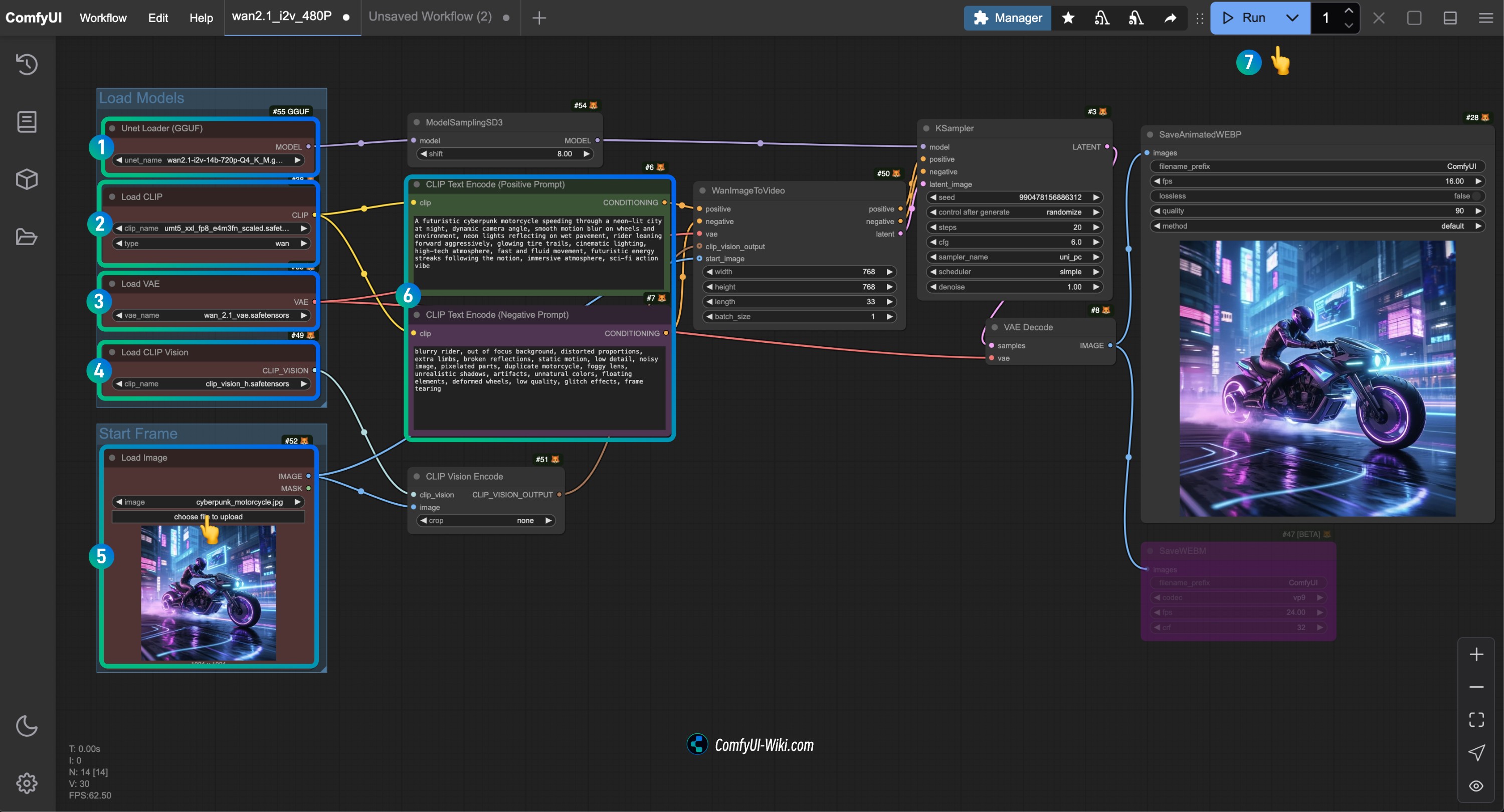
- Asegúrate de que el nodo
Unet Loader(GGUF)haya cargado el modelowan2.1-i2v-14b-Q4_K_M.gguf - Asegúrate de que el nodo
Load CLIPhaya cargado el modeloumt5_xxl_fp8_e4m3fn_scaled.safetensors - Asegúrate de que el nodo
Load VAEhaya cargado el modelowan_2.1_vae.safetensors - Asegúrate de que el nodo
Load CLIP Visionhaya cargado el modeloclip_vision_h.safetensors - En el nodo
Load Image, carga la imagen de entrada proporcionada anteriormente - En el nodo
CLIP Text Encoder, ingresa el contenido de la descripción del video que deseas generar, o usa el ejemplo proporcionado en el flujo de trabajo - Haz clic en el botón
Run, o utiliza el atajoCtrl(cmd) + Enterpara ejecutar la generación del video
Preguntas frecuentes
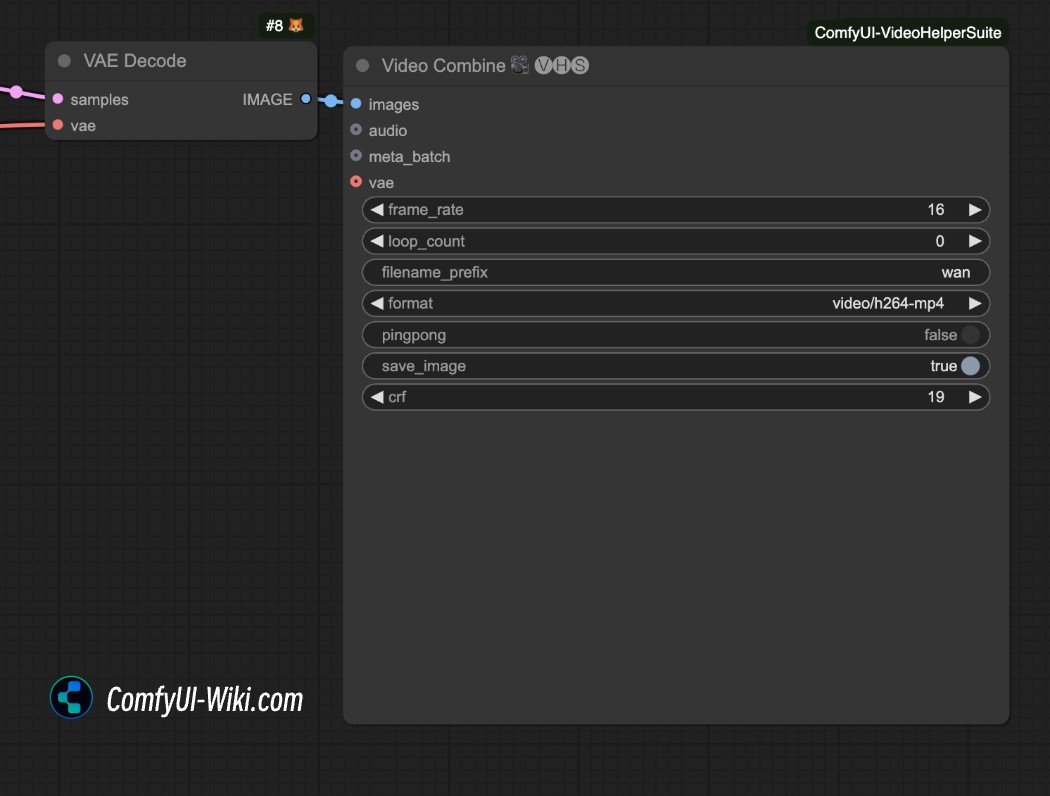
¿Cómo guardar el video en formato mp4?
El flujo de trabajo de generación de video anterior genera videos en formato .webp de forma predeterminada. Si deseas guardar en otro formato, puedes intentar usar el nodo video Combine del complemento ComfyUI-VideoHelperSuite para guardar el video en formato mp4.
Recursos relacionados
Todos los modelos están disponibles para descarga en Hugging Face y ModelScope:
-
T2V-14B:Hugging Face | ModelScope
-
I2V-14B-720P:Hugging Face | ModelScope
-
T2V-1.3B:Hugging Face | ModelScope
Comentarios
Inicia sesión con GitHub para unirte a la conversación.