Tutorial Completo Paso a Paso del Flujo de Trabajo Frame Pack en ComfyUI
Este tutorial te guiará sobre cómo usar el flujo de trabajo Frame Pack en ComfyUI, proporcionando instrucciones detalladas paso a paso.
FramePack es una tecnología de generación de vídeo con IA desarrollada por el equipo del Dr. Lvmin Zhang de la Universidad de Stanford, autor de ControlNet. Sus principales características incluyen:
- Compresión Dinámica de Contexto: Al clasificar los fotogramas del vídeo según su importancia, los fotogramas clave conservan 1536 marcadores de características, mientras que los fotogramas de transición se simplifican a 192.
- Muestreo Resistente a la Deriva: Utiliza métodos de memoria bidireccional y técnicas de generación inversa para evitar la deriva de la imagen y garantizar la continuidad de la acción.
- Requisitos Reducidos de VRAM: Reduciendo el umbral de VRAM para la generación de vídeo desde hardware de grado profesional (12GB+) a nivel de consumidor (solo 6GB VRAM), permitiendo a usuarios comunes con un portátil RTX 3060 generar vídeos de alta calidad de hasta 60 segundos de duración.
- Código Abierto e Integración: FramePack está actualmente en código abierto e integrado en el modelo de vídeo Hunyuan de Tencent, soportando entradas multimodales (texto + imágenes + voz) y generación interactiva en tiempo real.
Enlaces Originales Relacionados con Frame Pack
- Repositorio Original: https://github.com/lllyasviel/FramePack/
- Paquete de integración con un solo clic para Windows sin ComfyUI: https://github.com/lllyasviel/FramePack/releases/tag/windows
Prompt Correspondiente
lllyasviel proporciona un prompt de GPT para la generación de vídeos en el repositorio correspondiente. Si no estás seguro de cómo escribir prompts mientras usas el flujo de trabajo Frame Pack, puedes probar lo siguiente:
- Copia el prompt a continuación y envíalo a GPT.
- Una vez que GPT entienda los requisitos, proporciónale las imágenes correspondientes y recibirás los prompts adecuados.
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.Implementación Actual de Frame Pack en ComfyUI
Actualmente, hay tres autores de nodos personalizados que han implementado capacidades de Frame Pack en ComfyUI:
- Kijai: ComfyUI-FramePackWrapper
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
Diferencias Entre Estos Nodos Personalizados
A continuación explicamos las diferencias en los flujos de trabajo implementados por estos nodos personalizados.
Plugin Personalizado de Kijai
Kijai ha reempaquetado los modelos correspondientes, y creo que has utilizado los nodos personalizados relacionados de Kijai, ¡gracias a él por traer actualizaciones tan rápidas!
Parece que la versión de Kijai no está registrada en el ComfyUI Manager, por lo que actualmente no se puede instalar a través del Administrador de Nodos Personalizados del Manager. Necesitas instalarlo a través del Git del Manager o manualmente.
Características:
- Soporta generación de vídeo con primeros y últimos fotogramas
- Requiere instalación vía Git o instalación manual
- Los modelos son reutilizables
Plugins Personalizados de HM-RunningHub y TTPlanetPig
Estos dos nodos personalizados son versiones modificadas basadas en el mismo código, originalmente creado por HM-RunningHub, y luego TTPlanetPig implementó la generación de vídeo con primeros y últimos fotogramas basándose en el código fuente del plugin correspondiente. Puedes consultar este PR.
La estructura de carpetas de los modelos utilizados por estos dos nodos personalizados es consistente, ambos utilizando los archivos de modelo del repositorio original que no han sido reempaquetados. Por lo tanto, estos archivos de modelo no pueden ser utilizados en otros nodos personalizados que no soporten esta estructura de carpetas, lo que lleva a un mayor uso de espacio en disco.
Características:
- Soporta generación de vídeo con primeros y últimos fotogramas
- Los archivos de modelo descargados pueden no ser reutilizables en otros nodos o flujos de trabajo
- Ocupa más espacio en disco porque los archivos de modelo no están reempaquetados
- Algunos problemas de compatibilidad con dependencias
Flujo de Trabajo ComfyUI de Kijai ComfyUI-FramePackWrapper FLF2V
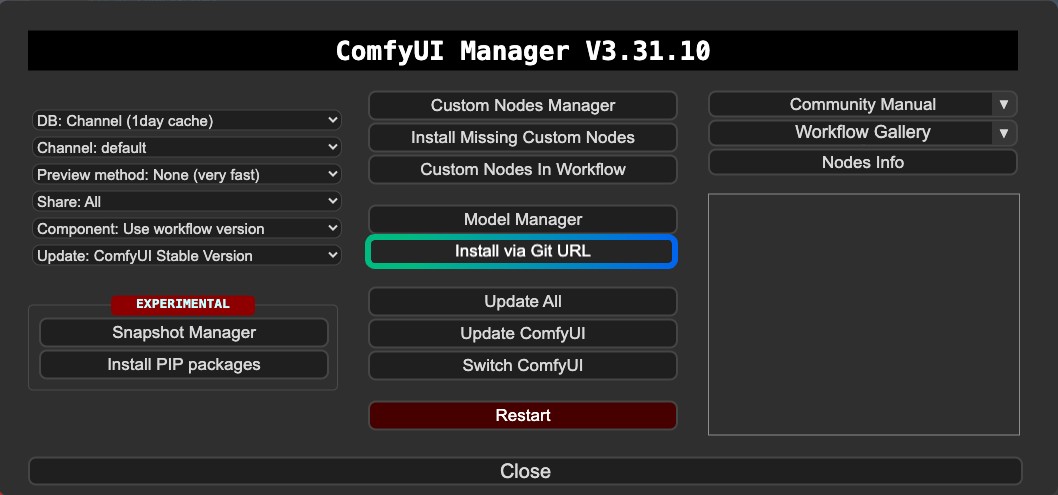
1. Instalación del Plugin
Para ComfyUI-FramePackWrapper, es posible que necesites instalarlo usando el Git del Manager:
Aquí hay algunos artículos que podrían serte útiles:
- Cómo instalar nodos personalizados
- Resolución del problema "Esta acción no está permitida con esta configuración de nivel de seguridad"
2. Descarga del Archivo de Flujo de Trabajo
Descarga el archivo de vídeo a continuación y arrástralo a ComfyUI para cargar el flujo de trabajo correspondiente. He añadido la información del modelo en el archivo, que te pedirá que descargues el modelo.
Vista Previa del Vídeo
Descarga las imágenes a continuación, que usaremos como entradas de imagen.


3. Instalación Manual del Modelo
Si no puedes descargar con éxito los modelos en el flujo de trabajo, descarga los modelos a continuación y guárdalos en la ubicación correspondiente.
CLIP Vision
VAE
Codificador de Texto
Modelo de Difusión Kijai proporciona dos versiones con diferentes precisiones. Puedes elegir una para descargar según el rendimiento de tu tarjeta gráfica.
| Nombre del Archivo | Precisión | Tamaño | Enlace de Descarga | Requisito de Tarjeta Gráfica |
|---|---|---|---|---|
| FramePackI2V_HY_bf16.safetensors | bf16 | 25.7GB | Enlace de Descarga | Alto |
| FramePackI2V_HY_fp8_e4m3fn.safetensors | fp8 | 16.3GB | Enlace de Descarga | Bajo |
Ubicación de Guardado de Archivos
📂 ComfyUI/
├──📂 models/
│ ├──📂 diffusion_models/
│ │ └── FramePackI2V_HY_fp8_e4m3fn.safetensors # or bf16 precision
│ ├──📂 text_encoders/
│ │ ├─── clip_l.safetensors
│ │ └─── llava_llama3_fp16.safetensors
│ ├──📂 clip_vision/
│ │ └── sigclip_vision_patch14_384.safetensors
│ └──📂 vae/
│ └── hunyuan_video_vae_bf16.safetensors4. Completar el flujo de trabajo correspondiente paso a paso
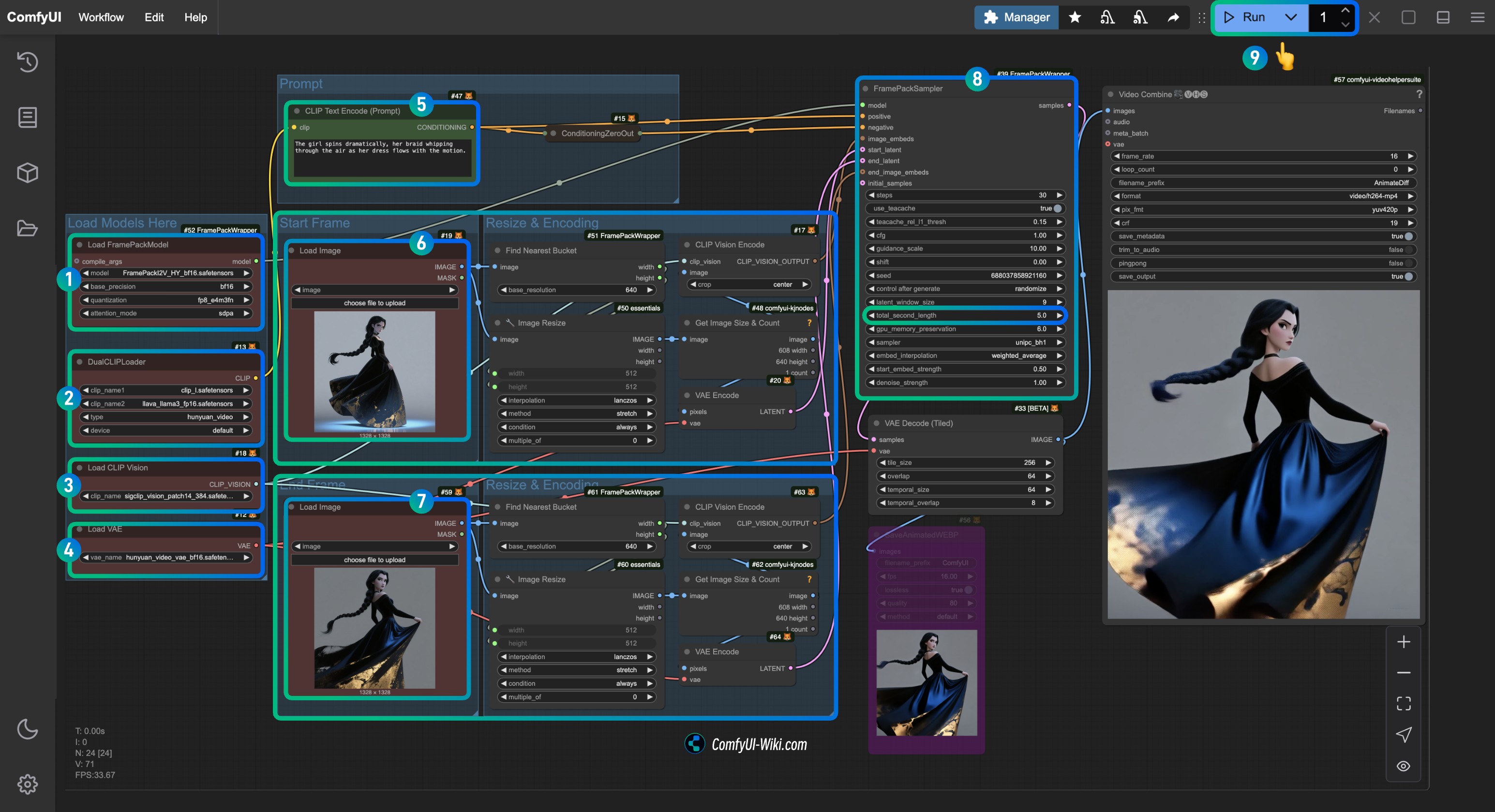
- Asegúrate de que el nodo
Load FramePackModelhaya cargado el modeloFramePackI2V_HY_fp8_e4m3fn.safetensors. - Asegúrate de que el nodo
DualCLIPLoaderhaya cargado:- El modelo
clip_l.safetensors - El modelo
llava_llama3_fp16.safetensors
- El modelo
- Asegúrate de que el nodo
Load CLIP Visionhaya cargado el modelosigclip_vision_patch14_384.safetensors. - Puedes cargar el modelo
hunyuan_video_vae_bf16.safetensorsen el nodoLoad VAE. - (Opcional, si usas mis imágenes de entrada) Modifica el parámetro
Prompten el nodoCLIP Text Encoderpara introducir la descripción del vídeo que quieres generar. - En el nodo
Load Image, cargafirst_frame.jpg, que está relacionado con el procesamiento de entrada defirst_frame. - En el nodo
Load Image, cargalast_frame.jpg, que está relacionado con el procesamiento de entrada delast_frame(si no necesitas el último fotograma, puedes eliminarlo o usar Bypass para desactivarlo). - En el nodo
FramePackSampler, puedes modificar el parámetrototal_second_lengthpara cambiar la duración del vídeo; en mi flujo de trabajo, está configurado en5segundos, y puedes ajustarlo según tus necesidades. - Haz clic en el botón
Runo usa el atajoCtrl(cmd) + Enterpara ejecutar la generación de vídeo.
Si no necesitas el último fotograma, omite todo el procesamiento de entrada relacionado con last_frame.
Detalles de los plugins de HM-RunningHub y TTPlanetPig
Estos dos plugins utilizan la misma ubicación de almacenamiento de modelos, pero como mencioné anteriormente, descargan todo el repositorio original, que debe guardarse en una ubicación específica. Esto impide que otros plugins reutilicen estos modelos, lo que lleva a cierto desperdicio de espacio en disco. Sin embargo, implementan la generación de primeros y últimos fotogramas, así que puedes probarlos si quieres.
list index out of range. Puedes consultar este issue. Actualmente, se ha discutido que la posible situación es:
"La versión de torchvision que estás usando probablemente no sea compatible con la versión de PyAV que tienes instalada."
Sin embargo, después de probar los métodos mencionados en el issue, todavía no pude resolver el problema. Por lo tanto, solo puedo proporcionar la información tutorial relevante aquí. Si logras resolver el problema, no dudes en proporcionar comentarios. Recomiendo revisar este issue para ver si alguien ha propuesto soluciones similares.
Instalación del Plugin
- Puedes elegir instalar uno de los siguientes o ambos; los nodos difieren, pero ambos son simples de usar con solo un nodo:
- HM-RunningHub: ComfyUI_RH_FramePack
- TTPlanetPig: TTP_Comfyui_FramePack_SE
- Mejora la experiencia de edición de vídeo en ComfyUI:
Si has utilizado VideoHelperSuite para flujos de trabajo relacionados con vídeos, sigue siendo crucial para expandir las capacidades de vídeo de ComfyUI.
1. Descarga de Modelos
HM-RunningHub proporciona un script de Python para descargar todos los modelos. Solo necesitas ejecutar este script y seguir las indicaciones. Mi enfoque es guardar el código a continuación como download_models.py y colocarlo en el directorio raíz de ComfyUI/models, luego ejecutar python download_models.py en la terminal desde el directorio correspondiente.
cd <your installation path>/ComfyUI/models/Luego ejecuta el script:
python download_models.pyEsto requiere que tu entorno independiente de Python / entorno del sistema tenga instalado el paquete huggingface_hub.
from huggingface_hub import snapshot_download
# Download HunyuanVideo model
snapshot_download(
repo_id="hunyuanvideo-community/HunyuanVideo",
local_dir="HunyuanVideo",
ignore_patterns=["transformer/*", "*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download flux_redux_bfl model
snapshot_download(
repo_id="lllyasviel/flux_redux_bfl",
local_dir="flux_redux_bfl",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)
# Download FramePackI2V_HY model
snapshot_download(
repo_id="lllyasviel/FramePackI2V_HY",
local_dir="FramePackI2V_HY",
ignore_patterns=["*.git*", "*.log*", "*.md"],
local_dir_use_symlinks=False
)También puedes descargar manualmente los modelos a continuación y guardarlos en la ubicación correspondiente, lo que significa descargar todos los archivos del repositorio correspondiente.
- HunyuanVideo: Enlace de HuggingFace
- Flux Redux BFL: Enlace de HuggingFace
- FramePackI2V: Enlace de HuggingFace
Ubicación de Guardado de Archivos
comfyui/models/
flux_redux_bfl
├── feature_extractor
│ └── preprocessor_config.json
├── image_embedder
│ ├── config.json
│ └── diffusion_pytorch_model.safetensors
├── image_encoder
│ ├── config.json
│ └── model.safetensors
├── model_index.json
└── README.md
FramePackI2V_HY
├── config.json
├── diffusion_pytorch_model-00001-of-00003.safetensors
├── diffusion_pytorch_model-00002-of-00003.safetensors
├── diffusion_pytorch_model-00003-of-00003.safetensors
├── diffusion_pytorch_model.safetensors.index.json
└── README.md
HunyuanVideo
├── config.json
├── model_index.json
├── README.md
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ ├── model-00001-of-00004.safetensors
│ ├── model-00002-of-00004.safetensors
│ ├── model-00003-of-00004.safetensors
│ ├── model-00004-of-00004.safetensors
│ └── model.safetensors.index.json
├── text_encoder_2
│ ├── config.json
│ └── model.safetensors
├── tokenizer
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── tokenizer.json
├── tokenizer_2
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
└── vae
├── config.json
└── diffusion_pytorch_model.safetensors2. Descarga de Flujo de Trabajo
HM-RunningHub
TTPlanetPig
