Wan2.2-S2V 오디오 기반 비디오 생성 ComfyUI 워크플로우 및 튜토리얼
ComfyUI에서 Wan2.2-S2V로 자연스러운 립싱크 토킹 아바타 영상 생성. 모델 설정, S2V 파이프라인, 워크플로우 구성 예제 포함.
Wan2.2-S2V는 정적 이미지와 오디오 입력으로부터 동적 비디오 콘텐츠를 생성할 수 있는 AI 비디오 생성 기술의 획기적인 발전을 나타냅니다. 이 혁신적인 모델은 자연스러운 입형 동기화를 갖춘 동기화된 비디오를 생성하는 데 뛰어나, 대화 장면, 음악 공연 및 캐릭터 중심 내러티브에 종사하는 콘텐츠 제작자들에게 특히 가치가 있습니다.
모델 주요 특징
- 오디오 기반 비디오 생성: 정적 이미지와 오디오를 자연스러운 입형 및 표정이 있는 동기화된 비디오로 변환
- 영화급 품질: 진실한 얼굴 표정, 신체 동작 및 카메라 언어를 갖춘 영화 품질의 비디오 생성
- 분 단위 생성: 단일 생성으로 분 단위 길이의 장편 비디오 제작 지원
- 다중 형식 지원: 실제 인물, 만화, 동물, 디지털 휴먼에 작동하며, 인물, 반신 및 전신 형식 지원
- 향상된 모션 제어: AdaIN 및 CrossAttention 제어 메커니즘으로 텍스트 지시사항에서 동작 및 환경 생성
- 고성능 지표: 우수한 비디오 품질 및 아이덴티티 일관성을 위한 FID 15.66, CSIM 0.677, SSIM 0.734 달성
Wan2.2 S2V ComfyUI 네이티브 워크플로우
1. 워크플로우 파일 다운로드
다음 워크플로우 파일을 다운로드하고 ComfyUI로 드래그하여 워크플로우를 로드합니다.
<video controls className="w-full aspect-video" src="https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/video/wan/wan2.2_s2v/wan2.2-s2v.mp4"
입력으로 다음 이미지와 오디오를 다운로드하세요:

2. 모델 링크
우리 저장소에서 모델을 찾을 수 있습니다
diffusion_models
audio_encoders
vae
text_encoders
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── wan2.2_s2v_14B_fp8_scaled.safetensors
│ │ └─── wan2.2_s2v_14B_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ ├───📂 audio_encoders/ # 이 폴더를 찾을 수 없는 경우 새로 생성하세요
│ │ └─── wav2vec2_large_english_fp16.safetensors
│ └───📂 vae/
│ └── wan_2.1_vae.safetensors3. 워크플로우 지침
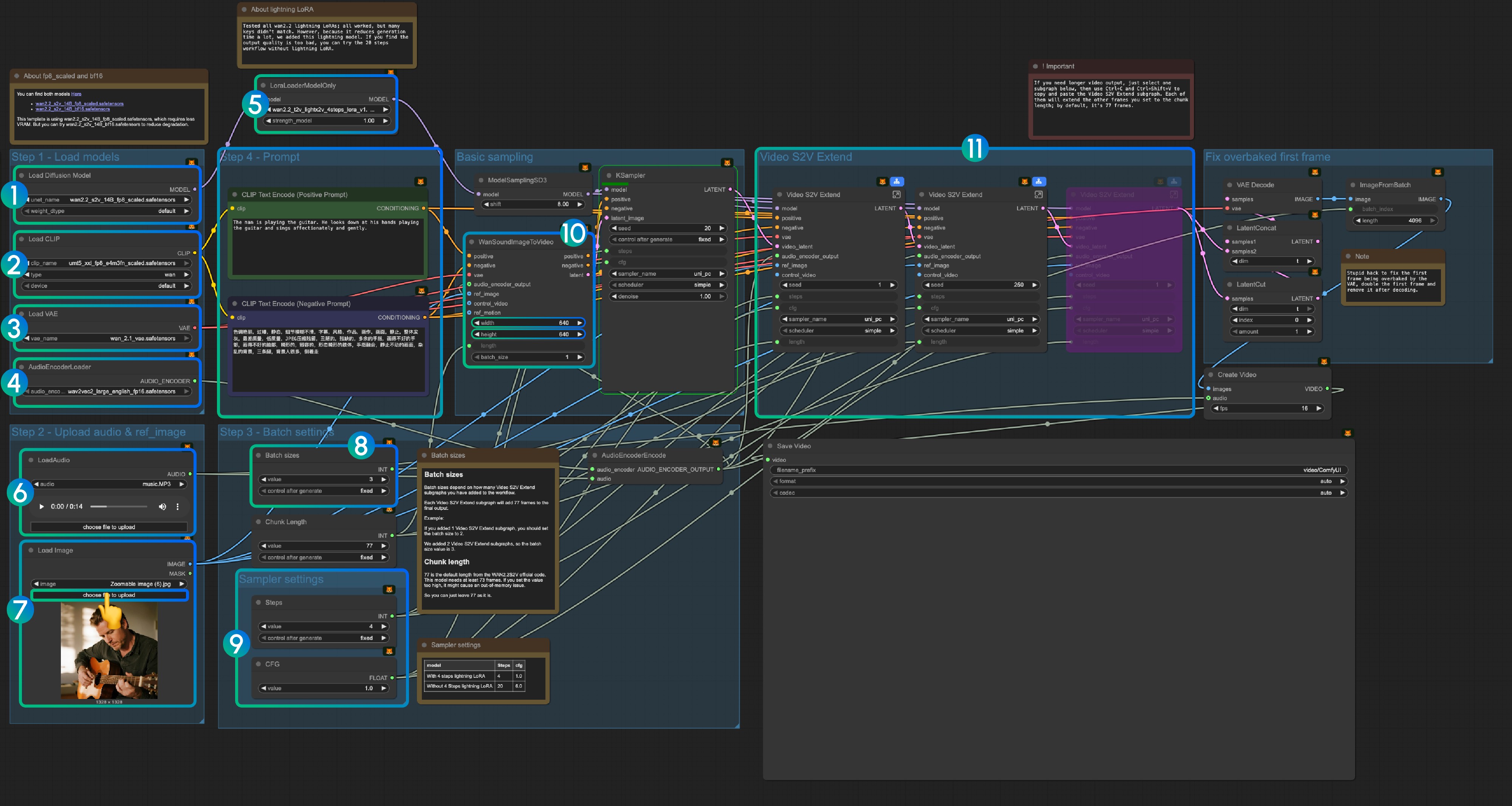
3.1 Lightning LoRA(선택사항, 가속화용)
Lightning LoRA는 생성 시간을 20단계에서 4단계로 줄이지만 품질에 영향을 줄 수 있습니다. 빠른 미리보기에 사용하고, 최종 출력에는 비활성화하세요.
3.1.1 오디오 전처리 팁
더 나은 결과를 위한 보컬 분리: ComfyUI 코어에는 보컬 분리 노드가 포함되어 있지 않으므로, 처리하기 전에 외부 도구를 사용하여 배경 음악과 보컬을 분리하는 것을 권장합니다. 이는 특히 대화 및 입형 생성에 중요하며, 깨끗한 보컬 트랙이 배경 음악이나 노이즈가 섞인 오디오보다 훨씬 더 나은 결과를 생성합니다.
3.2 fp8_scaled 및 bf16 모델에 대하여
두 모델은 여기에서 찾을 수 있습니다:
템플릿은 VRAM 사용량을 줄이기 위해 wan2.2_s2v_14B_fp8_scaled.safetensors를 사용합니다. 더 나은 품질을 위해 wan2.2_s2v_14B_bf16.safetensors를 시도해보세요.
3.3 단계별 운영 지침
1단계: 모델 로드
- 확산 모델 로드:
wan2.2_s2v_14B_fp8_scaled.safetensors또는wan2.2_s2v_14B_bf16.safetensors로드- 워크플로우는 VRAM 요구사항을 줄이기 위해
wan2.2_s2v_14B_fp8_scaled.safetensors를 사용 - 더 나은 품질의 출력을 위해
wan2.2_s2v_14B_bf16.safetensors사용
- 워크플로우는 VRAM 요구사항을 줄이기 위해
- CLIP 로드:
umt5_xxl_fp8_e4m3fn_scaled.safetensors로드 - VAE 로드:
wan_2.1_vae.safetensors로드 - AudioEncoderLoader:
wav2vec2_large_english_fp16.safetensors로드 - LoraLoaderModelOnly:
wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors로드 (Lightning LoRA)- 이 LoRA는 생성 시간을 줄이지만 품질에 영향을 줄 수 있음
- 출력 품질이 불충분한 경우 비활성화
- LoadAudio: 제공된 오디오 파일 또는 자체 오디오 업로드
- Load Image: 참조 이미지 업로드
- 배치 크기: Video S2V Extend 하위 그래프 노드 수에 따라 설정
- 각 Video S2V Extend 하위 그래프는 출력에 77프레임 추가
- 예: Video S2V Extend 하위 그래프 2개 = 배치 크기 3
- 청크 길이: 기본값 77 유지
- 샘플러 설정: Lightning LoRA 사용 여부에 따라 선택
- 4단계 Lightning LoRA 사용 시: steps: 4, cfg: 1.0
- Lightning LoRA 미사용 시: steps: 20, cfg: 6.0
- 크기 설정: 출력 비디오의 치수 설정
- Video S2V Extend: 비디오 확장 하위 그래프 노드
- 각 확장은 77 / 16 = 4.8125초의 비디오 생성
- 필요한 노드 계산: 오디오 길이(초) × 16 ÷ 77
- 예: 14초 오디오 = 224프레임 ÷ 77 = 확장 노드 3개
- Ctrl-Enter를 사용하거나 실행 버튼을 클릭하여 워크플로우 실행
관련 링크
- Wan2.2 S2V 코드: GitHub
- Wan2.2 S2V 모델: Hugging Face
댓글
GitHub로 로그인하고 토론에 참여하세요.